深入理解Hadoop读书笔记-1
背景
公司的物流业务系统目前实现了使用storm集群进行过门事件的实时计算处理,但是还有一个需求,我们需要存储每个标签上传的每条明细数据,然后进行定期的标签报表统计,这个是目前的实时计算框架无法满足的,需要考虑离线存储和计算引擎。
标签的数据量是巨大的,此时存储在mysql中是不合适的,所以我们考虑了分布式存储系统HDFS。目前考虑的架构是,把每条明细数据存储到HDFS中,利用Hive或者其他类SQL的解析引擎,定期进行离线统计计算。
查找相关资料后,我下载了深入理解Haddoop这本书,从大数据的一些基础原理开始调研,这一系列的笔记就是调研笔记。
深入理解Hadoop
大数据的核心处理思想
- 数据分布在多个节点并行处理
- 提高处理速度
- 同一个数据在不同节点有多份拷贝可以保持容错
- 计算程序尽量靠近数据
- 数据的处理尽量在本地完成
- 顺序IO代替随机IO
- 数据分布在多个节点并行处理
MapReduce的编程模型
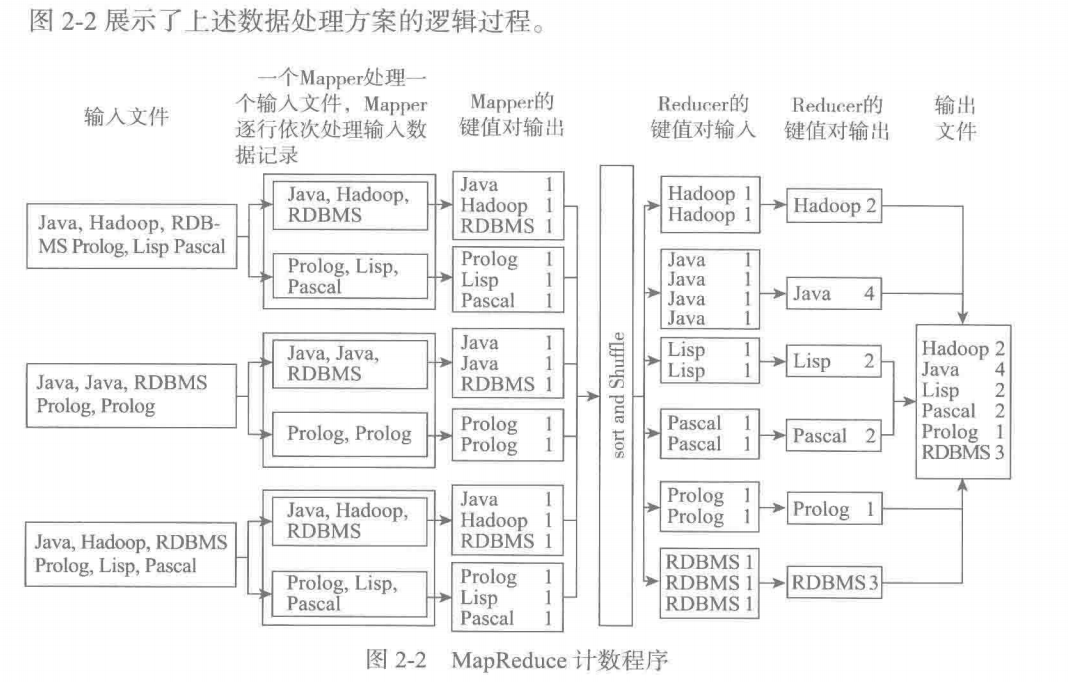
假设有海量的文档需要统计词频
- 每个mapper处理一个输入文件,逐行处理数据,生成键值对
- 排序键值对,根据reducer的个数,分发<key,lisy<值>>到不同的reducer处理(确保相同的key可以被分到同一个子集)
- reducer任务合并多个相同key中的list<值>数据,输出键值对,最后合并到文件
Hadoop1.X系统(守护进程)构成
NameNode:维护存储在HDFS上的所有文件的元数据信息,包括:数据块信息和数据块在节点的位置
Secondary NameNode:内务处理功能
Data Node:负责把真正的数据块存储在本地硬盘上
Job Tracker:调度子任务/监控任务和节点/失败子任务的重新调度
Task Tracker:运行在数据节点上,负责子任务的启动和管理
还可以按照主从节点来分类:
主节点
- NN SN JT
从节点
- DN TT
HDFS分布式文件系统为什么适合存储大文件而不适合存储大量的小文件?
HDFS中文件会被分成多个数据块,每个数据块默认有三个备份,NN默认把信息保存在本地磁盘中,为了加快访问,会存储在内存中。假设有1G的一个文件和1000个1MB的文件,数据块默认大小为64MB,总数据块的数量为 1024/64 * 3 = 48块 和 1000 * 3 = 3000块的差距。(同一个文件可以存储在同一个数据块在中,不同文件不能存储在同一个数据块)
辅助名称节点的工作原理(待完成)
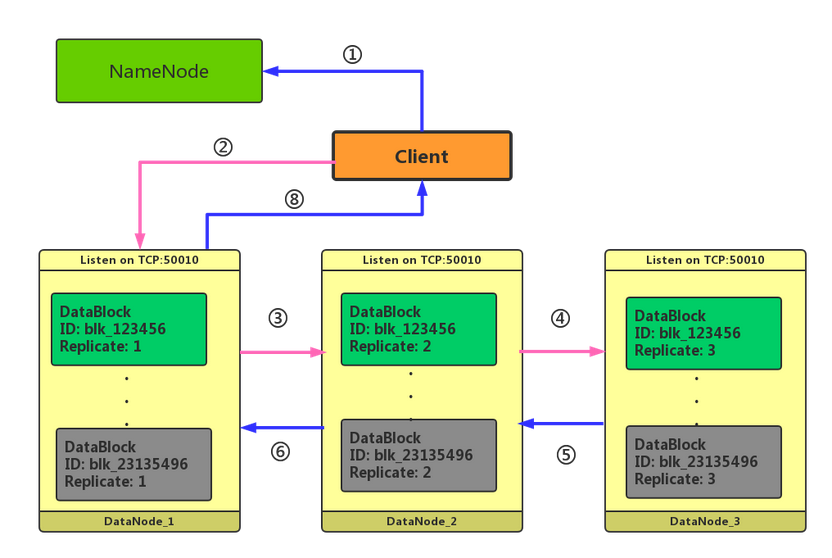
HDFS的写入过程你能简单说说吗?
客户端需要像NN请求写入,NN会检查是否有权限
客户端接收到允许写入后,开始准备数据,当数据大小为一个块时,会调用NN请求数据节点信息
NN创建文件,并生成块id,同时把数据节点相关的连接信息返回给客户端
客户端开始和节点1通信,等待节点1回复ACK
节点1存储数据,同时会与节点二通信,等待节点2返回ACK
节点3存储数据后,直接返回ACK
写入过程中存在哪些异常情况?
写入错误-成功备份的块数量小于设置的数量
当集群数量较小时,比如只有四台机器,如果默认开启三个数据块备份,那么当数据管道中有DN失败时,会去找其他健康的DN进行备份,假如两台DN都有问题,那么就无法满足最小3个数据块的备份需求。可以修改一个参数: dfs.client.block.write.replace-datanode-on-failure.enable 设置为false,表示如果在写入的pipeline有datanode失败的时候是否要切换到新的机器,默认为true。
待添加..
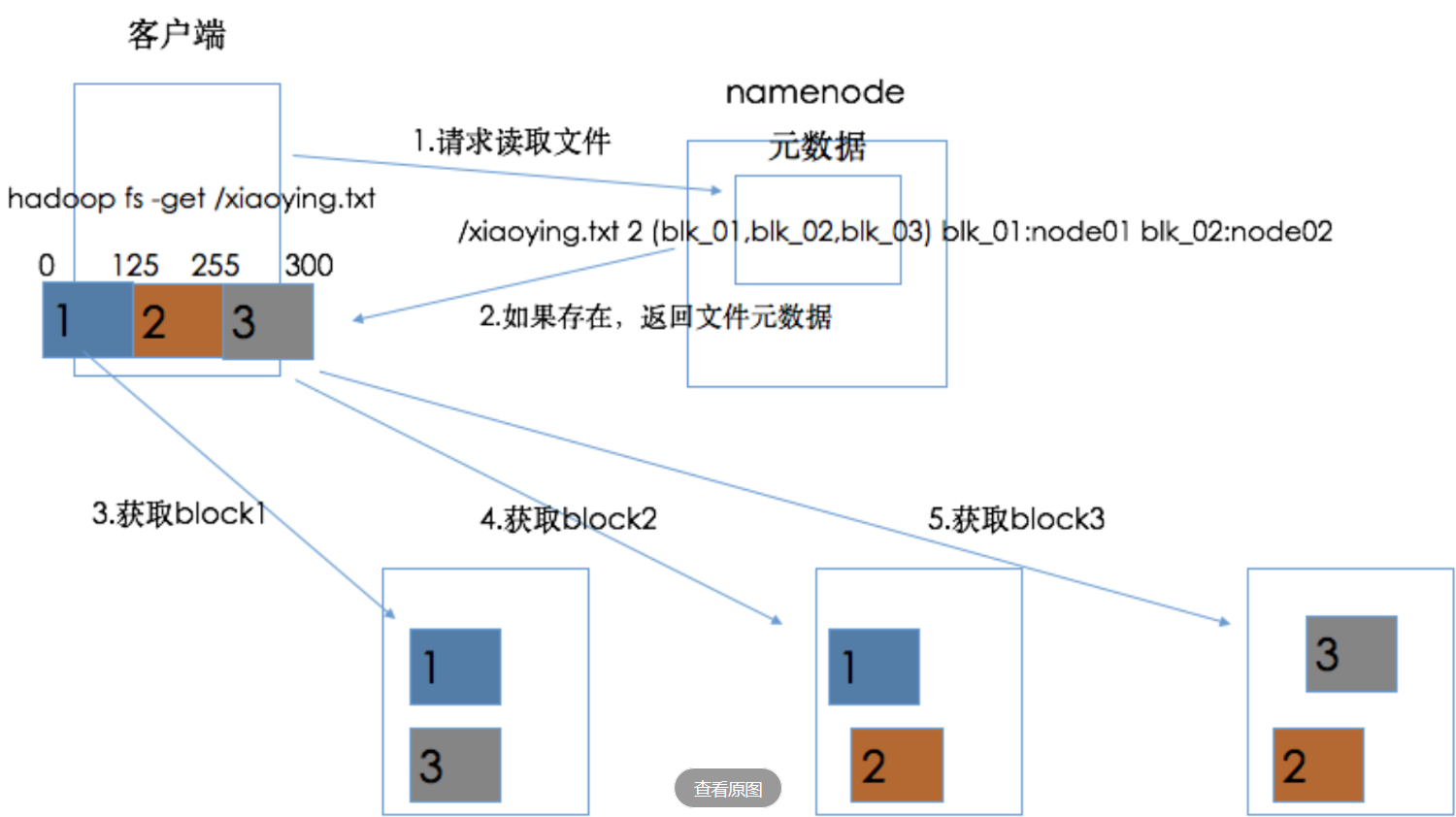
HDFS读文件机制
客户端请求NN读取文件
NN返回文件的元数据信息
客户端直接访问对应数据节点获取数据块即可
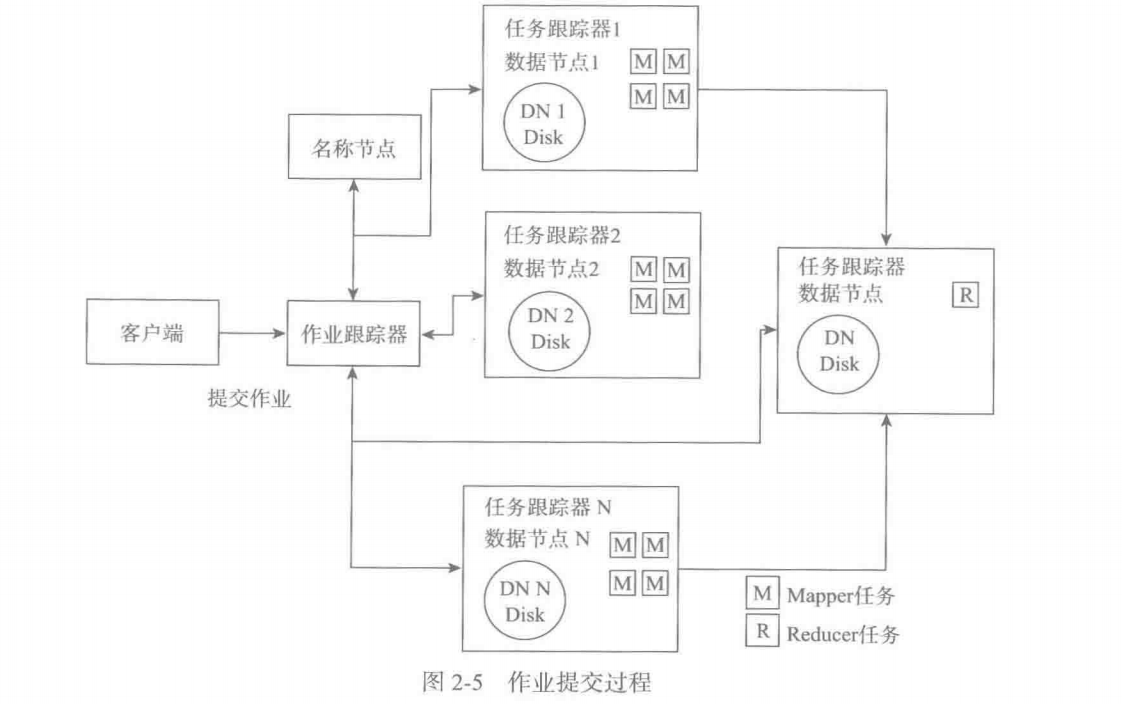
简单说说 任务跟踪器和作业跟踪器的工作原理,各自负责什么?
作业跟踪器负责接收客户端提交的任务,从名称节点获取输入文件的数据块信息,并采取数据就近原则把任务分配到 数据节点的任务跟踪器上。同时监控任务跟踪器的执行情况,在任务跟踪器节点故障时分配任务到其他的任务跟踪器节点。
任务跟踪器负责实际执行任务,并且定时汇报心跳信息给作业跟踪器。
Hadoop2.0中的Yarn都有什么组件?负责做什么?
- 全局资源管理器:负责全局的资源调度
- 节点管理器:负责具体节点的资源监控和资源分配
- 应用程序管理器:每种应用有不同的应用程序管理器,负责分析任务数量,向全局资源管理器申请资源,监控任务运行情况,重新调度任务。
- 容器:cpu和内存的抽象,任务和应用程序管理器都需要运行在容器中。
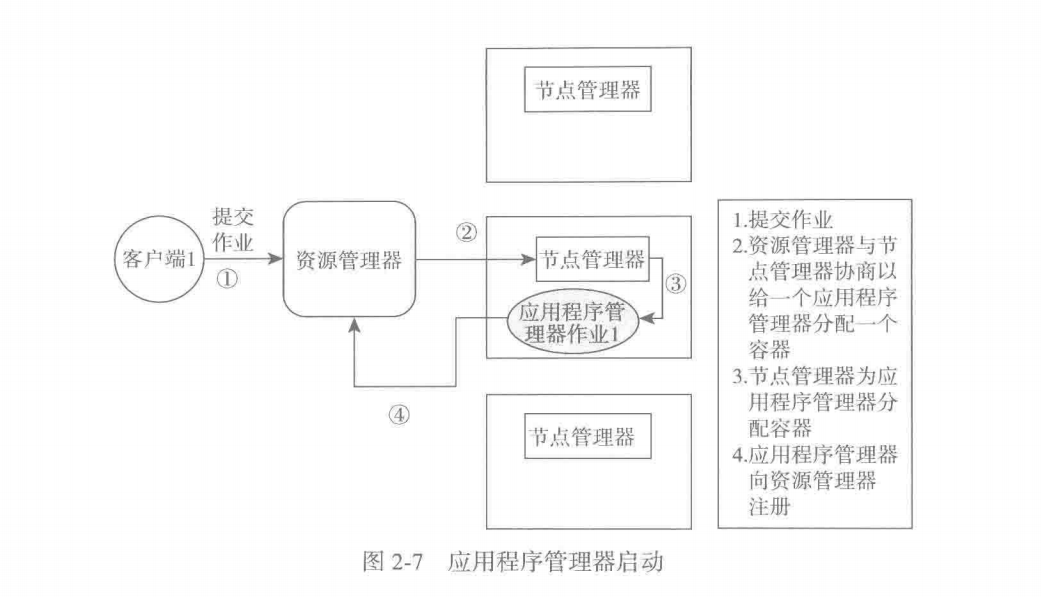
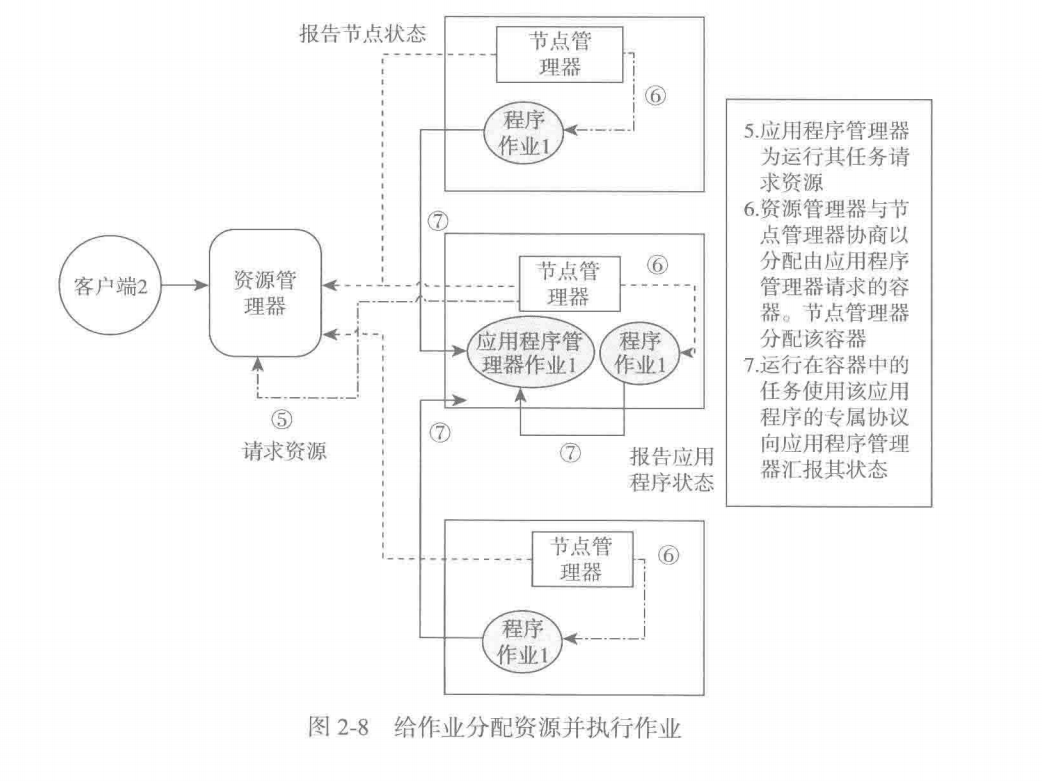
Yarn提交任务的执行流程
- 客户端提交作业
- 全局资源管理器判断作业的类型,通过节点管理器给应用程序管理器分配容器
- 应用程序管理器运行在容器中,同时像全局资源管理器注册自己,申请任务资源
- 全局资源管理器确定资源后,通过节点管理器分配任务所需容器
- 运行在容器中的任务,通过应用特定的协议像应用程序管理器上报状态
深入理解Hadoop读书笔记-1的更多相关文章
- Hadoop读书笔记(二)HDFS的shell操作
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 1.shell操作 1.1全部的HDFS ...
- Hadoop读书笔记(四)HDFS体系结构
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 Hadoop读书笔记(二)HDFS的sh ...
- java内存区域——深入理解JVM读书笔记
本内容由<深入理解java虚拟机>的部分读书笔记整理而成,本读者计划连载. 通过如下图和文字介绍来了解几个运行时数据区的概念. 方法区:它是各个线程共享的区域,用于内存已被VM加载的类信息 ...
- 00-深入理解C#读书笔记说明
带着问题去看书 尝试着,根据每一小节,先列出大纲.然后根据自己原先的认知和理解以及不理解,对每一个小的chapter,我会先自我提问,带着问题去阅读,然后把我的理解以及不理解记录下来,对于错误的地方做 ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
安装hive 1.下载hive-2.1.1(搭配hadoop版本为2.7.3) 2.解压到文件夹下 /wdcloud/app/hive-2.1.1 3.配置环境变量 4.在mysql上创建元数据库hi ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入HBASE
导入命令 sqoop import --connect jdbc:mysql://192.168.200.250:3306/sqoop --table widgets --hbase-create-t ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换
P573 从mysql导入数据到hdfs 第一步:在mysql中创建待导入的数据 1.创建数据库并允许所有用户访问该数据库 mysql -h 192.168.200.250 -u root -p CR ...
- [hadoop读书笔记] 第十章 管理Hadoop集群
P375 Hadoop管理工具 dfsadmin - 查询HDFS状态信息,管理HDFS. bin/hadoop dfsadmin -help 查询HDFS基本信息 fsck - 检查HDFS中文件的 ...
- [hadoop读书笔记] 第九章 构建Hadoop集群
P322 运行datanode和tasktracker的典型机器配置(2010年) 处理器:两个四核2-2.5GHz CPU 内存:16-46GN ECC RAM 磁盘存储器:4*1TB SATA 磁 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
随机推荐
- 【Java 温故而知新系列】基础知识-02 数据基本类型
1.Java基本数据类型 Java语言是强类型语言,对于每一种数据都定义了明确的具体的数据类型,在内存中分配了不同大小的内存空间. 基本数据类型 数值型:整数类型(byte,short,int,lon ...
- 查看Android是否开机启动进入桌面
adb 或者 串口终端 getprop sys.boot_completed 返回空代表没有进入桌面返回1代表已进入桌面
- CDS标准视图:总计应收款 I_TotalAccountsReceivables
视图名称:总计应收款 I_TotalAccountsReceivables 视图类型:参数 视图代码: 点击查看代码 @AbapCatalog.sqlViewName: 'IFITOTALACCTRB ...
- cpa-公司战略与风险管理
1.战略与战略管理 2.战略分析 3.战略选择 4.战略实战 5.公司治理 6.风险与风险管理
- html页面滚动时元素错位解决方案
一个布局较复杂的页面,在手机浏览器上运行时,部分配置比较差的手机会出现滚动滚动条后,页面正常滚动,但部分元素却出现类似position:fixed一般悬浮在页面上,然后再滚动.看上去有点像视差滚动,但 ...
- Java类加载机制与JVM运行时数据区各逻辑内存区域与JDK的版本相关差异浅谈
Java类加载机制与JVM运行时数据区各逻辑内存区域与JDK的版本相关差异浅谈 [摘要] JVM(Java Virtual Machine)作为Java研发人员工作的每天都会接触到的虚拟机,其运行机制 ...
- 反射:获取Class 类的实例(四种方法)
Class 类 对象照镜子后可以得到的信息:某个类的属性.方法和构造器.某个类到底实现了哪些接口.对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象.一个 Class 对象包含了 ...
- 为Delphi配置多套环境
假设我们使用Delphi6开发了一个投资系统,在开发过程中我们使用了indy控件.到目前为止投资系统已经发了若干个版本,如投资系统1.0.投资系统1.2.投资系统1.5.投资系统2.0.投资系统2.3 ...
- 再次使用layui遇见问题
Layui似乎只接收data里的数据,所以只能使用这个方式把原有数据放入dataparseData: function (res) { //res 即为原始返回的数据 return { "c ...
- Kali 切换中文模式
Kali 切换中文模式 在桌面打开终端,输入sudo dpkg-reconfigure locales命令,然后输入kali的密码 在选择栏目找到 zh_CN.UTF-8 UTF-8 找到之后按 空格 ...