ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression笔记
前言
致力于滤波器的剪枝,论文的方法不改变原始网络的结构。论文的方法是基于下一层的统计信息来进行剪枝,这是区别已有方法的。
VGG-16上可以减少3.31FLOPs和16.63倍的压缩,top-5的准确率只下降0.52%。在ResNet-50上可以降低超过一半的参数量和FLOPs,top-5的准确率只降低1%。
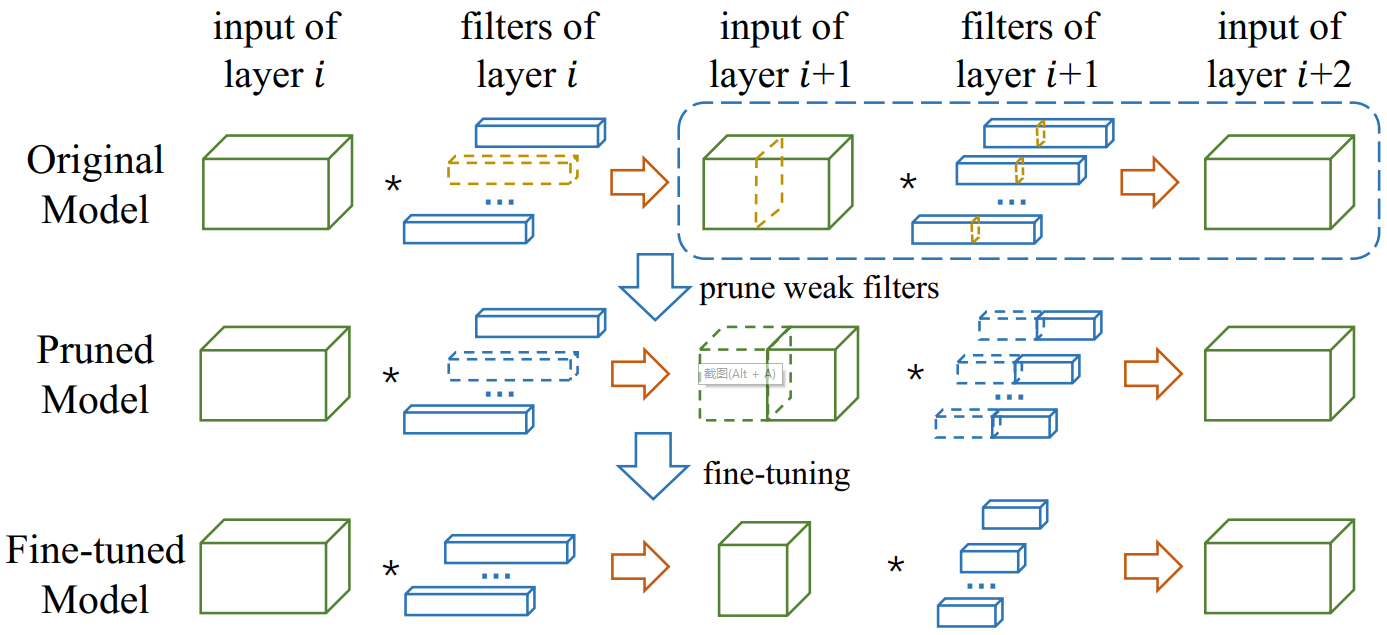
如上图所示,在虚线框中找到那些弱通道(weak channels)和他们对应的滤波器(黄色高亮部分),这些通道和对应的滤波器对整体性能贡献较小,因此可以丢弃,这样就得到一个剪枝后的模型,然后通过微调(fine-tune)恢复模型的准确率。
ThiNet框架
(1)滤滤波器选择
不同于已有的方法(使用layer(i)层的统计数据对layer(i)滤波器进行剪枝),论文对layer(i+1)的统计信息来对layer(i)层进行剪枝。思路如下:如果可以使用layer(i+1)的子集通道(subset channels)的输入来逼近layer(i+1)的输出,那么其它的通道就可以从layer(i+1)的输入移除,而layer(i+1)的输入是由layer(i)的滤波器产生的。
(2)剪枝
在layer(i+1)的弱通道和其对应的layer(i)层的滤波器将被去除,模型将变得更小。剪枝后的网络的结构不变,但拥有较少的滤波器和通道数。
(3)微调
通过大量数据的训练来恢复网络性能
数据驱动的通道选择
使用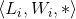 来表示layer(i)的卷积过程,其中
来表示layer(i)的卷积过程,其中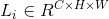 表示输入的张量(tensor),
表示输入的张量(tensor), 是一组KxK的核大小的滤波器,使用D个channels生成新的张量。
是一组KxK的核大小的滤波器,使用D个channels生成新的张量。
我们的目标是移除 中不重要的滤波器。可以看出,如果
中不重要的滤波器。可以看出,如果 中的一个滤波器被移除了,在
中的一个滤波器被移除了,在 和
和 中相应的通道也会被移除。这样的操作下,layer(i+1)的滤波器的数目和他输出张量的大小保持不变,因此
中相应的通道也会被移除。这样的操作下,layer(i+1)的滤波器的数目和他输出张量的大小保持不变,因此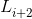 也保持不变。
也保持不变。
收集训练样本
通道选择——贪心算法
最小化重构误差
ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression笔记的更多相关文章
- 论文笔记——ThiNet: A Filter Level Pruning Method for Deep Neural Network Compreesion
论文地址:https://arxiv.org/abs/1707.06342 主要思想 选择一个channel的子集,然后让通过样本以后得到的误差最小(最小二乘),将裁剪问题转换成了优化问题. 这篇论文 ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 用matlab训练数字分类的深度神经网络Training a Deep Neural Network for Digit Classification
This example shows how to use Neural Network Toolbox™ to train a deep neural network to classify ima ...
- 深度神经网络如何看待你,论自拍What a Deep Neural Network thinks about your #selfie
Convolutional Neural Networks are great: they recognize things, places and people in your personal p ...
- A Survey of Model Compression and Acceleration for Deep Neural Network时s
A Survey of Model Compression and Acceleration for Deep Neural Network时s 本文全面概述了深度神经网络的压缩方法,主要可分为参数修 ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- What are the advantages of ReLU over sigmoid function in deep neural network?
The state of the art of non-linearity is to use ReLU instead of sigmoid function in deep neural netw ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
随机推荐
- Mac 10.9.3 自带PHP5.4.24增加redis和xdebug扩展
git clone git://github.com/nicolasff/phpredis.git cd ./phpredis phpize make ./configure make sudo ma ...
- swift protocol 见证容器 虚函数表 与 动态派发
一.测试代码: //protocol DiceGameDelegate: AnyObject { //} // //@objc protocol OcProtocol{ // @objc fun ...
- go标准库的学习-database/sql/driver
参考:https://studygolang.com/pkgdoc 1>导入方式: import "database/sql/driver" driver包定义了应被数据库驱 ...
- esp-adf Element PipeLine
audio_element: 开发基于ADF的程序软件最基本的模块就是audio_element对象.所有的编码.解码.过滤.输入流.输出流实际上都是audio_element.(这个是官方的文件我翻 ...
- Python threading中lock的使用
版权声明: https://blog.csdn.net/u012067766/article/details/79733801在多线程中使用lock可以让多个线程在共享资源的时候不会“乱”,例如,创建 ...
- Saltstack学习之二:target与模块方法的运行
对象的管理 saltstack系统中我们的管理对象叫做target,在master上我们可以采用不同的target去管理不同的minion,这些target都是通过去管理和匹配minion的id来做的 ...
- (转)用graph-easy描绘kubenetes描绘k8s组件逻辑图
1.参考: https://xuxinkun.github.io/2018/09/03/graph-easy/ http://bloodgate.com/perl/graph/manual/faq.h ...
- 开源HTTP解析器---http-parser和fast-http
由于项目中遇到需要发送http请求,然后再解析接收到的响应.大概在网上搜索了一下,有两个比较不错,分别是http-parser和fast-http. http-parser是由C编写的工具:fast- ...
- [06] Bean属性的注入
之前我们提到了Bean实例化的三种方式:构造器方式.静态工厂方式.普通工厂方式.那么对于Bean中的属性,又是如何进行注入的(依赖注入),这个篇章就来提一提. 1.先提提什么是"依赖注入&q ...
- android 环境的配置
经过了长达好几天的她探索,一直出现各种问题,然后,也是一个一个的解决,但最后,解决烦了,就觉得重新开始配置android的环境了. 原来一直都是版本的问题,因为我之前下载的都是2014的版本,而这个版 ...