Spark之UDAF
一.简介
Spark的自定义udf和udaf是为了提供函数扩展,Spark本身提供了几十上百个算子,在数据分析的各个方面的常用计算方式都有提到,但计算场景千差万别,算子也不会面面俱到,如何在单机或集群上定义函数就是要重点关注的地方。特别是在集群模式中,函数需要使用spark注册才能在各个节点上使用,因此,udf和udaf就显得比较重要了。
二.设置日志级别
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别为WARN
三.创建spark入口
val spark = SparkSession.builder().appName("UdfUdaf").master("local[2]").getOrCreate()
val sc = spark.sparkContext
val sqlContext = spark.sqlContext
四.创建测试数据
val userData = Array(
"2015,11,www.baidu.com", "2016,14,www.google.com",
"2017,13,www.apache.com", "2015,21,www.spark.com",
"2016,32,www.hadoop.com", "2017,18,www.solr.com",
"2017,14,www.hive.com"
) val userDataRDD = sc.parallelize(userData) // 转化为RDD
val userDataType = userDataRDD.map(line => {
val Array(age, id, url) = line.split(",")
Row(age, id.toInt, url)
})
val structTypes = StructType(Array(
StructField("age", StringType, true),
StructField("id", IntegerType, true),
StructField("url", StringType, true)
))
// RDD转化为DataFrame
val userDataFrame = sqlContext.createDataFrame(userDataType,structTypes)
// 注冊临时表
userDataFrame.createOrReplaceTempView("udf")
五.自定义udf并测试
def isAdult(age : Int) ={
if(age > 18){
true
}else{
false
}
}
// 注册udf(方式一)
spark.udf.register("isAdult_1", (id : Int) => if(id > 18) true else false) // 匿名函数
// 注册udf(方式二)
spark.udf.register("isAdult_2", isAdult _) // 预先定义好的普通函数
// 验证udf方式一
val result_1 = sqlContext.sql("select * from udf where isAdult_1(udf.id)")
result_1.show(false)
// 验证udf方式二
val result_2 = sqlContext.sql("select * from udf where isAdult_2(udf.id)")
result_2.show(false)
六.执行结果
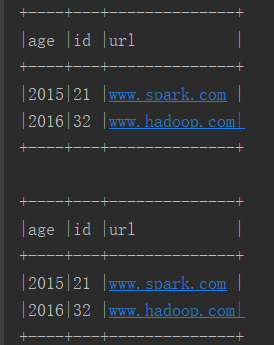
七.自定义udaf并测试
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction{
//聚合函数输入数据结构
override def inputSchema:StructType = StructType(StructField("input", LongType) :: Nil)
//缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
//结果数据结构
override def dataType : DataType = DoubleType
// 是否具有唯一性
override def deterministic : Boolean = true
//初始化
override def initialize(buffer : MutableAggregationBuffer) : Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
//数据处理 : 必写,其它方法可选,使用默认
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if(input.isNullAt(0)) return
buffer(0) = buffer.getLong(0) + input.getLong(0) //求和
buffer(1) = buffer.getLong(1) + 1 //计数
}
//合并
override def merge(bufferLeft: MutableAggregationBuffer, bufferRight: Row): Unit ={
bufferLeft(0) = bufferLeft.getLong(0) + bufferRight.getLong(0)
bufferLeft(1) = bufferLeft.getLong(1) + bufferRight.getLong(1)
}
//计算结果
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1)
}
/**
* 测试udaf
*/
spark.udf.register("average", AverageUserDefinedAggregateFunction)
spark.sql("select count(*) count,average(age) avg_age from udf").show(false)
八.执行结果

Spark之UDAF的更多相关文章
- Spark SQL UDAF示例
UDAF:用户自定义聚合函数 Scala 2.10.7,spark 2.0.0 package UDF_UDAF import java.util import org.apache.spark.Sp ...
- Spark笔记之使用UDAF(User Defined Aggregate Function)
一.UDAF简介 先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- Spark Sql的UDF和UDAF函数
Spark Sql提供了丰富的内置函数供猿友们使用,辣为何还要用户自定义函数呢?实际的业务场景可能很复杂,内置函数hold不住,所以spark sql提供了可扩展的内置函数接口:哥们,你的业务太变态了 ...
- spark编写UDF和UDAF
UDF: 一.编写udf类,在其中定义udf函数 package spark._sql.UDF import org.apache.spark.sql.functions._ /** * AUTHOR ...
- spark自定义函数之——UDAF使用详解及代码示例
UDAF简介 UDAF(User Defined Aggregate Function)即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组( ...
- 【转】Spark-Sql版本升级对应的新特性汇总
Spark-Sql版本升级对应的新特性汇总 SparkSQL的前身是Shark.由于Shark自身的不完善,2014年6月1日Reynold Xin宣布:停止对Shark的开发.SparkSQL抛弃原 ...
- 转:Spark User Defined Aggregate Function (UDAF) using Java
Sometimes the aggregate functions provided by Spark are not adequate, so Spark has a provision of ac ...
- Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
随机推荐
- IdentityServer4(7)- 使用客户端认证控制API访问(客户端授权模式)
一.前言 本文已更新到 .NET Core 2.2 本文包括后续的Demo都会放在github:https://github.com/stulzq/IdentityServer4.Samples (Q ...
- 从零基础到拿到网易Java实习offer,谈谈我的学习经验
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 使用Hexo搭建个人博客的终极资料
一.前言 Hexo 是一个基于 NodeJs 博客框架,可以快速的帮我们搭建一个博客系统,Hexo使用的是Markdown(下文简称MD)解析文章的,在几秒内即可利用靓丽的主体生成静态网页. 推荐使用 ...
- 垂直居中—3行CSS3代码
方法一: .element { position: relative; top: 50%; transform: translateY(-50%); } 这用用的好处了,无论是块级元素还是行内元素,都 ...
- zabbix分布式监控部署--技术流ken
前言 zabbix proxy可以代替zabbix server检索客户端的数据,然后把数据汇报给zabbix server,并且在一定程度上分担了zabbix server的压力.zabbix pr ...
- [Linux] nginx管理员指南基本功能
1.运行时控制Nginx进程 NGINX有一个主进程和一个或多个工作进程. 如果启用了缓存,则缓存加载器和缓存管理器进程也会在启动时运行. 主进程的主要目的是读取和评估配置文件,以及维护工作进程. 工 ...
- [PHP] 算法-选择排序的PHP实现
选择排序: 1.数组分成前后两个部分,前部分是排序的,后部分是无序的 2.两层循环,先假定当前循环的第一个索引为最小值,内部循环找比该索引还小的值,找到交换 for i;i<len;i++ mi ...
- Laravel5性能优化技巧
分享一些 Laravel 开发的最佳实践,还有调优技巧,后面陆续整理中 1.配置缓存信息 使用laravel自带的artisan命令,将所有config里面的配置都缓存到一个文件里. php arti ...
- php中的for 和foreach性能对比
总体来说,如果数据库过几十万了,才能看出来快一点还是慢一点,如果低于10万的循环,就不用测试了,两者性差异不明显.但是我还是推荐用foreach.循环数字数组时,for需要事先count($arr)计 ...
- python基础学习(五)while循环语句
while循环基本使用 循环的作用就是让指定的代码重复的执行 while循环最常用的应用场景就是让执行的代码按照指定的次数重复执行 流程图 基本语法 初始条件设置 —— 通常是重复执行的 计数器 wh ...