Springboot集成ES启动报错
报错内容
None of the configured nodes are available
elasticsearch.yml配置
cluster.name: ftest
node.name: node-72
node.master: true
node.data: true
network.host: 112.122.245.212
http.port: 39200
transport.tcp.port: 39300
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
discovery.zen.ping.unicast.hosts.resolve_timeout: 30s
#index.codec: best_compression
http.cors.allow-origin: "/.*/"
http.cors.enabled: true
path.repo: ["/home/xxx/backups"]
Java客户端配置
import com.xxx.commons.log.BaseLogger;
import com.xxx.data.elasticsearch.core.ElasticsearchTemplate;
import java.net.InetAddress;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; @Configuration
public class ElasticsearchConfiguration extends BaseLogger {
private static TransportClient transport = null;
@Value("${elasticsearch.cluster.sniff:true}")
private Boolean sniff;
@Value("${elasticsearch.cluster.name:elasticsearch}")
private String clusterName;
@Value("${elasticsearch.cluster.hostname:localhost}")
private String hostname;
@Value("${elasticsearch.cluster.port:9300}")
private int port; public ElasticsearchConfiguration() {
} @Bean(
name = {"elasticsearchTemplate"}
)
public ElasticsearchTemplate elasticsearchTemplate() {
return new ElasticsearchTemplate(this.client());
} @Bean
public Client client() {
if (transport == null) {
Settings settings = Settings.builder().put("client.transport.sniff", this.sniff).put("cluster.name", this.clusterName).build();
this.logger.info("connection elasticserch info : hostname:{}, port: {}", this.hostname, this.port);
transport = new PreBuiltTransportClient(settings, new Class[0]);
String[] hostnames = this.hostname.split(","); try {
for(int i = 0; i < hostnames.length; ++i) {
this.logger.info("链接es=======>:{}", hostnames[i]);
TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName(hostnames[i]), this.port);
transport.addTransportAddresses(new TransportAddress[]{transportAddress});
} return transport;
} catch (Exception var5) {
this.logger.error("", var5);
return null;
}
} else {
return null;
}
}
}
ES客户端属性配置
<profile>
<id>test-HA</id>
<properties> <!--系统配置-->
<server.bind.host>0.0.0.0</server.bind.host>
<server.bind.port>30030</server.bind.port> <!--elasticsearch配置-->
<elasticsearch.cluster.name>fans</elasticsearch.cluster.name>
<elasticsearch.cluster.hostname>112.122.245.212</elasticsearch.cluster.hostname>
<elasticsearch.cluster.port>39200</elasticsearch.cluster.port>
</profile>
问题追踪
在异常栈中定位到 org.elasticsearch.client.transport.TransportClientNodesService#ensureNodesAreAvailable

继续找到 org.elasticsearch.client.transport.TransportClientNodesService#execute
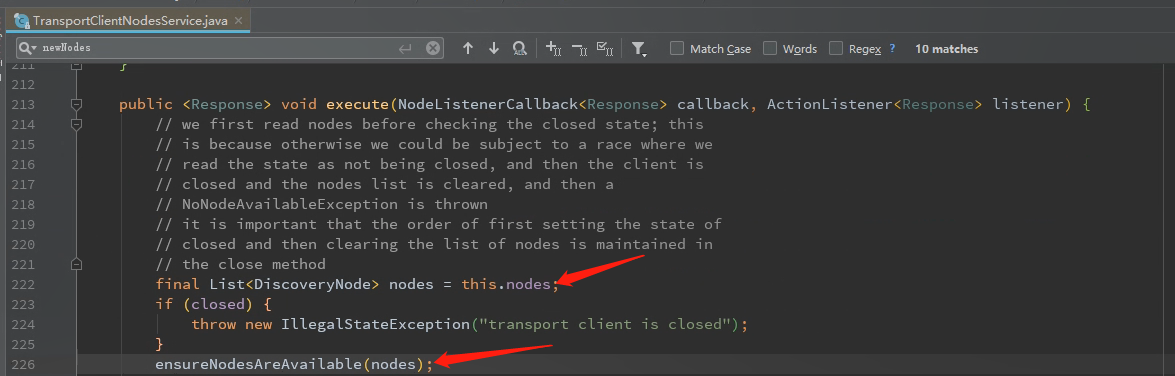
this.nodes变量的添加逻辑是在 org.elasticsearch.client.transport.TransportClientNodesService$SimpleNodeSampler#doSample
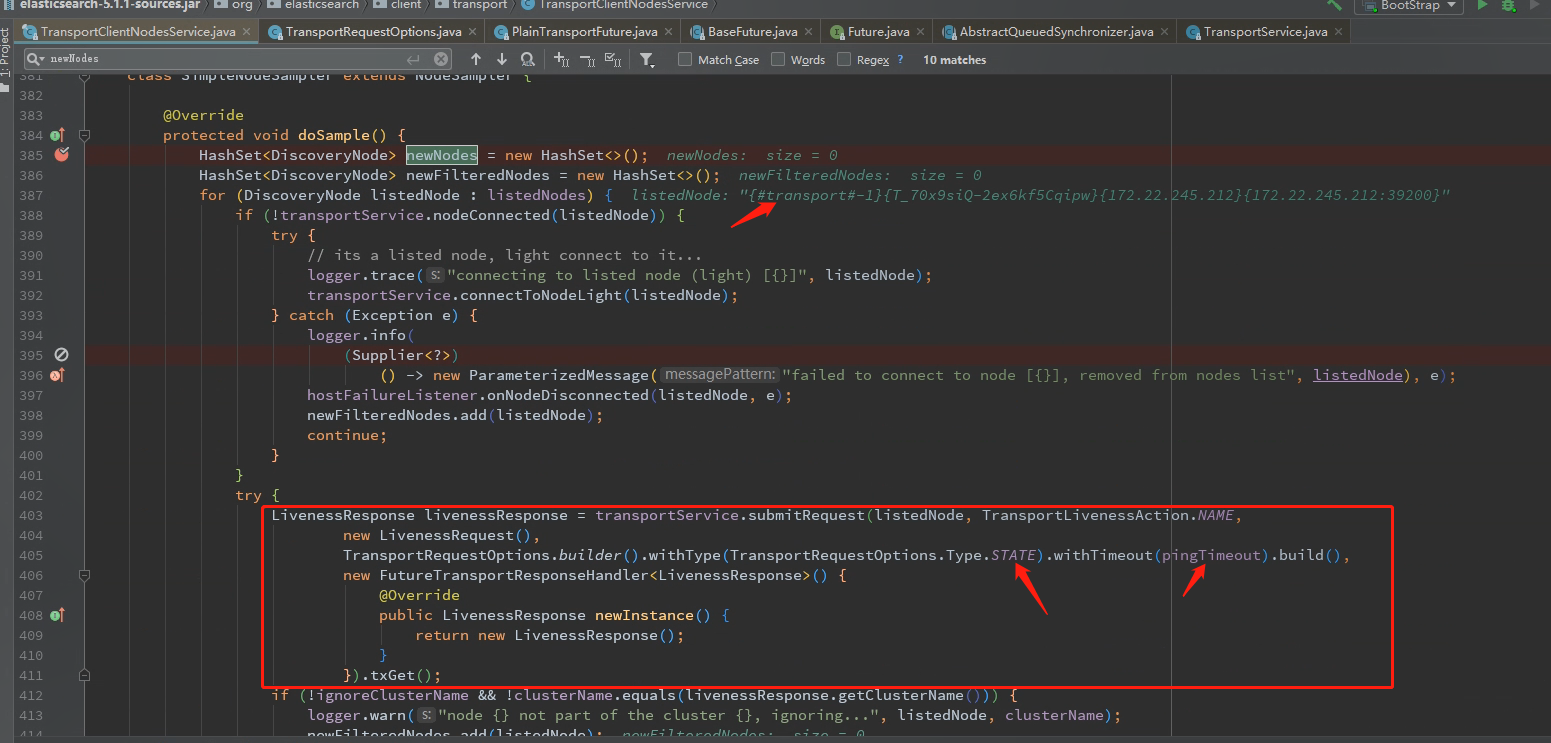

this.nodes变量保存了可用的ES连接节点信息,从上图可以看出,ReceiveTimeoutTransportException。很明显,连接超时了。
直接访问es ip+端口可以获得如下信息。
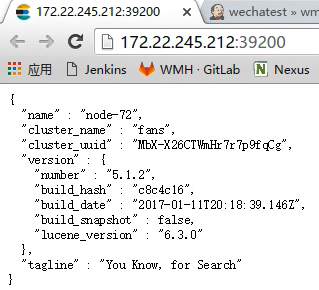
按理配置是没有问题的。后来突然意识到 “transport” 这个关键字,然后发觉端口配置错误了。
总结一下es连接异常原因
Springboot集成ES启动报错的更多相关文章
- SpringBoot发布WAR启动报错:Error assembling WAR: webxml attribute is required
Spring Boot发布war包流程: 1.修改web model的pom.xml <packaging>war</packaging> SpringBoot默认发布的都是j ...
- SpringBoot整合nacos启动报错:java.lang.NoClassDefFoundError: org/springframework/boot/context/properties/ConfigurationBeanFactoryMetadata
报错信息 org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'nacosCo ...
- springboot多数据源启动报错:required a single bean, but 6 were found:
技术群: 816227112 参考:https://stackoverflow.com/questions/43455869/could-not-autowire-there-is-more-than ...
- SpringBoot项目集成Swagger启动报错: Failed to start bean 'documentationPluginsBootstrapper'; nested exception is
使用的Swagger版本是2.9.2.knife4j版本是2.0.4. SpringBoot 版本是2.6.2将SpringBoot版本回退到2.5.6就可以正常启动
- SpringBoot学习之启动报错【This application has no explicit mapping for /error.....】
今天做SpringBoot小例子,在请求controller层的时候出现如下问题. Whitelabel Error Page This application has no explicit map ...
- springboot放到linux启动报错:The temporary upload location [/tmp/tomcat.8524616412347407692.8111/work/Tomcat/localhost/ROOT/asset] is not valid
1.背景 笔者的springboot在一个非root用户环境下运行,这种环境下可以保证不被潜在的jar/开源框架漏洞提权. 比如在防火墙上把外网访问来的443端口映射到本地8443的java web端 ...
- SpringBoot整合Elasticsearch启动报错处理 nested exception is java.lang.IllegalStateException: availableProcessors is already set to [8], rejecting [8]
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean wit ...
- ES启动报错之引导检测失败
[--16T18::,][ERROR][o.e.b.Bootstrap ] [node-] node validation exception [] bootstrap checks failed [ ...
- ES启动报错最大进程数太少
[--16T18::,][INFO ][o.e.b.BootstrapChecks ] [node-] bound or publishing to a non-loopback address, e ...
随机推荐
- Scratch 2.0-Find The Mouse 发布!
日期:2018.8.26 星期日 博客期:007 今天随便写了一个小型游戏程序,哈哈!虽然小,但用到的逻辑还是有一定水平的.呼~毕竟就这一下子也写不出来微软一样的公司嘛!哈哈,截图放上来! 游戏分为四 ...
- LeetCode(75):分类颜色
Medium! 题目描述: 给定一个包含红色.白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色.白色.蓝色顺序排列. 此题中,我们使用整数 0. 1 和 2 ...
- Metasploit (二)
1.测试一台搭建的主机 msf > db_nmap -n -A 10.140.110.16[*] Nmap: Starting Nmap 7.60 ( https://nmap.org ) at ...
- Nginx详解十一:Nginx场景实践篇之Nginx缓存
浏览器缓存: HTTP协议定义的缓存机制(如:Expires.Cache-control等) 当浏览器第一次请求的时候,浏览器是没有缓存的 第二次请求开始就有缓存了 校验过期机制 配置语法-expir ...
- 【专栏学习】APM——异步编程模型(.NET不推荐)
(1)learning hard C#学习笔记 异步1:<learning hard C#学习笔记>读书笔记(20)异步编程 (2)<C# 4.0 图解教程> 22.4 异步编 ...
- golang 中操作nsq队列数据库
首先先在本地将服务跑起来,我用的是docker-compose ,一句话6666 先新建一个docker-compose.yml version: '2' services: nsqlookupd: ...
- some advice in work
给研究生的建议 文档抄袭自:北航大佬 Fei-Fei Li:De-Mystifying Good Research and Good Papers (repost) 如何提升你的能力?给年轻程序员的几 ...
- 线程 ID
摘自<Linux 环境编程:从应用到内核> 在 Linux 中,目前的线程实现是 Native POSIX Thread Library,简称 NPTL.在这种实现下,线程又被称为轻量级进 ...
- 2018项目UML设计-课堂实战
1. 团队信息 队名:小白吃队 成员: 卢泽明 031602328 蔡文斌 031602301 葛亮 031602617 刘浩 031602423 张扬 031602345 李泓 031602321 ...
- [转]利用ssh传输文件
利用ssh传输文件 http://www.cnblogs.com/jiangyao/archive/2011/01/26/1945570.html 在linux下一般用scp这个命令来通过ssh传输文 ...