python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少。原因他也大概分析了下,就是后面的图片是动态加载的。他的问题就是这部分动态加载的图片该怎么爬取到。
分析
他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
data=requests.get("https://tieba.baidu.com/index.html",headers=headers)
html=BeautifulSoup(data.text,'lxml')
前面提到过,有部分图片是动态加载的,那么首先我们得弄清楚,这部分图片是怎么动态加载的。在浏览器中打开百度贴吧的首页,可以明显的看到,在往下滚动滚动条的时候,当滚动到底部的时候,滚动条缩短了,并向上移动了一段距离。这个现象也正是有DOM元素动态的添加到了html文档的一个表现。动态加载数据无非就是ajax请求,而ajax本质上就是XMLHttpRequest请求(简称xhr)。在谷歌浏览器中,我们可以通过开发者工具的network面板来监测xhr请求。
刚打开首页时的xhr请求,这里的请求都和要爬取的图片无关。
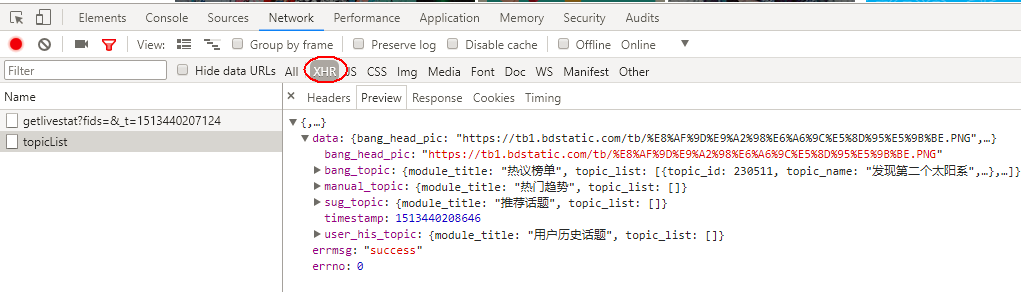
滚动条向下第1次滚动到底部,这里请求的是第20-40条热门动态,包含要爬取图片。
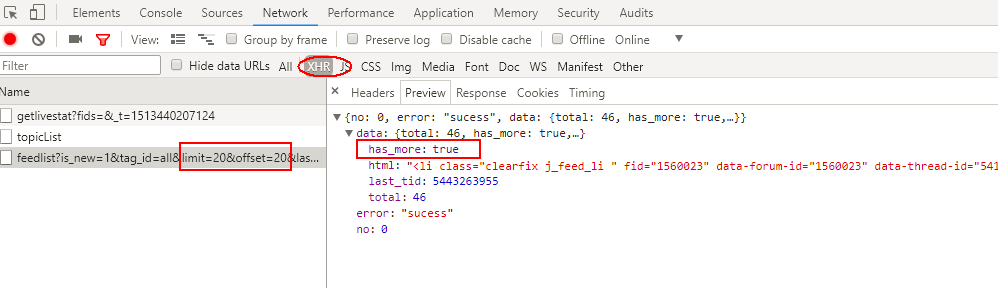
滚动条向下第2次滚动到底部,这里请求的是第40-60条热门动态,包含要爬取图片。并且返回的的has_more:false表明没有跟多数据了。
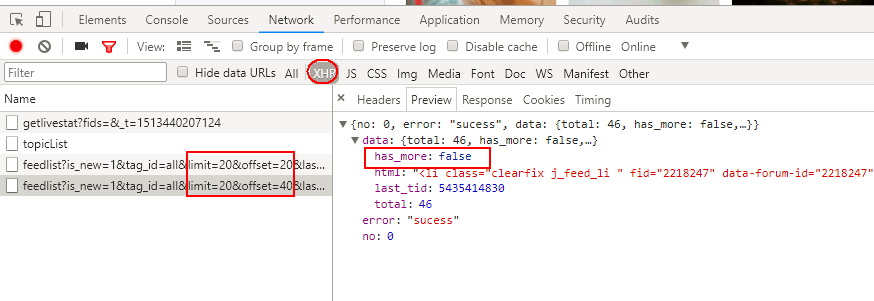
滚动条向下第3次滚动到底部,再无xhr请求。
解决方案
根据上面的分析,我们已经明白,单纯使用BeautifulSoup进行爬虫的时候,只能爬取到1-20条热门动态里面的图片。为了爬取到完整的热门动态里面的图片,我们则需要模拟浏览器的滚动条滚动,让网页去触发xhr请求更多的热门动态。
在python中,如果需要模拟浏览器的行为,可以使用selenium库。selenium库是一个自动化测试框架,可以用来模拟测试浏览器的各种行为,这里我们使用它来模拟浏览器打开百度贴吧的首页,并模拟滚动条向下滚动到底部的操作。
安装
pip install selenium
下载浏览器驱动
火狐浏览器驱动,其下载地址是:https://github.com/mozilla/geckodriver/releases
谷歌浏览器驱动,其下载地址是:http://chromedriver.storage.googleapis.com/index.html?path=2.33/
opera浏览器驱动,其下载地址是:https://github.com/operasoftware/operachromiumdriver/releases
对照自己电脑安装的浏览器和对应的版本,分别从上面的地址下载驱动文件,也可以从我的github项目中统一下载以上几个驱动(地址:https://github.com/Sesshoumaru/attachments/tree/master/Selenium WebDriver)。下载解压后,将所在的目录添加系统的环境变量中。当然你也可以将下载下来的驱动放到python安装目录的lib目录中,因为它本身已经存在于环境变量(我就是这么干的)。
使用python代码模拟浏览器行为
要使用selenium先需要定义一个具体browser对象,这里就定义的时候就看你电脑安装的具体浏览器和安装的哪个浏览器的驱动。这里以火狐浏览器为例:
from selenium import webdriver
browser = webdriver.Firefox()
再模拟打开贴吧首页:
browser.get("https://tieba.baidu.com/index.html")
再模拟滚动条滚动到底部
for i in range(1, 5):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
最后再使用BeautifulSoup,解析图片标签:
html = BeautifulSoup(browser.page_source, "lxml")
imgs = html.select("#new_list li img")
几个注意点
必须安装浏览器和浏览器驱动,并且浏览器和浏览器驱动要配到
即如果使用谷歌浏览器模拟网页行为,则需要下载谷歌浏览器驱动;
如果使用火狐浏览器模拟网页行为,则需要下载火狐浏览器驱动
浏览器驱动所在的目录要在环境变量中,或者定义浏览器
browser的时候指定驱动的路径
selenium更多用法
查找元素
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://tieba.baidu.com/index.html")
new_list = browser.find_element_by_id('new_list')
user_name = browser.find_element_by_name ('user_name')
active = browser.find_element_by_class_name ('active')
p = browser.find_element_by_tag_name ('p')
# find_element_by_name 通过name查找单个元素
# find_element_by_xpath 通过xpath查找单个元素
# find_element_by_link_text 通过链接查找单个元素
# find_element_by_partial_link_text 通过部分链接查找单个元素
# find_element_by_tag_name 通过标签名称查找单个元素
# find_element_by_class_name 通过类名查找单个元素
# find_element_by_css_selector 通过css选择武器查找单个元素
# find_elements_by_name 通过name查找多个元素
# find_elements_by_xpath 通过xpath查找多个元素
# find_elements_by_link_text 通过链接查找多个元素
# find_elements_by_partial_link_text 通过部分链接查找多个元素
# find_elements_by_tag_name 通过标签名称查找多个元素
# find_elements_by_class_name 通过类名查找多个元素
# find_elements_by_css_selector 通过css选择武器查找多个元素
获取元素信息
btn_more = browser.find_element_by_id('btn_more')
print(btn_more.get_attribute('class')) # 获取属性
print(btn_more.get_attribute('href')) # 获取属性
print(btn_more.text) # 获取文本值
元素交互操作
btn_more = browser.find_element_by_id('btn_more')
btn_more.click() # 模拟点击,可以模拟点击加载更多
input_search = browser.find_element(By.ID,'q')
input_search.clear() # 清空输入
执行JavaScript
# 执行JavaScript脚本
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
python爬虫:使用Selenium模拟浏览器行为的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- python下selenium模拟浏览器基础操作
1.安装及下载 selenium安装: pip install selenium 即可自动安装selenium geckodriver下载:https://github.com/mozilla/ge ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
随机推荐
- awk巩固练习题
第1章 awk数组练习题 1.1 文件内容(仅第一行) [root@znix test]# head -1 secure-20161219 access.log ==> secure-20161 ...
- input 密码框调出手机的数字键盘
对于某些密码,想要在手机上调出数字键盘,同时要隐藏文字.可结合type=tel和 text-security属性达到目的. input{ -webkit-text-security:disc; tex ...
- javascript中自定义事件
自定义事件:用户可以指定事件类型,这个类型实际上就是一个字符串,然后为这个类型的事件指定事件处理函数,可以注册多个事件处理函数(用数组管理),调用时,从多个事件处理函数中找到再调用. function ...
- 树莓派配置允许WINDOWS远程桌面 x11nvc+xrdp
20171109 网上很多设置教程都比较老旧,于是自己整理一下顺便分享下 开启SSH后,使用PUTTY连接. 安装x11vnc sudo apt-get install x11vnc 设置密码 sud ...
- 一起写框架-Ioc内核容器的实现-基础功能-容器对象名默认首字母小写(八)
实现功能 --前面实现的代码-- 默认的对象名就类名.不符合Java的命名规范.我们希望默认的对象名首字母小写. 实现思路 创建一个命名规则的帮助类.实现将对大写开头的对象名修改为小写开头. 实现步骤 ...
- 10个鲜为人知的C#关键字
在正式开始之前,我需要先声明:这些关键字对于偏向底层的程序员更加耳熟能详,对这些关键字不了解并不影响你作为一个合格的程序员. 这意味着这些关键字会让你在编写程序时得到更好的代码质量和可读性,enjoy ...
- 图文详解AO打印(端桥模式)
一.概述 AO打印是英文Active-Online Print的简称,也称主动在线打印.打印前支持AO通讯协议的AO打印机首先通过普通网络与C-Lodop服务保持在线链接,网页程序利用JavaSc ...
- alex python of day3
集合 # author:"Jason lincoln" list_1={1,4,5,7,3,6,7,9} list_1=set(list_1) #把集合变成列表 去重复 list_ ...
- kali 2017更新源
#阿里云deb http://mirrors.aliyun.com/kali kali-rolling main non-free contribdeb-src http://mirrors.aliy ...
- 从CentOS安装完成到生成词云python学习日记
欢迎访问我的个人博客:原文链接 前言 人生苦短,我用python.学习python怎么能不搞一下词云呢是不是(ง •̀_•́)ง 于是便有了这篇边实践边记录的笔记. 环境:VMware 12pro + ...