Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用
一、简介
二、安装
三、使用
一、简介
Selenium 是自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。Selenium 支持这些浏览器驱动。Selenium支持多种语言开发,比如 Python,Java,C,Ruby等等。
二、安装
1.安装selenium
pip3 install selenium
2.配置驱动 (下载驱动,然后将驱动文件路径配置在环境变量)
驱动下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
注意:你下载的驱动要和你浏览器版本能够兼容才能使用。
三、使用
1.声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Phantom()
browser = webdriver.FirefoxJS()
browser = webdriver.Safari()
2.访问页面
from selenium import webdriver
broswer = webdriver.Chrome()
#访问淘宝页面
broswer.get('https://www.taobao.com')
#获取页面源代码
print(broswer.page_source)
#关闭
broswer.close()
3.查找单个元素
from selenium import webdriver # 启动配置
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars') # 打开chrome浏览器
broswer = webdriver.Chrome()
broswer.get('https://www.taobao.com')
#下面三种方法都是获取同一元素
input1 = broswer.find_element_by_id('q')
input2 = broswer.find_element_by_css_selector('#q')
input3 = broswer.find_element_by_xpath('//*[@id="q"]')
print(input1,input2,input3)
broswer.close()
运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")> <selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")> <selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")>
全部获取单个元素的方法:
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_test()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
find_element_by_partial_link_test()
4.查找多个元素
from selenium import webdriver # 加启动配置
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars') # 打开chrome浏览器
broswer = webdriver.Chrome()
broswer.get('https://www.taobao.com')
input2 = broswer.find_elements_by_css_selector('#q')
print(input2)
broswer.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="0c6d5918fff4982403777d89fd64b6bd", element="0.9184632404888653-1")>]
全部获取多个元素的方法:
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_test()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
find_elements_by_partial_link_test()
5.添加User-Agent
使用webdriver,是可以更改User-Agent的,代码如下:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://www.baidu.com/')
6.自动化测试的时候,启动浏览器出现‘Chrome正在受到自动软件的控制’,可以隐藏
在浏览器配置里加个参数,忽略掉这个警告提示语,disable_infobars
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars')
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.baidu.com/')
7.启动浏览器的时候不想看的浏览器运行,那就加载浏览器的静默模式,让它在后台偷偷运行。用headless
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('headless')
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.baidu.com/')
8.获取元素信息
# 获取属性
from selenium import webdriver broswer = webdriver.Chrome()
url = 'https://www.taobao.com'
broswer.get(url)
logo = broswer.find_element_by_class_name('logo')
print(logo)
print(logo.get_attribute('class'))
# 获取文本值
from selenium import webdriver broswer = webdriver.Chrome()
url = 'https://www.taobao.com'
broswer.get(url)
li = broswer.find_element_by_class_name('J_SearchTab')
print(li)
print(li.text)
#获取ID、位置、标签名、大小
from selenium import webdriver broswer = webdriver.Chrome()
url = 'https://www.taobao.com'
broswer.get(url)
logo = broswer.find_element_by_class_name('logo')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
9.交互操作
元素交互操作(先获取特定的元素,对获取的元素调用交互方法)
from selenium import webdriver
import time # 加启动配置
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars') # 打开chrome浏览器
broswer = webdriver.Chrome()
broswer.get('https://www.taobao.com')
#获取输入框
input =broswer.find_element_by_id('q')
#模拟用户输入iphone
input.send_keys('iphone')
time.sleep(2)
#清除输入框
input.clear()
#输入ipad
input.send_keys('ipad')
#获取按钮
button = broswer.find_element_by_class_name('btn-search')
#点击按钮
button.click()
更多元素交互操作:http://selenium-python.readthedocs.org/locating-elements.html
交互动作(将动作附加到动作链中串行执行)
执行JavaScript代码
from selenium import webdriver broswer = webdriver.Chrome()
broswer.get('https://www.zhihu.com')
broswer.execute_script('window.scrollTo(0,document.body.scrollHeight)')
broswer.execute_script('alert("To Bottom")')
鼠标操作
在现实的自动化测试中关于鼠标的操作不仅仅是click()单击操作,还有很多包含在ActionChains类中的操作。如下:
- context_click(elem) 右击鼠标点击元素elem,另存为等行为
- double_click(elem) 双击鼠标点击元素elem,地图web可实现放大功能
- drag_and_drop(source,target) 拖动鼠标,源元素按下左键移动至目标元素释放
- move_to_element(elem) 鼠标移动到一个元素上
- click_and_hold(elem) 按下鼠标左键在一个元素上
- perform() 在通过调用该函数执行ActionChains中存储行为
举例如下图所示,获取通过鼠标右键另存为百度图片logo。代码:
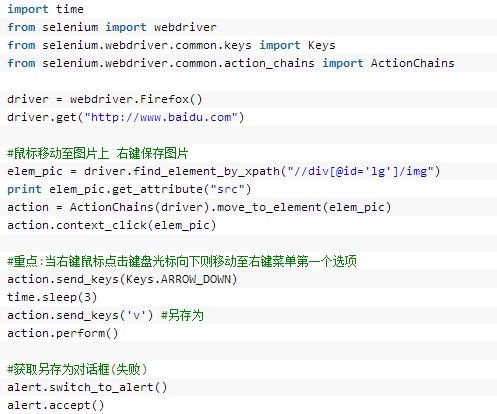
键盘操作
参考:http://selenium-python.readthedocs.org/api.html
前面讲述了鼠标操作,现在讲述键盘操作。在webdriver的Keys类中提供了键盘所有的按键操作,当然也包括一些常见的组合键操作如Ctrl+A(全选)、Ctrl+C(复制)、Ctrl+V(粘贴)。更多键参考官方文档对应的编码。
- send_keys(Keys.ENTER) 按下回车键
- send_keys(Keys.TAB) 按下Tab制表键
- send_keys(Keys.SPACE) 按下空格键space
- send_keys(Kyes.ESCAPE) 按下回退键Esc
- send_keys(Keys.BACK_SPACE) 按下删除键BackSpace
- send_keys(Keys.SHIFT) 按下shift键
- send_keys(Keys.CONTROL) 按下Ctrl键
- send_keys(Keys.ARROW_DOWN) 按下鼠标光标向下按键
- send_keys(Keys.CONTROL,'a') 组合键全选Ctrl+A
- send_keys(Keys.CONTROL,'c') 组合键复制Ctrl+C
- send_keys(Keys.CONTROL,'x') 组合键剪切Ctrl+X
- send_keys(Keys.CONTROL,'v') 组合键粘贴Ctrl+V

10.前进后退页面
import time
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get('https://www.baidu.com')
broswer.get('https://www.taobao.com')
#后退
broswer.back()
time.sleep(2)
#前进
broswer.forward()
broswer.close()
11.Cookies操作
添加Cookie
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get('https://www.zhihu.com') # Now set the cookie. This one's valid for the entire domain
cookie = {'name' : 'foo', 'value' : 'bar'}
broswer.add_cookie(cookie)
获取Cookies
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get('https://www.zhihu.com')
#获取cookie
print(broswer.get_cookies())
#添加cookie
broswer.add_cookie({'name':'name','value':'germeny'})
#再次获取cookie
print(broswer.get_cookies())
12.选项卡操作
import time
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get('https://www.zhihu.com')
#打开新窗口
broswer.execute_script('window.open()')
print(broswer.window_handles)
#切断到第二个选项卡(窗口)
broswer.switch_to_window(broswer.window_handles[1])
time.sleep(1)
#切换到第一个选项卡(窗口)
broswer.switch_to_window(broswer.window_handles[0])
broswer.get('https://www.baidu.com')
Python爬虫之selenium的使用(八)的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- python爬虫利器Selenium使用详解
简介: 用pyhon爬取动态页面时普通的urllib2无法实现,例如下面的京东首页,随着滚动条的下拉会加载新的内容,而urllib2就无法抓取这些内容,此时就需要今天的主角selenium. Sele ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- python爬虫之Selenium
Selenium的使用 #!/usr/bin/env python # -*- coding:utf-8 -*- """ Selenium是一个第三方模块,可以完全模拟用 ...
- Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1,引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一 ...
随机推荐
- Maven打包编译找不到com.sun.crypto.provider.SunJCE类
Maven配置 <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>mav ...
- B - SETI POJ - 2065 (高斯消元)
题目链接:https://vjudge.net/contest/276374#problem/B 题目大意: 输入一个素数p和一个字符串s(只包含小写字母和‘*’),字符串中每个字符对应一个数字,'* ...
- B - 低阶入门膜法 - D-query (查询区间内有多少不同的数)
题目链接:https://cn.vjudge.net/contest/284294#problem/B 题目大意:查询区间内有多少个不相同的数. 具体思路:主席树的做法,主席树的基础做法是查询区间第k ...
- B - Frogger 最短路变形('最长路'求'最短路','最短路'求'最长路')
http://poj.org/problem?id=2253 题目大意: 有一只可怜没人爱的小青蛙,打算去找他的女神青蛙姐姐,但是池塘水路不能走,所以只能通过蹦跶的形式到达目的地,问你从小青蛙到青蛙姐 ...
- CentOS和RedHat Linux的区别
RHEL 在发行的时候,有两种方式.一种是二进制的发行方式,另外一种是源代码的发行方式. 无论是哪一种发行方式,你都可以免费获得(例如从网上下载),并再次发布.但如果你使用了他们的在线升级(包括补丁) ...
- dataTable插件锁表头和锁列的教程
源代码下载 我的同事让我帮忙给弄个锁头锁列的插件.结果找到大名鼎鼎的jquery dataTable插件. 今天我们来介绍不常用的功能:dataTable插件锁表头和锁前两列 由于是移动前端.我们不考 ...
- sipML5聊天功能实现
一.环境说明:在阅读sipML5的API文档时,发现它具有聊天的功能,于是在sipML5的源码中进行设定,实现了注册之后可以英文聊天(中文聊天需要在FreeSWITCh中进行设定). 二.具体配置: ...
- PYTHON-UDP
1.TCP 和 UDP 发送数据时的流程 ***** 解释 为何TCP是可靠的 是因为发送数据后必须收到确认包 2. UDP的模板代码 ***** 1.UDP协议: (数据报协议) 特点: 无连接 优 ...
- php-fpm 配置文件检测
用过 Nginx 的兄弟都知道,修改 Nginx 配置文件之后,可以使用 nginx -t 来检测配置文件是否有语法错误. 今天配置 opcache 的时候,发现 php-fpm 也可以检测 php- ...
- python易错题之作用域
name = "lzl" def f1(): print(name) def f2(): name = "eric" f1() f2() //结果为 lzl 记 ...