Self Organizing Maps (SOM): 一种基于神经网络的聚类算法
自组织映射神经网络, 即Self Organizing Maps (SOM), 可以对数据进行无监督学习聚类。它的思想很简单,本质上是一种只有输入层--隐藏层的神经网络。隐藏层中的一个节点代表一个需要聚成的类。训练时采用“竞争学习”的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫“winning neuron”。 紧接着用随机梯度下降法更新激活节点的参数。同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
所以,SOM的一个特点是,隐藏层的节点是有拓扑关系的。这个拓扑关系需要我们确定,如果想要一维的模型,那么隐藏节点依次连成一条线;如果想要二维的拓扑关系,那么就行成一个平面,如下图所示(也叫Kohonen Network):
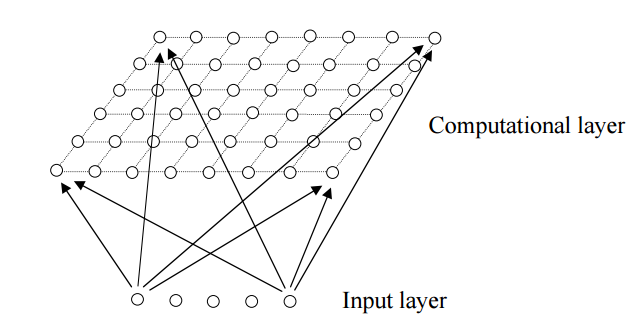
既然隐藏层是有拓扑关系的,所以我们也可以说,SOM可以把任意维度的输入离散化到一维或者二维(更高维度的不常见)的离散空间上。 Computation layer里面的节点与Input layer的节点是全连接的。
拓扑关系确定后,开始计算过程,大体分成几个部分:
1) 初始化:每个节点随机初始化自己的参数。每个节点的参数个数与Input的维度相同。
2)对于每一个输入数据,找到与它最相配的节点。假设输入时D维的, 即 X={x_i, i=1,...,D},那么判别函数可以为欧几里得距离:

3) 找到激活节点I(x)之后,我们也希望更新和它临近的节点。令S_ij表示节点i和j之间的距离,对于I(x)临近的节点,分配给它们一个更新权重:

简单地说,临近的节点根据距离的远近,更新程度要打折扣。
4)接着就是更新节点的参数了。按照梯度下降法更新:

迭代,直到收敛。
与K-Means的比较
同样是无监督的聚类方法,SOM与K-Means有什么不同呢?
(1)K-Means需要事先定下类的个数,也就是K的值。 SOM则不用,隐藏层中的某些节点可以没有任何输入数据属于它。所以,K-Means受初始化的影响要比较大。
(2)K-means为每个输入数据找到一个最相似的类后,只更新这个类的参数。SOM则会更新临近的节点。所以K-mean受noise data的影响比较大,SOM的准确性可能会比k-means低(因为也更新了临近节点)。
(3) SOM的可视化比较好。优雅的拓扑关系图 。
参考文献:http://www.cs.bham.ac.uk/~jxb/NN/l16.pdf
Self Organizing Maps (SOM): 一种基于神经网络的聚类算法的更多相关文章
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- 基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级.例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 基于ReliefF和K-means算法的医学应用实例
基于ReliefF和K-means算法的医学应用实例 数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据 ...
- 一种新型聚类算法(Clustering by fast search and find of density peaksd)
最近在学习论文的时候发现了在science上发表的关于新型的基于密度的聚类算法 Kmean算法有很多不足的地方,比如k值的确定,初始结点选择,而且还不能检测费球面类别的数据分布,对于第二个问题,提出了 ...
- 数据挖掘案例:基于 ReliefF和K-means算法的应用
数据挖掘案例:基于 ReliefF和K-means算法的应用 数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘(DataMiriing),指的是从大型数据库 ...
随机推荐
- C语言指针学习
C语言学过好久了,对于其中的指针却没有非常明确的认识,趁着有机会来好好学习一下,总结一下学过的知识,知识来自C语言指针详解一文 一:指针的概念 指针是一个特殊的变量,里面存储的数值是内存里的一个地址. ...
- 软件测试作业3--Junit、hamcrest、eclemmat的安装和使用
1. how to install junit, hamcrest and eclemma? 首先下载下来Junit和Hamcrest的jar包,然后新建项目的时候将这两个jar包导入到工程里面就 ...
- 05_最长公共子序列问题(LCS)
问题来源:刘汝佳<算法竞赛入门经典--训练指南> P60 问题7: 问题描述:给两个子序列A和B,求长度最大的公共子序列.比如1,5,2,6,8,和2,3,5,6,9,8,4的最长公共子序 ...
- xamarin.android 图片高斯模糊效果
代码如下: private static float BITMAP_SCALE = 0.1f; private static float BLUR_RADIUS = 12.0f; public sta ...
- linux alarm函数解除read write等函数的阻塞
看到apue的第十章,说到alarm,pause可以实现sleep,可以让某些一直阻塞的函数超时,例如read,write.代码如下: static void sig_alrm(int signo) ...
- 聚合数据天气预报API-ajax 通过城市名取数据
如需要,可申请聚合数据天气预报API:https://www.juhe.cn/docs/api/id/39,并生成AppKey. 接口地址:http://v.juhe.cn/weather/index ...
- Qt与VC编程合作起龌龊
由于历史原因,某软件项目的界面采用QT,而后台用了VC,界面静态调用了VC生成的dll,一直以来都能够快乐的合作,然而最近出现两个小问题,觉得两者之间的合作并没有想象的那么美好. 在VC下用多媒体定时 ...
- UESTC 914 方老师的分身I Dijkstra
题意:求有向图的往返最短路的最长长度. 分析:求第一次到所有点的距离可以用一次Dijkstra求最短路求出来.考虑回来的路,想想就知道,从每个点回来的路即为将边的方向反转再求一次最短路后的结果. 所以 ...
- HDU 2491 Priest John's Busiest Day
贪心.. #include<iostream> #include<string.h> #include<math.h> #include <stdio.h&g ...
- C/C++学习----使用C语言代替cmd命令、cmd命令大全
[开发环境] 物理机版本:Win 7 旗舰版(64位) IDE版本:Visual Studio 2013简体中文旗舰版(cn_visual_studio_ultimate_2013_with_upda ...