python爬虫简单代码爬取郭德纲单口相声
搜索老郭的单口相声,打开检查模式,刷新
没有什么有价值的东东, 不过....清掉内容, 点击一个相声,再看看有些什么
是不是发现了些什么
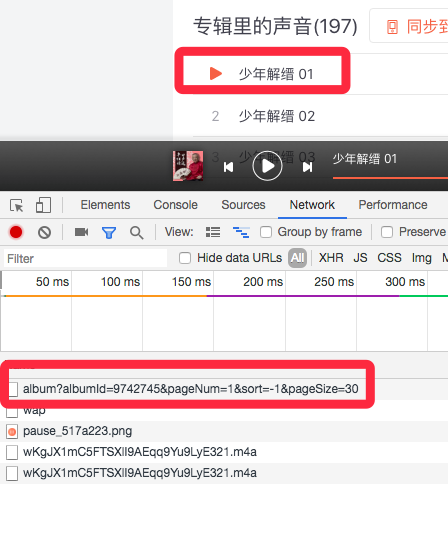
我们来点击这个看看, 首先看一下headers, 这个url是不是看起来很顺眼
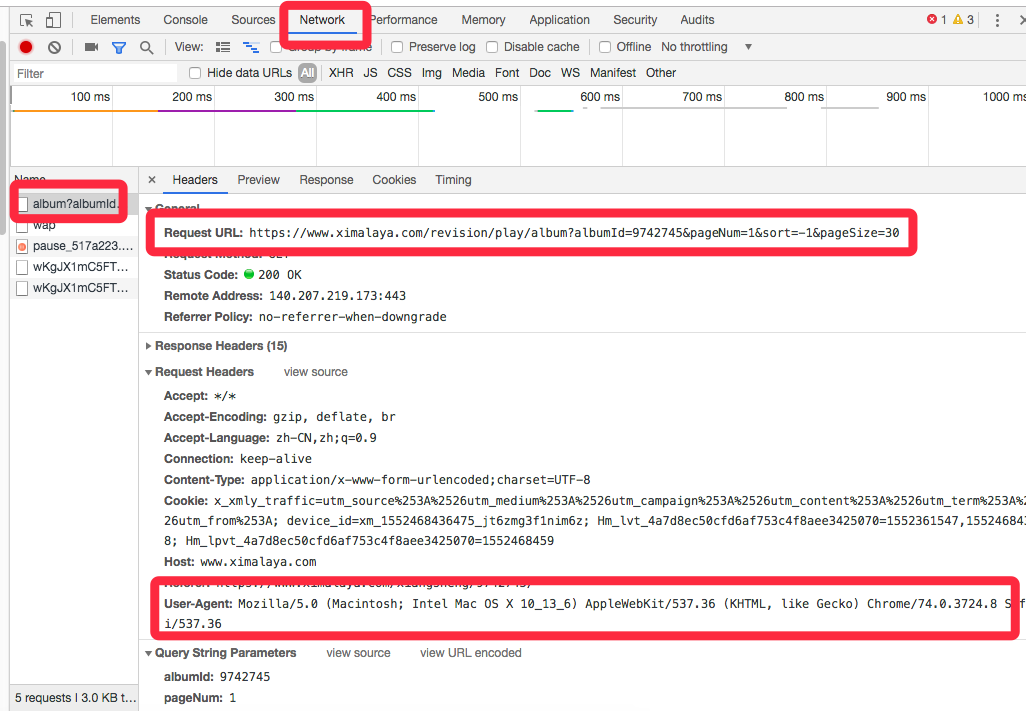
再来preview, 或者打开那个Request URL
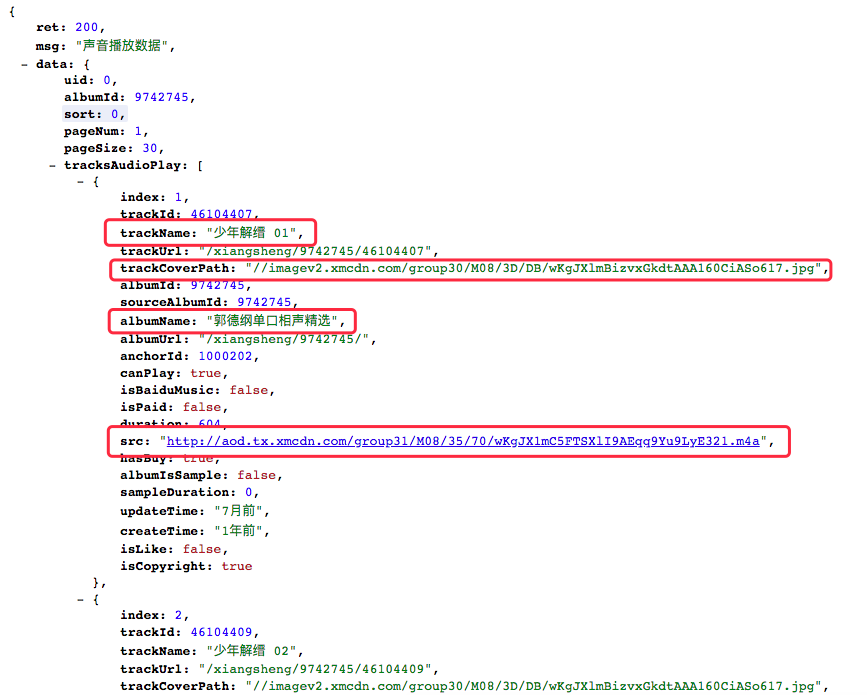
# -*- coding:utf-8 -*-
# Author : Niuli
# Data : 2019-03-13 16:08 import requests,os # 数据来源
URL = 'https://www.ximalaya.com/revision/play/album?albumId=9742745&pageNum=1&sort=-1&pageSize=30'
# 伪造请求头
XMLY_HEADER = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'} res = requests.get(URL,headers=XMLY_HEADER)
res_json = res.json() play_list = res_json['data']['tracksAudioPlay']
ALL_PATH = play_list[0]['albumName'] # 创建本地专辑文件夹
os.system(f'mkdir -p {ALL_PATH}/MUSIC')
os.system(f'mkdir -p {ALL_PATH}/COVER') MUSIC_PATH = ALL_PATH + '/MUSIC'
COVER_PATH = ALL_PATH + '/COVER' for i in play_list:
# print(i['trackName'])
# print(i['trackCoverPath'])
# print(i['src']) # 获取文件信息 (标题 音乐路径 图片路径)
url_title = i['trackName']
url_music_path = i['src']
url_cover_path = 'https:' + i['trackCoverPath'] # 下载保存音乐文件
music_file = requests.get(url_music_path) # 下载文件
local_music_path = os.path.join(MUSIC_PATH,f'{url_title}.mp3') # 保存路径+文件名+后缀
# 写入音乐文件
with open(local_music_path,'wb') as f:
f.write(music_file.content) # 下载保存图片信息
cover_file = requests.get(url_cover_path) # 下载文件
local_cover_path = os.path.join(COVER_PATH,f'{url_title}.jpg') # 保存路径+文件名+后缀
# 写入图片文件
with open(local_cover_path, 'wb') as f:
f.write(cover_file.content)
同理可以获取其他音频咯
python爬虫简单代码爬取郭德纲单口相声的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- Centos7.0进入单用户模式修改root密码
启动Centos7 ,按空格让其停留在如下界面. 按e进行编辑 在UTF-8后面输入init=/bin/sh 根据提示按ctrl+x 得如下图 输入mount -o remount,rw / 然后输 ...
- PMP:3.项目经理角色
成员角色:整合指挥者 在团队中的职责:负终责 知识技能:综合技能&沟通 定义: 职能经理专注于对某个职能领域或业务部门的管理监督. 运营经理负责保证业务运营的高效性. 项目经理是由执行组织 ...
- 调用opencv相关函数,从视频流中提取出图片序列&&&&jpg图片序列,转化成avi格式视频
/************************ @HJ 2017/3/30 参考http://blog.sina.com.cn/s/blog_4b0020f301010qcz.html修改的代码 ...
- 171. Excel表列序号
题目:给定一个Excel表格中的列名称,返回其相应的列序号. 例如, A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> ...
- 2018.09.22 上海大学技术分享 - An Introduction To Go Programming Language
老实说笔者学习 Go 的时间并不长,积淀也不深厚,这次因缘巧合,同组的同事以前是上海大学的开源社区推动者之一,同时我们也抱着部分宣传公司和技术分享的意图,更进一步的,也是对所学做一个总结,所以拟定了这 ...
- Linux程序设计:进程通信
日期:忘了. 关键词:Linux程序设计:System-V:进程通信:共享内存:消息队列. 一.共享内存 1.1 基本知识 (待补充) 1.2 代码 一个基于share memory实现的 ...
- Javascript高级编程学习笔记(9)—— 执行环境
今天主要讲一下,JS底层的一些东西,这些东西不太好举例(应该是我水平不够) 望大家多多海涵,比心心 执行环境 执行环境(执行上下文,全文使用执行环境 )是JS中最为重要的一个概念,执行环境决定了,变量 ...
- 判断字符串是否为正整数 & 浮点小数
/** * 判断字符串是否为数字(正整数和浮点数) * @param str * @return */public static boolean isNumeric(String str) { Str ...
- 锚接口(上)——hashchange api 和 $.uriAnchor
概述 这是我在单页Web应用这本书上看到的方法,并深入的研究了一下,把结果记录在下面,供以后开发时参考,相信对其它人也有用. 说明一下,这个方法已经过时了,H5有更新的方法:history api,我 ...
- 腾讯Alloy团队代码规范
概述 我个人很看重代码规范,因为代码是写给别人看的,按规范写别人才更容易理解.之前苦于没有代码规范的资料,现在在github上面看到了腾讯Alloy团队的代码规范,于是学习了一下,并记录下我自己还没怎 ...