Flink Catalog
概念
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的,例如 Hive Metastore 中的元数据。Catalog 提供了一个统一的API,用于管理元数据,并使其可以从 Table API 和 SQL 查询语句中来访问。
Catalog类型
- GenericInMemoryCatalog
基于内存实现,所有元数据只在 session 的生命周期内可用
- JdbcCatalog
可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog 和 MySQL Catalog 是目前 JDBC Catalog 仅有的两种实现
- HiveCatalog
作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口
- 用户自定义 Catalog
用户可以通过实现 Catalog 接口来开发自定义 Catalog,除了需要实现自定义的 Catalog 之外,还需要为这个 Catalog 实现对应的 CatalogFactory 接口
设计
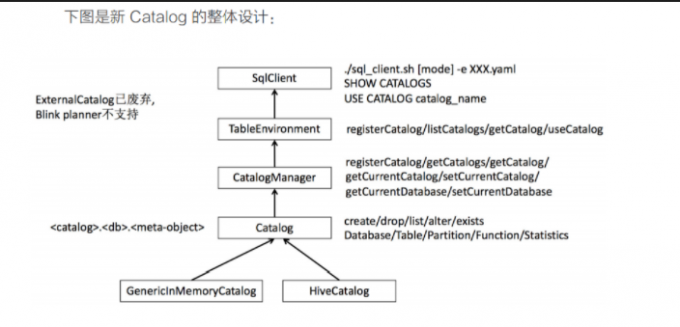
新的 Catalog 有三层结构,最顶层是 Catalog 的名字,中间一
层是 Database,最底层是各种 MetaObject,如 Table,Partition,Function 等
Catalog
- 支持 Create,Drop,List,Alter,Exists 等语句
- 支持对 Database,Table,View, Partition,Function,Statistics等的操作
CatalogManager 正如它名字一样,主要是用来管理 Catalog。
CatalogManager 支持的操作包括:
- 注册 Catalog(registerCatalog)
- 获取所有的 Catalog(getCatalogs)
- 获取特定的 Catalog(getCatalog)
- 获取当前的 Catalog(getCurrentCatalog)
- 设置当前的 Catalog(setCurrentCatalog)
- 获取当前的 Database(getCurrentDatabase)
- 设置当前的 Database(setCurrentDatabase)
参考
Flink Catalog的更多相关文章
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- 如何跑通第一个 SQL 作业
简介: 本文由阿里巴巴技术专家周凯波(宝牛)分享,主要介绍如何跑通第一个SQL. 一.SQL的基本概念 1.SQL 分类 SQL分为四类,分别是数据查询语言(DQL).数据操纵语言(DML).数据定义 ...
- 【翻译】Flink Table Api & SQL — Catalog Beta 版
本文翻译自官网:Catalogs Beta https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/catalog ...
- Stream Processing for Everyone with SQL and Apache Flink
Where did we come from? With the 0.9.0-milestone1 release, Apache Flink added an API to process rela ...
- Flink table&Sql中使用Calcite
Apache Calcite是什么东东 Apache Calcite面向Hadoop新的sql引擎,它提供了标准的SQL语言.多种查询优化和连接各种数据源的能力.除此之外,Calcite还提供了OLA ...
- Flink UDF
本文会主要讲三种udf: ScalarFunction TableFunction AggregateFunction 用户自定义函数是非常重要的一个特征,因为他极大地扩展了查询的表达能力.本文除了介 ...
- 使用flink Table &Sql api来构建批量和流式应用(2)Table API概述
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
随机推荐
- mysql读写分离之springboot集成
springboot.mysql实现读写分离 1.首先在springcloud config中配置读写数据库 mysql: datasource: readSize: 1 #读库个数 type: co ...
- ubuntu 安装psycopg2包
psycopg2 库是 python 用来操作 postgreSQL 数据库的第三方库. 执行:pip3 install psycopg2==2.8.4 有可能会报错: Collecting psyc ...
- JuiceFS 在多云架构中加速大模型推理
在大模型的开发与应用中,数据预处理.模型开发.训练和推理构成四个关键环节.本文将重点探讨推理环节.在之前的博客中,社区用户 BentoML 和贝壳的案例提到了使用 JuiceFS 社区版来提高模型加载 ...
- LaTeX 编译 acmart 文档报错:An attempt to redefine \baselinestretch detected. Please do not do this for ACM submissions!
在编译一篇从 arXiv 下载的文档时遇到如下错误: Class acmart Error: An attempt to redefine \baselinestretch detected. Ple ...
- Android 获取当前获取焦点的组件
在Activity中,使用this.getCurrentFocus(),获取当前焦点所在的View, 再判断是否是EditText(可调整成其他组件),看个人需要再做特定的逻辑处理 String co ...
- .NET 8.0 前后分离快速开发框架
前言 大家好,推荐一个.NET 8.0 为核心,结合前端 Vue 框架,实现了前后端完全分离的设计理念.它不仅提供了强大的基础功能支持,如权限管理.代码生成器等,还通过采用主流技术和最佳实践,显著降低 ...
- spark 解析 kafka message
备用 https://databricks.com/blog/2018/11/30/apache-avro-as-a-built-in-data-source-in-apache-spark-2-4. ...
- 小tips:使用JSON.parse(JSON.stringify(object))实现深拷贝的局限及扩展
使用JSON.parse(JSON.stringify(object))实现深拷贝局限 大部分情况我们都可以使用JSON.parse(JSON.stringify(object))来实现深拷贝,但该方 ...
- CSS – PostCSS
前言 我第一次接触 PostCSS 是在学 Tailwind CSS 的时候. 它类似 JavaScript 的 Babel. 我没有用过 Babel, 因为 TypeScript 用的早. Post ...
- Figma 学习笔记 – Prototype
挺简单的, 只要知道它有什么, 基本上就会用了 监听 Event Type 监听 Callback Action 过度 Animation Frame Scrolling