SQL Server索引的执行计划
如何知道索引有问题,最直接的方法就是查看执行计划。通过执行计划,可以回答表上的索引是否被使用的问题。
(1)包含索引:避免书签查找
常见的索引方面的性能问题就是书签查找,书签查找分为RID查找和键值查找。
当非聚集索引被用于查找数据,但又不能覆盖查询时,就会引起书签查找。此时优化器会借助堆上的RID或者聚集索引上的聚集索引键来查找所需的额外数据,前者叫做RID,后者叫做键值查找。
书签查找就是为了找额外的列,如果数据量少并不是什么问题,但是当数据量很大,额外的列很多时,往往会带来额外的I/O开销,影响性能。
select sod.ProductID,sod.OrderQty,sod.UnitPrice
from Sales.SalesOrderDetail sod where sod.ProductID=897
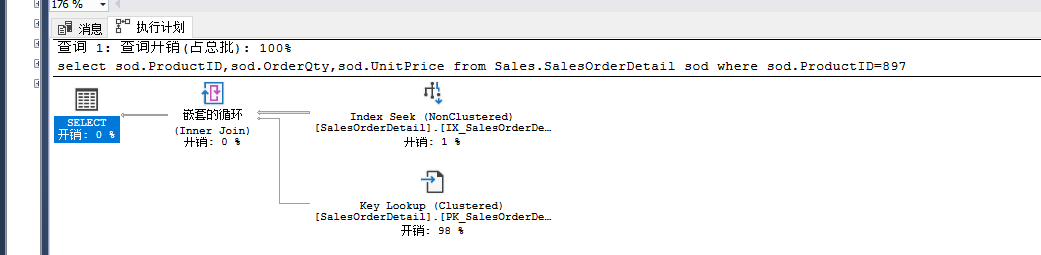
这个的性能根源----其实就是在键值查找上。对策,尽量使用查询在一个索引中完成,这一步可以通过覆盖索引和包含索引来实现。
if exists
(select * from sys.indexes where
object_id=OBJECT_ID(N'Sales.SalesOrderDetail')
and name=N'IX_SalesOrderDetail_ProductID')
drop index IX_SalesOrderDetail_ProductID on Sales.SalesOrderDetail with (online=off);
创建索引:
create nonclustered index IX_SalesOrderDetail_ProductID
on Sales.SalesOrderDetail(ProductID asc)
include (OrderQty,UnitPrice) with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off,
IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON)
ON [PRIMARY];
再次执行上述语句,执行计划如下:

逻辑读从1240下降到3次,是一个很大的提升,从实践来说,书签查找是常见的性能问题标志,当出现这个操作符,且百分比相对较高时,就必须分析是否有必要调整优化。
(2)索引选择度
对于每个索引,优化器都会自定创建统计信息来描述这个索引的数据分布情况。在后续的使用中,优化器会根据这些统计信息来决定查询是否使用这些索引。
通过以下语句可以查看统计信息:
dbcc show_Statistics('Sales.SalesOrderDetail','IX_SalesOrderDetail_ProductID')
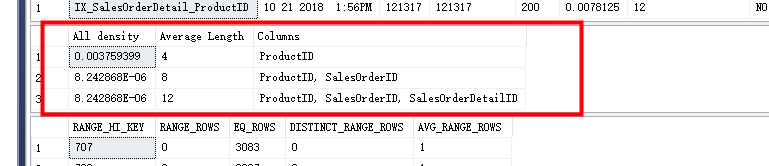
这个索引上的ProductID的密度为0.0037593999,是非常低的值也就是选择度很高,最优可能被使用,而其他两行是聚集索引的列,由于非聚集索引的叶子节点会指向聚集索引键,这里的统计信息会包含这两列,并同时给出对应的密度。如果表上没有聚集索引,那么非聚集索引会指向数据本身。如果选择度很低,优化器会放弃索引。
select sod.OrderQty,sod.SalesOrderID,
sod.SalesOrderDetailID,sod.LineTotal from Sales.SalesOrderDetail sod where sod.OrderQty=10;

优化器使用了聚集索引扫描来实现WHERE条件的筛选操作。对这个列加上索引。
create nonclustered Index IX_SalesOrderDetail_OrderQty
on Sales.SalesOrderDetail(orderQty asc)
with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off,
IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON)
on [Primary]
查看统计信息:
dbcc SHOW_STATISTICS('Sales.SalesOrderDetail','IX_SalesOrderDetail_OrderQty')
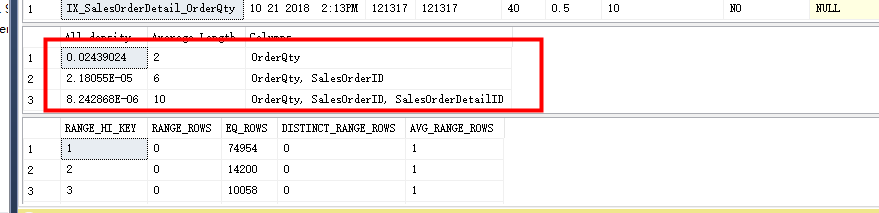
这个选择度不高,如果再次执行查询语句,可以看到执行计划中依旧会使用原有计划。

如果选择度不高,优化器依旧会放弃上面的索引。
删除新建的索引:
drop index Sales.SalesOrderDetail.IX_SalesOrderDetail_OrderQty
(3)统计信息和索引
优化器会对每个索引创建统计信息,如果统计信息过时,优化器同样可能不选择“有用索引”。
if EXISTS (select * from sys.objects where object_id=OBJECT_ID('N[NewOrders]') and type in (N'U'))
drop table[NewOrders]
go
select * into NewOrders from Sales.SalesOrderDetail
go
create index IX_NewOrders_ProductID on NewOrders(ProductID)
使用一个简答的查询生成预估执行计划,接着在事物中更新数据,影响ProductID列上的数据分布,让其选择度变低。最后获取实际执行计划。
set showplan_xml on
go
select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897
go
set showplan_xml off
预估执行计划:
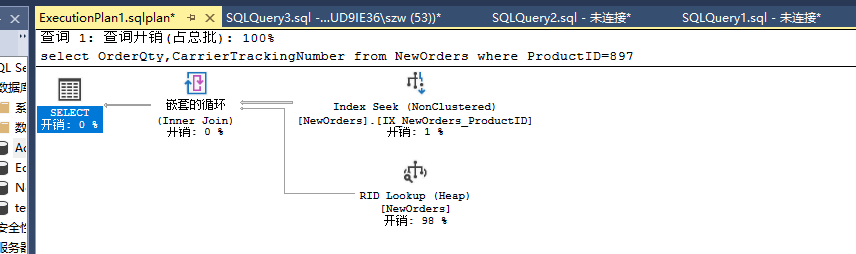
begin tran
update NewOrders
set ProductID=897
where ProductID between 800 and 900 --实际的执行计划
set statistics xml on
go
select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897
rollback tran
go
set statistics xml off
实际执行计划:
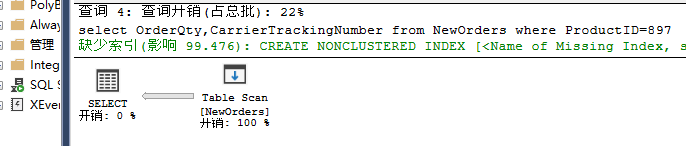
由于统计信息得变更,优化器对同一个查询选择不同的执行计划。更新操作使得列上的数据分布发生改变,选择度降低,优化器会“觉得”使用扫描操作时开销更低。因此,确保统计信息得实时性及有效性对性能的提升非常重要。
SQL Server索引的执行计划的更多相关文章
- 谈一谈SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- 浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- 谈一谈SQL Server中的执行计划缓存(下)
简介 在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突.本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法. 将执行缓存考虑在内时的流程 上篇文章中提到了查询优 ...
- SQL Server如何固定执行计划
SQL Server 其实从SQL Server 2005开始,也提供了类似ORACLE中固定执行计划的功能,只是好像很少人使用这个功能.当然在SQL Server中不叫"固定执行计划&qu ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- SQL Server 索引的自动维护 <第十三篇>
在有大量事务的数据库中,表和索引随着时间的推移而碎片化.因此,为了增进性能,应该定期检查表和索引的碎片,并对具有大量碎片的进行整理. 1.确定当前数据库中所有需要分析碎片的表. 2.确定所有表和索引的 ...
随机推荐
- Error "Client wants topic A to have B, but our version has C. Dropping connection."
ROS problem 出现这个问题的原因是话题上的消息类型和订阅节点指定的消息类型不匹配.
- 【ARTS】01_17_左耳听风-20190304~20190310
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- Windows Server 2008 R2忘记密码导致无法修改密码
其实有个记住密码的工具还是简单的,登陆系统后,CMD输入命令: net user administrator NewPassword 新密码即时生效
- flask(1)
在Python中常用的web框架有flask.Django.tornado # -*- encoding: utf-8 -*- from flask import Flask #建立Flask对象 a ...
- ffmpeg-3.2.4-static-win32-for-XP-bin.tar.xz
ffmpeg-3.2.4-static-win32-for-XP-bin.tar.xz ffmpeg-3.2.4-static-win32-for-XP-bin-v3.tar.xz v3版本升级了库文 ...
- MySQL--视图view、触发器trigger、事务(start transaction)、存储过程(特殊的数据逻辑处理函数)、流程控制(if,case....)
mysql致力于项目开发及数据库管理之间解耦合(帮忙封装一些数据处理方法,使应用程序的开发者可以专注于应用程序的开发),但受限于不同部门沟通的成本问题,现阶段直接使用的价值不大. 一.视图(只能sel ...
- Linux mem/swap/buffers/cached 区别
Free free 命令相对于top 提供了更简洁的查看系统内存使用情况: $ free total used free shared buffers cached Mem: 255268 23833 ...
- SQL Server 之 内部连接
1.内部联接 2.外部联接 外部联接扩展了内部联接的功能,会把内联接中删除表源中的一些保留下来,由于保存下来的行不同,可将外部联接分为左联接和右联接. 2.1左联接: 如果左表的某一行在右表中没有匹配 ...
- php array_map与array_walk使用对比
array_map(): 1.array_map() 函数将用户自定义函数作用到数组中的每个值上,并返回用户自定义函数作用后的带有新值的数组,若函数作用后无返回值,则对应的新值数组中为空. 2.回调函 ...
- LVM初级配置
步骤: 1.将物理硬盘转换成物理卷(PV) 创建PV:pvcreate /dev/vdb 2.将PV添加到卷组中(VG) vgcreate vg0 /dev/vdb 3.创建逻辑卷(LV)并从VG中调 ...