机器学习之二:K-近邻(KNN)算法
一、概述
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
二、原理
基本思路是:如果一个样本在特征空间中的 k 个最相似即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
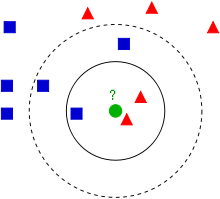
三、优缺点
1、优点:
1)精度高,对异常值不敏感、无数据输入假定;
2)KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。
3)由于 KNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN 方法较其他方法更为适合。
4)KNN 算法不仅可以用于分类,还可以用于回归。
2、缺点:
1)计算复杂度高:KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
2)空间复杂度高:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
四、注意的问题
1、K的选择
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
2、距离衡量
常用的欧氏距离,马氏距离,夹角余弦距离等。
3、分类样本平衡
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。此时可压缩样本较多的数据类别,或者采用权重系数评判测试点属于哪个类别
五、算法步骤
1)算距离:计算已知类别数据集中的点与当前点之前的距离;
2)找邻居:找出距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻出现频率最高的类别作为测试对象的预测分类
六、示例代码(Python)
from numpy import *
import operator
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
print 'dataSetSize=',dataSetSize
diffMat = tile(inX,(dataSetSize,1)) - dataSet
print tile(inX,(dataSetSize,1))
print 'diffMat=',diffMat
sqDiffMat = diffMat**2
print 'sqDiffMat=',sqDiffMat
sqDistances = sqDiffMat.sum(axis=1)
print 'sqDistances=',sqDistances
distances = sqDistances**0.5
print 'distances=',distances
sortedDistIndicies = distances.argsort()
print sortedDistIndicies
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
print sortedClassCount
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
group,labels = createDataSet()
print classify0([0,0],group,labels,3)
七、算法行业应用
八、算法的相关改进
KD树,样本压缩技术
九、参考文献
http://www.stanford.edu/~hastie/Papers/dann_IEEE.pdf
机器学习之二:K-近邻(KNN)算法的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- TensorFlow实现knn(k近邻)算法
首先先介绍一下knn的基本原理: KNN是通过计算不同特征值之间的距离进行分类. 整体的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于 ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
随机推荐
- Linux SSH下安装Java并设置环境
我是用Xshell进行远程连接阿里云服务器的,所以jdk不好下载. 我使用的是Winscp远程软件,在window上下载了jdk然后再上传到Linux服务器上 下面是安装的步骤 1.下载jdk8 登录 ...
- <c:forEach>+<c:if>
<c:forEach>:用来做循环<c:if>:相当于if语句用于判断执行,如果表达式的值为 true 则执行其主体内容. <c:forEach var="每个 ...
- JVM 菜鸟进阶高手之路九(解惑)
转载请注明原创出处,谢谢! 在第八系列最后有些疑惑的地方,后来还是在我坚持不懈不断打扰笨神,阿飞,ak大神等,终于解决了该问题.第八系列地址:http://www.cnblogs.com/lirenz ...
- Python之面向对象与类
本节内容 面向对象的概念 类的封装 类的继承 类的多态 静态方法.类方法 和 属性方法 类的特殊成员方法 子类属性查找顺序 一.面向对象的概念 1. "面向对象(OOP)"是什么? ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
- Tomcat启动一闪而过
问题: 在下载tomcat7纯净版之后,配置完环境变量.运行startup.bat,一闪而过tomcat没有启动成功. 解决办法: 设置CLASSPATH.环境变量设置JAVA_HOME为java安装 ...
- Springmvc学习笔记(一)
一.sprinvmvc的介绍 1.1.Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面.Spring 框架提供了构建 Web 应用程序的全 ...
- Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://sc ...
- Quartz.NET实现作业调度
一.Quartz.NET介绍 Quartz.NET是一个强大.开源.轻量的作业调度框架,是 OpenSymphony 的 Quartz API 的.NET移植,用C#改写,可用于winform和asp ...
- 实现LAMP
实现LAMP 1.LAMP工作原理 LAMP是一个强大的Web应用程序平台,其中L是指linux系统:A是指apache也就是http;M一般是mysql/mariadb数据库;P一般是php, pe ...