(转)Python爬虫--通用框架
转自https://blog.csdn.net/m0_37903789/article/details/74935906
前言:
相信不少写过Python爬虫的小伙伴,都应该有和笔者一样的经历吧只要确定了要爬取的目标,就开始疯狂的写代码,写脚本经过一番努力后,爬取到目标数据;但是回过头来,却发现自己所代码复用性小,一旦网页发生了更改,我们也不得不随之更改自己的代码,而却自己的程序过于脚本化,函数化,没有采用OPP的思维方式;没有系统的框架或结构。
指导老师看了笔者的爬虫作品后,便给出了以下三点建议:
(1)爬虫爬取的数据根据需要存数据库或直接写入.csv文件;
(2)爬虫程序包括控制程序、URL调度器、页面加载器、页面分析器、数据处理器等,尽量用OOP的思想,写成类,便于扩充,而不要直接全写成脚本;
(3)控制程序最好使用一个用户界面,用于设置开始爬取的页面、数据存放位置、显示爬取情况等。
由于笔者知识和能力有限,刚听到这些建议时,很难明白他的意思,而笔者还偏执的认为既然已经成功的爬取到目标数据,也就没什么要做的啦,已经OK啦直到昨天看了这个http://www.imooc.com/learn/563关于Python爬虫的课程后,才彻底的理解了老师教的课程里系统的讲解了爬虫应有的框架和结构,使笔者收益匪浅,故在此总结,反思,希望对大家有帮助。
这里先为它,打个小广告吧~笔者个人认为,不管你是资深的Python爬虫专家,还是才接触爬虫的新手,都应该来看一看,为你以后的Python爬虫工作添砖加瓦,广告语“慕课网—程序员的梦工厂”。
PS:以下截图,为笔者再听课时截图整理所得,故图片来源该课程的PPT
基于百度百科词条,通用爬虫源码:https://github.com/NO1117/baike_spider
Python交流群:942913325 欢迎大家一起交流学习
总结:
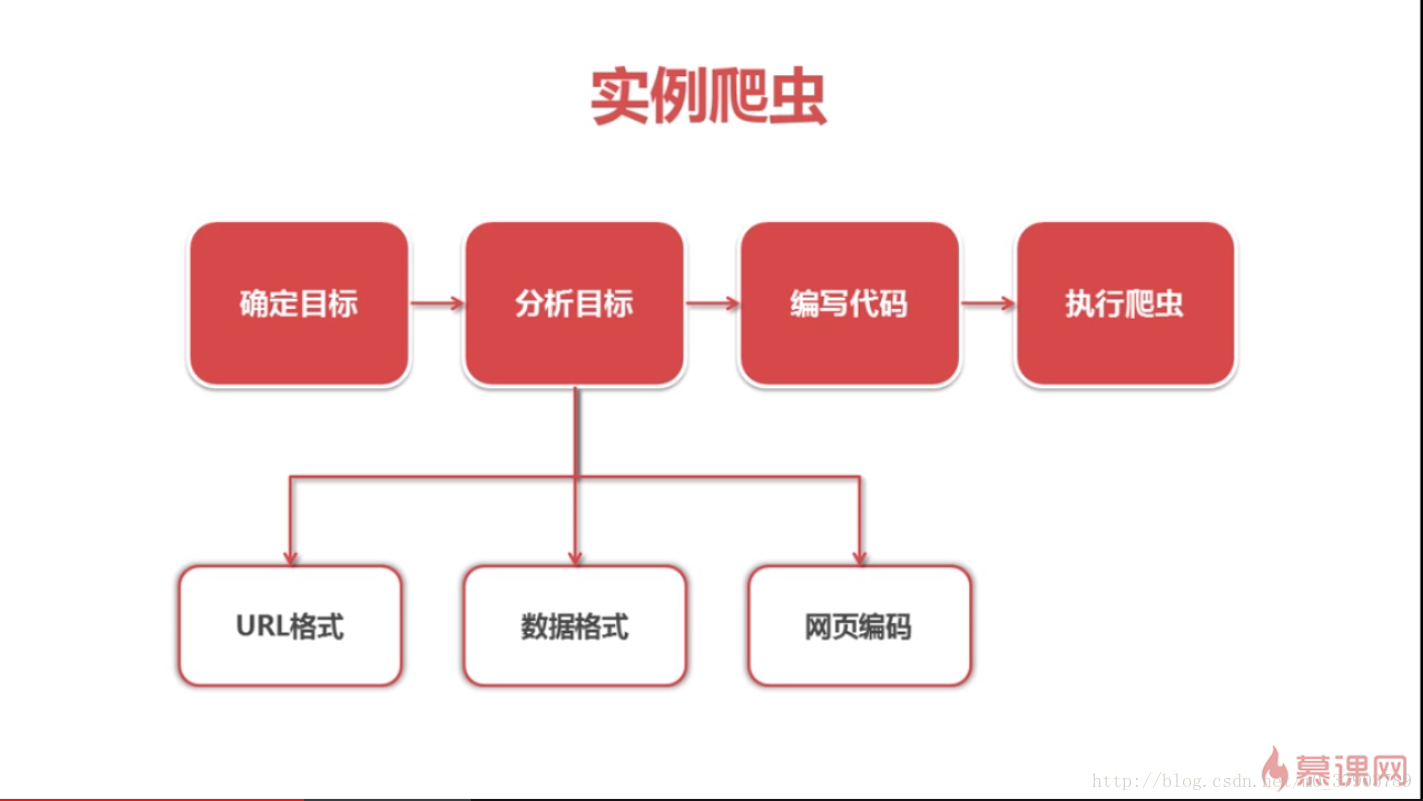
1.爬虫思路
如上图所示,一般在开始爬虫时,都会经历这样的思考过程,其中最为主要和关键的分析目标,只有经过准确的分析和前期的充分准备,才能顺顺利利的爬取到目标数据。
2.爬虫任务:

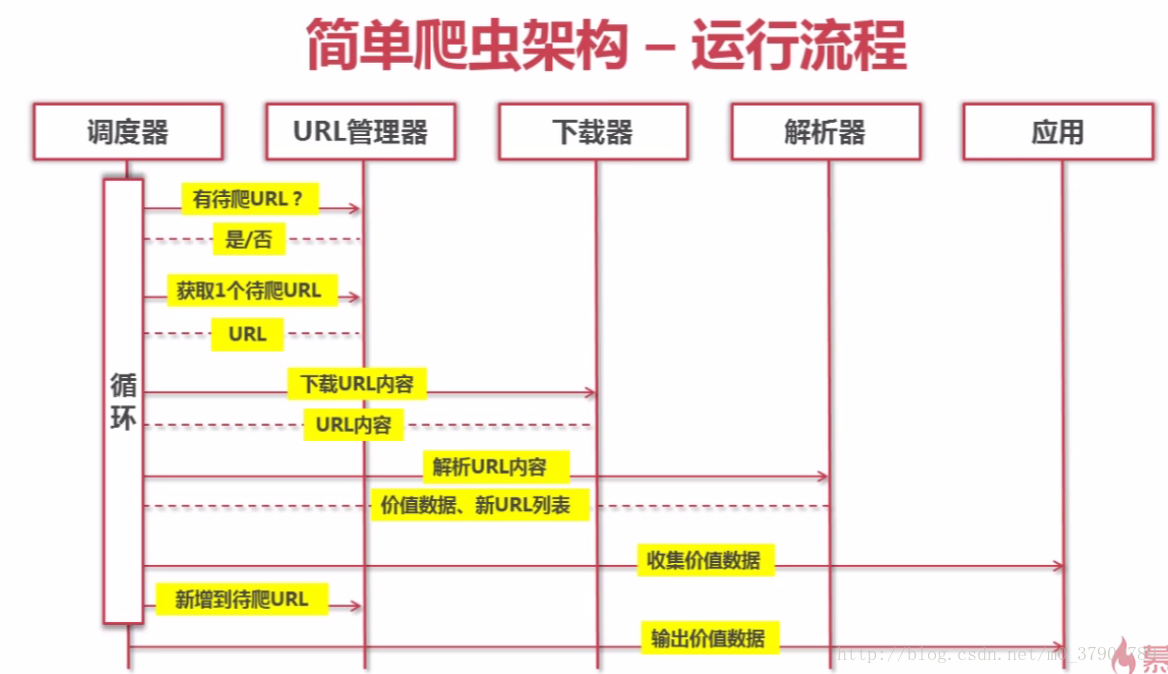
3.爬虫的框架及运行流程图
接下来,就一起学习一下Python爬虫的框架吧~
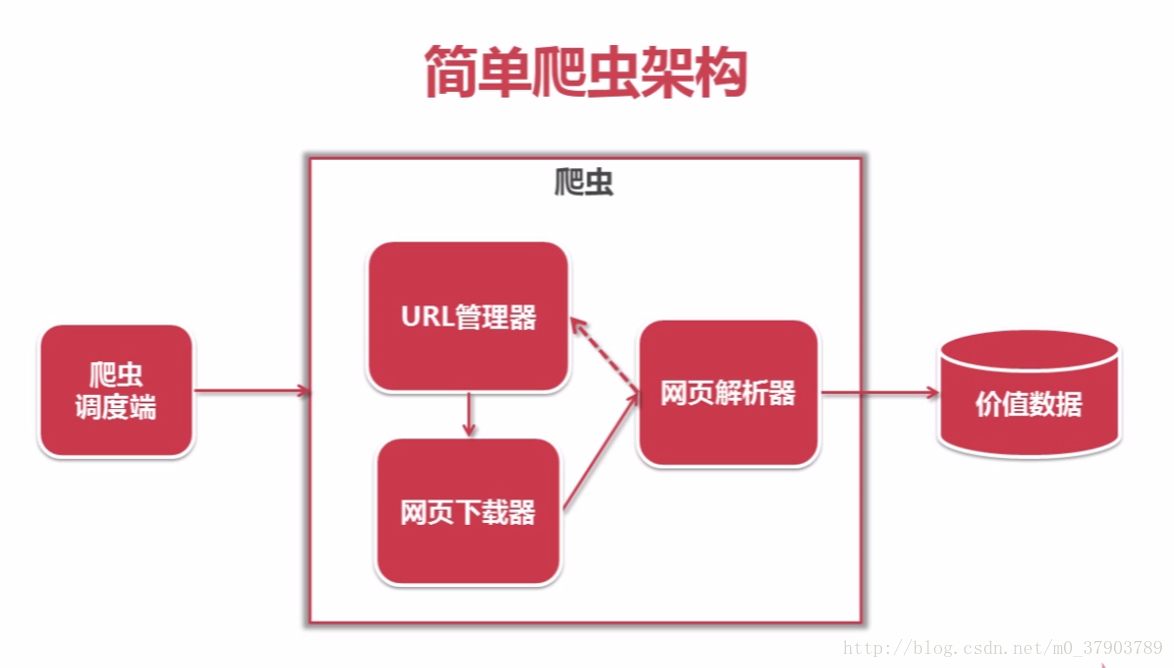
爬虫的大致运行过程如下:
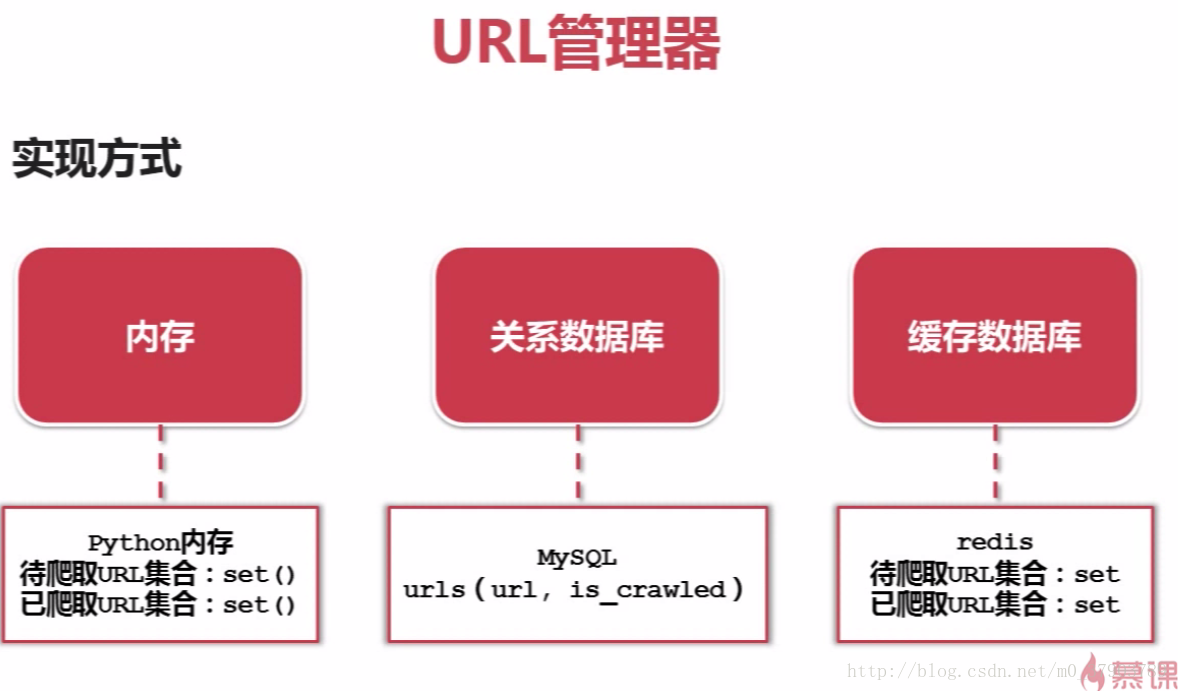
4.URL管理器
所谓的URL管理器,主要是由两个集合构成(待抓取URL集合和已抓取URL集合),其目的是为了防止重复抓取,循环抓取;
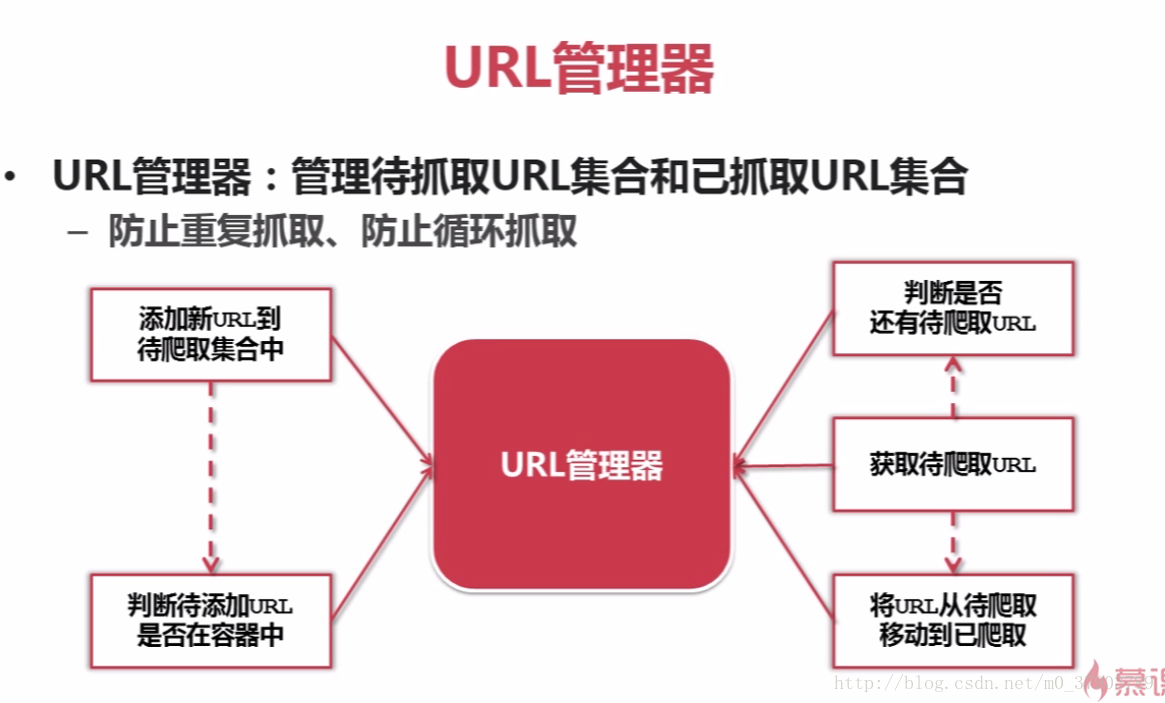
URL管理器的实现方式,分三种:a,Python内存(即集合);b,数据库(如MySQL,MongoDB等);c,缓存数据库
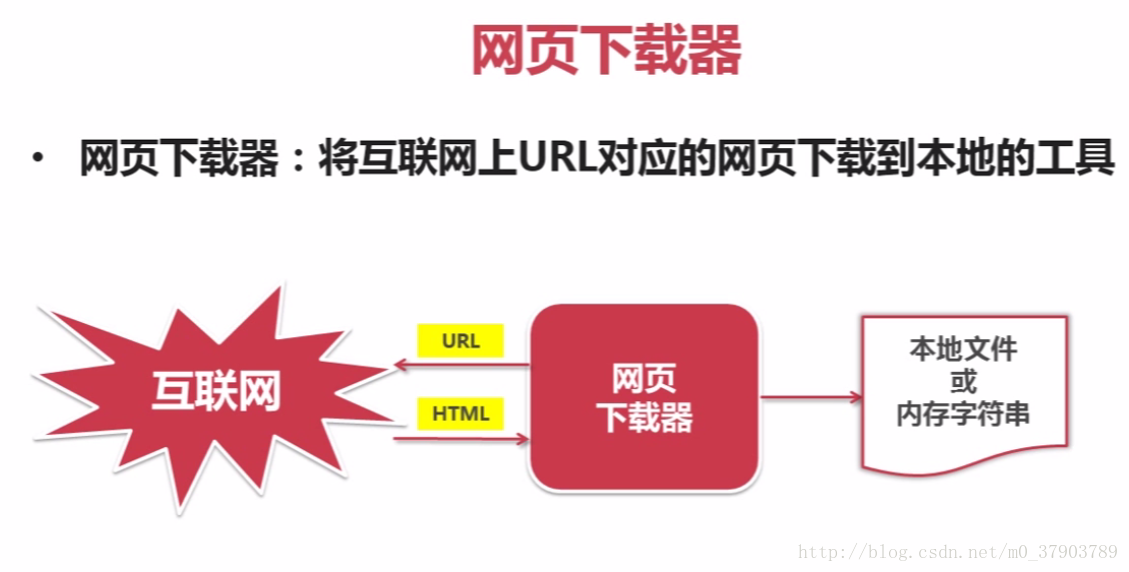
5.网页下载器
所谓网页下载器,即是将互联网上URL对应的网页下载到本地的工具
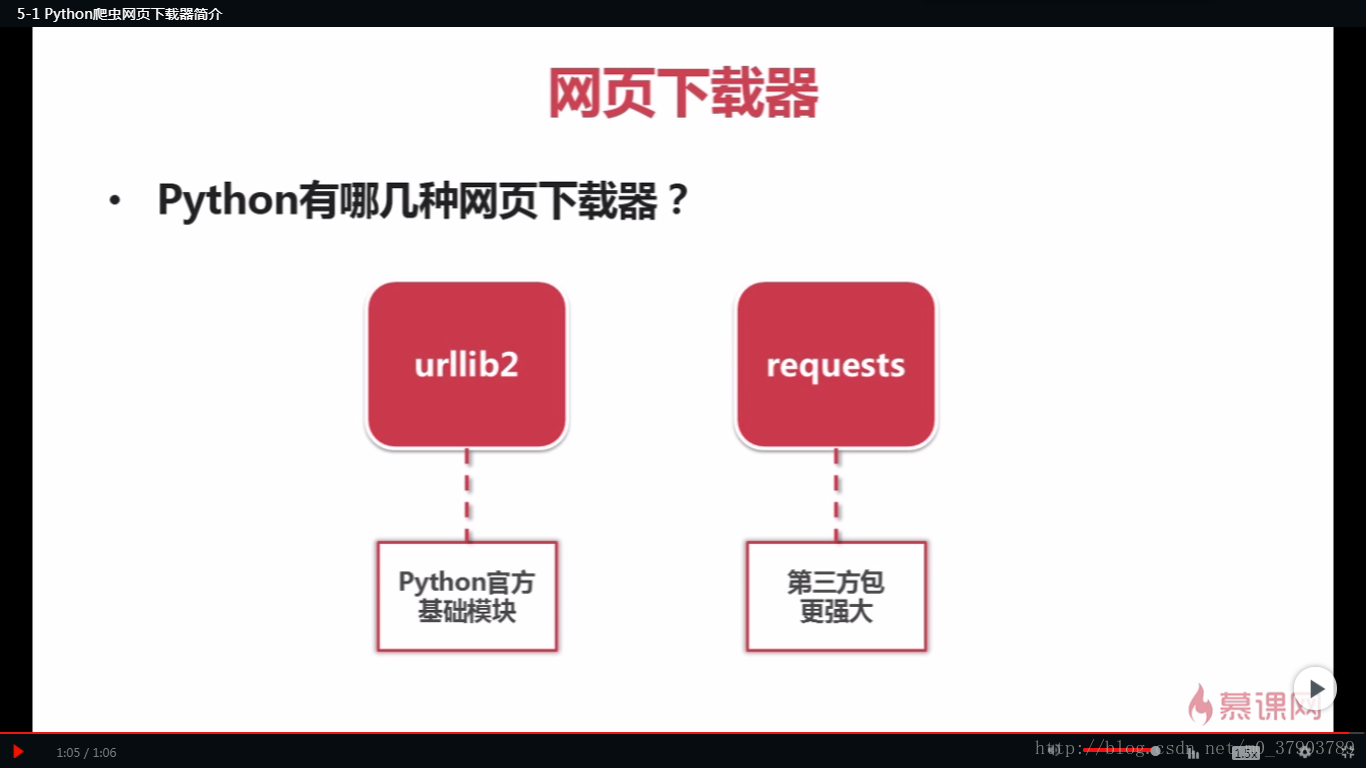
网页下载器,大致为request和urllib2两种;
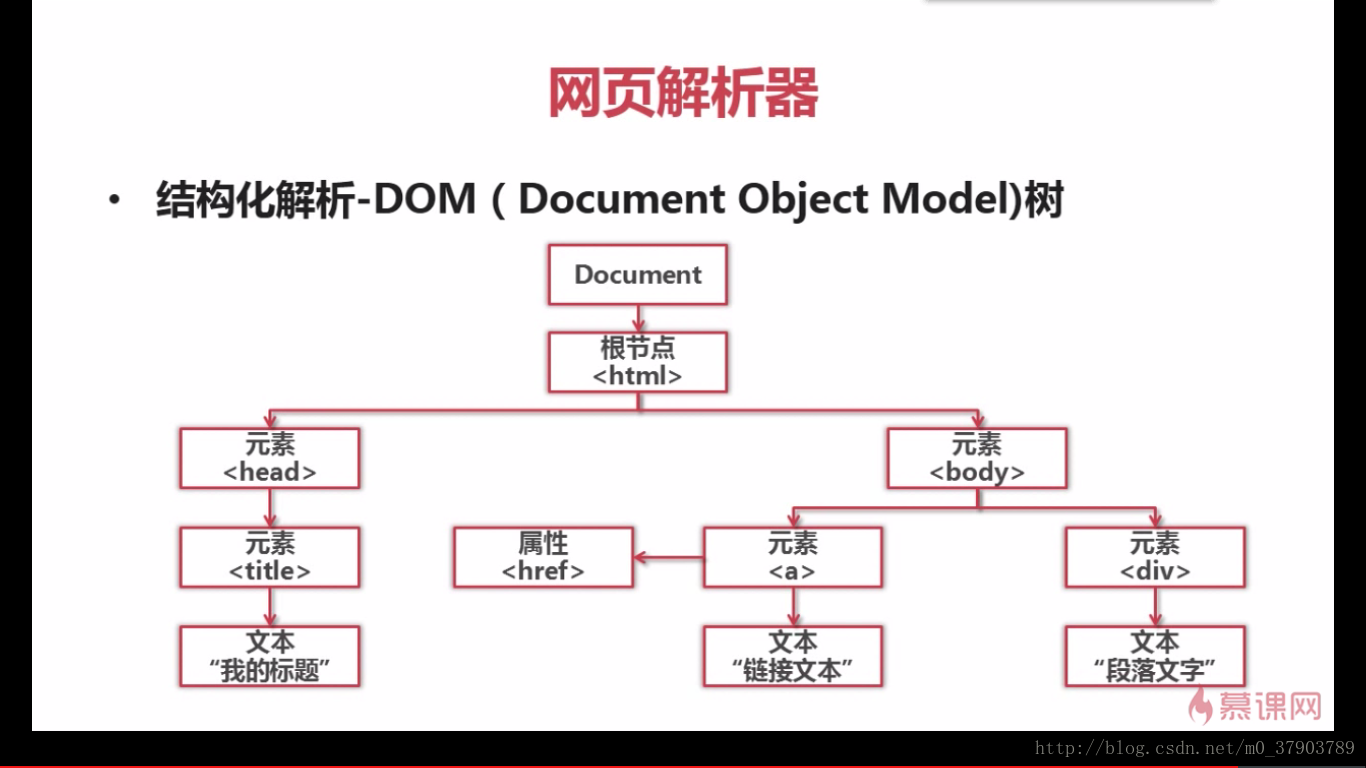
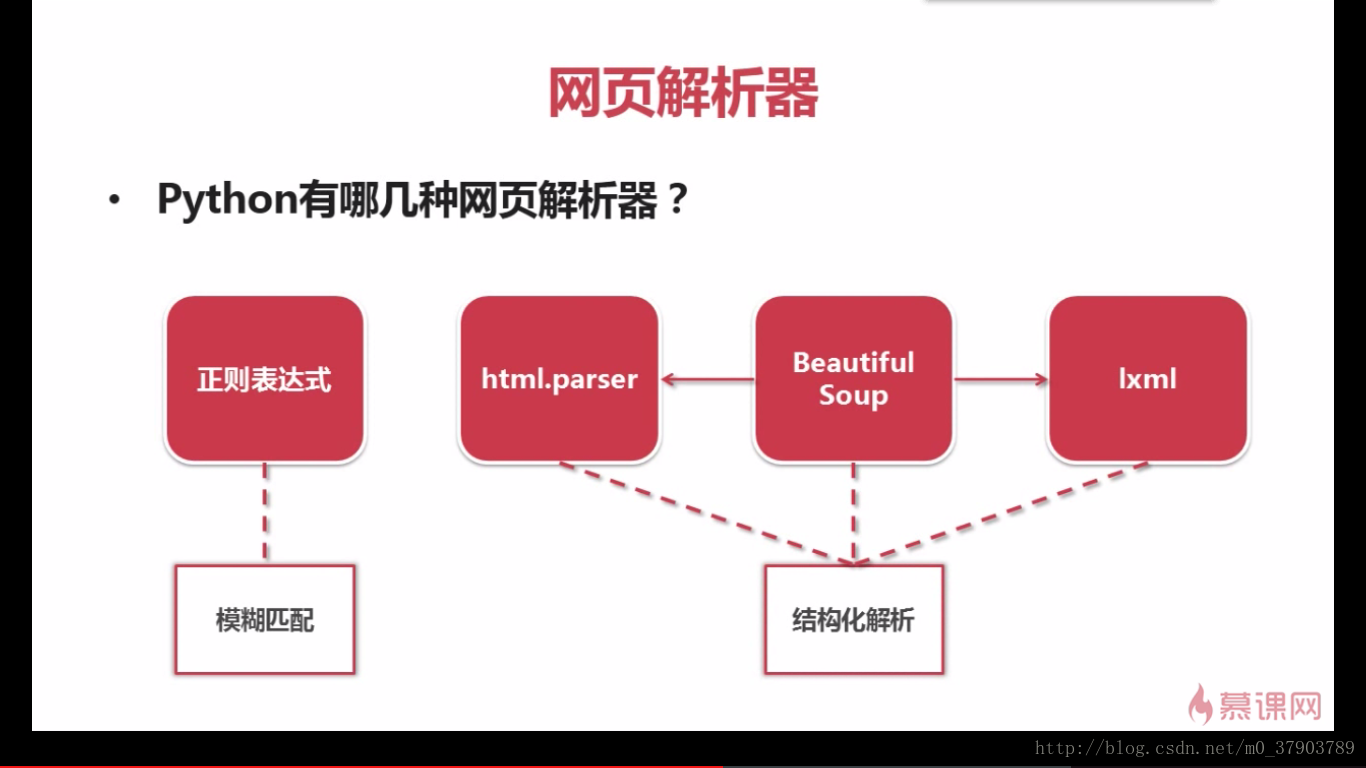
6.网页解析器
什么是网页解析器?
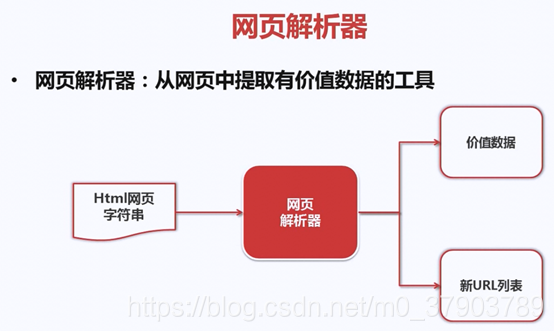
下面,我们来看看,如何解析一个网页文件
解析器种类: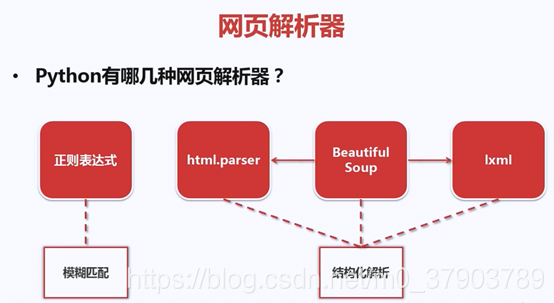
好了,通过以上的学习,我们掌握了Python爬虫的简单框架。那么怎样才能写一个好的python爬虫呢?又该如何去编写代码,实现我们的爬虫功能呢?下一步又该如何优化我们的爬虫代码呢?
(转)Python爬虫--通用框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- Python爬虫-pyspider框架的使用
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优 ...
- Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50 一.Scrapy爬虫的基本命令 Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行. Scrapy命令行格式 Scrapy常用命令 采用 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
随机推荐
- angular组件间的通信(父子、不同组件的数据、方法的传递和调用)
angular组件间的通信(父子.不同组件的数据.方法的传递和调用) 一.不同组件的传值(使用服务解决) 1.创建服务组件 不同组件相互传递,使用服务组件,比较方便,简单,容易.先将公共组件写在服务的 ...
- Flask(1)- 简介
背景 为啥要学,很久之前就学过点,没写文章 最近因为要写机器人工具,其实就是简单的纯服务端工具 反正 flask 也挺简单,一天快速过完 概念会直接搬教程的,实操自己敲一遍再总结 参考教程 https ...
- redis集群搭建中遇到的一些问题
redis单机模式启动后,修改完配置文件,使用以下命令创建redis集群: sudo ./src/redis-trib.rb create --replicas 1 ip1:6379 ip2:6379 ...
- buu 刮开有奖
一.查壳, 二.拖入ida,分析 直接搜字符串完全没头绪,在看了大佬的wp才找到了,关键函数. 明显那个String就是我们要求的flag,要开始分析程序. 字符串长度为8,同时这个函数对字符串进行了 ...
- 线程中sleep()方法和wait()方法的前生今世
先看再点赞,给自己一点思考的时间,如果对自己有帮助,微信搜索[程序职场]关注这个执着的职场程序员.我有什么:职场规划指导,技能提升方法,讲不完的职场故事,个人成长经验. 不知道大家有没有这种感觉,在公 ...
- 北京大公司:你是熟悉Map集合吗?
<对线面试官>系列目前已经连载30篇啦,这是一个讲人话面试系列 [对线面试官]Java注解 [对线面试官]Java泛型 [对线面试官] Java NIO [对线面试官]Java反射 &am ...
- lxml的使用(节点与xpath爬取数据)
lxml安装 lxml是python下功能很丰富的XML和HTML解析库,性能非常的好,是对libxml3和libxlst的封装.在Windows下载这个库直接使用 pip install lxml ...
- 【洛谷P2623物品选取】动态规划
分析 各种背包弄在一起. AC代码 // luogu-judger-enable-o2 #include <bits/stdc++.h> using namespace std; #def ...
- 记一次Hvv中遇到的API接口泄露而引起的一系列漏洞
引言 最近朋友跟我一起把之前废弃的公众号做起来了,更名为鹿鸣安全团队,后面陆续会更新个人笔记,有趣的渗透经历,内网渗透相关话题等,欢迎大家关注 前言 Hvv中的一个很有趣的漏洞挖掘过程,从一个简单的A ...
- python中的abstractmethod
# -*- coding: utf-8 -*- from abc import ABC ,abstractclassmethod from collections import namedtuple ...