MongoDB 的安装和基本操作
MongoDB 的安装
使用 docker 安装
下载镜像:
docker pull mongo:4.4.8(推荐,下载指定版本)
docker pull mongo:latest (默认下载最新版本)
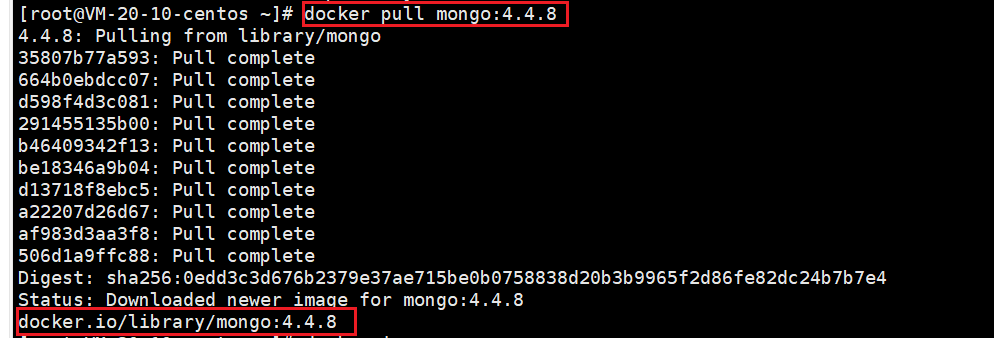
查看镜像:
docker images
- 可以看到 mongo 已经下载好了
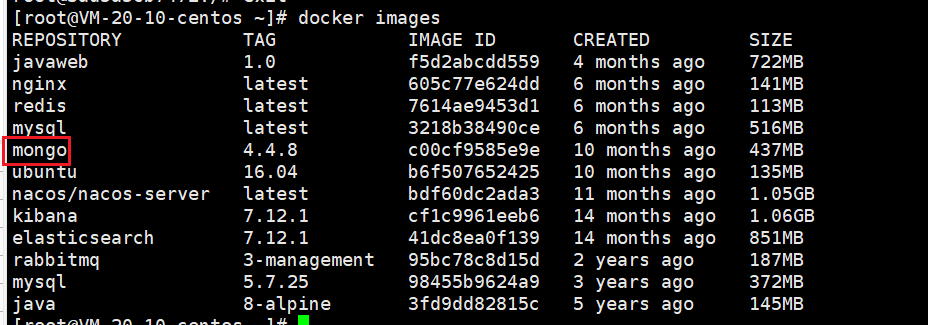
启动镜像:
docker run -d --restart=always -p 27017:27017 --name mymongo -v /data/db:/data/db mongo:4.4.8
- -d 后台运行
- --restart=always docker 容器启动 mongo 也启动 关闭也是如此
- -name 指定容器的名称
- -v 和磁盘的的某个文件绑定起来
进入容器:
docker exec -it mymongo /bin/bash
进入到 mongo 的客户端
mongo

MongoDB 概念解析
不管我们学习什么数据库都应该学习其中的基础概念,在 mongodb 中基本的概念是文档、集合、数据库,下面我们详细介绍,下表将帮助您更容易理解 Mongo 中的一些概念:
| SQL 术语/概念 | MongoDB 术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB 不支持 | |
| primary key | primary key | 主键,MongoDB 自动将_id 字段设置为主键 |
MongoDB 常用操作
(1)Help 查看命令提示
db.help();
(2)切换/创建数据库
use test
如果数据库不存在,则创建数据库,否则切换到指定数据库
(3) 查询所有数据库
show dbs;
(4)删除当前使用数据库
db.dropDatabase();
(5)查看当前使用的数据库
db.getName();
(6)显示当前 db 状态
db.stats();
(7)当前 db 版本
db.version();
(8) 查看当前 db 的链接机器地址
db.getMongo();
常用指令:
我们先创建一个数据库
use test
1 INSERT(新增)
插入到 User 集合中
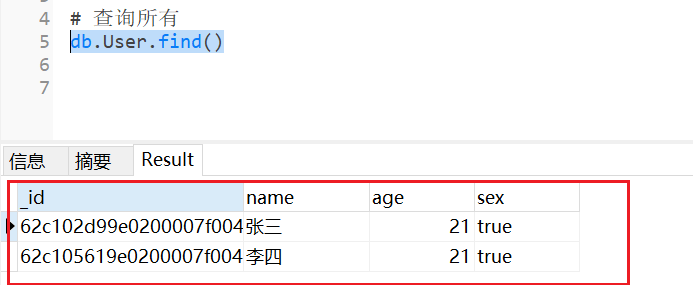
db.User.save({name:'zhangsan',age:21,sex:true})
查询 User 集合中的所有文档
db.User.find()
2 Remove(删除)
remove()用于删除单个或全部文档,删除后的文档无法恢复
- 删除所有:db.User.remove({})
- 指定 id 删除:db.User.remove(id)
- 指定条件删除:db.User.remove({'name':'zhangsan'})
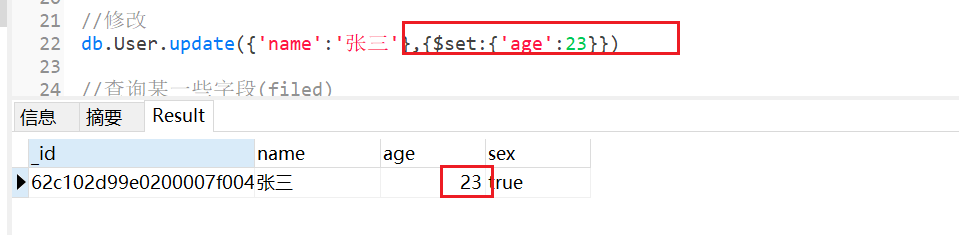
3 UPDATE (修改)
- 第一个 { } 是条件
- 第二个大括号 是需要修改的内容
示例:db.User.update({name:"lucy"}, {$set:{age:100, sex:0}})
Update()有几个参数需要注意。
db.collection.update(criteria, objNew, upsert, mult)
criteria:需要更新的条件表达式
objNew:更新表达式
upsert:如 FI 标记录不存在,是否插入新文档。
multi:是否更新多个文档。
4 QUERY(查询)
4.1 WHERE
在 mongo 中 我们该如何使用条件查询呢?
语法 :db.User.find ({"filed",值})
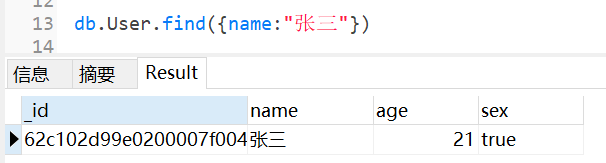
示例: db.User.find({name:"张三"})
转换成 sql : select * form User where name = '张三'
4.2 FIELDS
在正常开发中,只需要查询出一个集合中的某几个字段即可?那么这样的业务我们该如何去实现呢?
- 第一个{}表示 什么条件去查询 就是上面的 where
- 第二个{}表示 需要查询出的 field 值为 1
语法 :db.User.find ( { } , { "filed" , 值 })
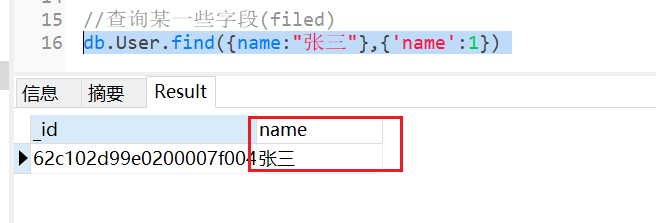
示例:db.User.find( { name : "张三" } , { 'name' : 1 } )
转换成 sql: select name from User where name = '张三'
5 SORT
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
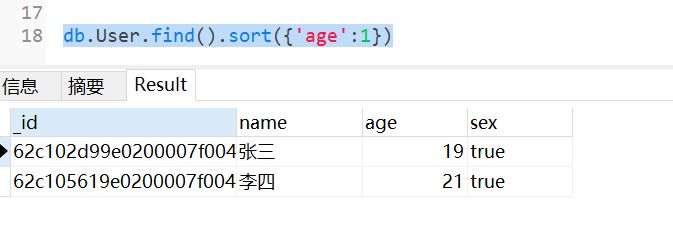
示例:db.User.find().sort({'age':1})
转换的 SQL :select * from User order by age desc
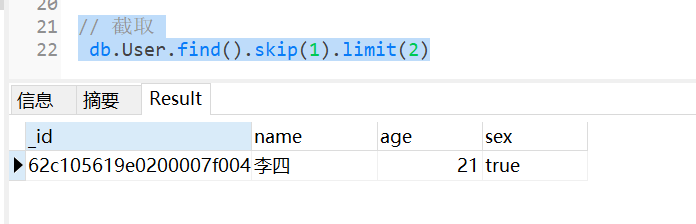
6 截取
在 MongoDB 中使用 limit()方法来读取指定数量的数据,skip()方法表示从第几行开始读取
示例: db.User.find().skip(1).limit(2)
对应的 SQL: select * from User skip 1 limit 2
集合中的所有数据:一共两条
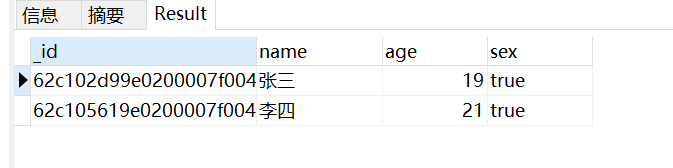
第一行开始读取 读取到第二行结束
7 in(包含)
示例: db.User.find({age:{$in:[21,26,32]}})
转换的 SQL:select * from User where age in (21, 26, 32)
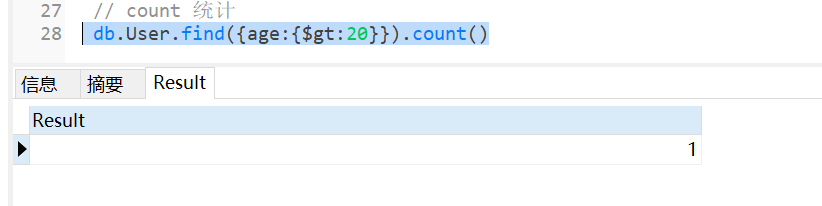
8 COUNT(统计行数)
示例: select count(*) from User where age >20
转换的 SQL: db.User.find({age:{$gt:20}}).count()
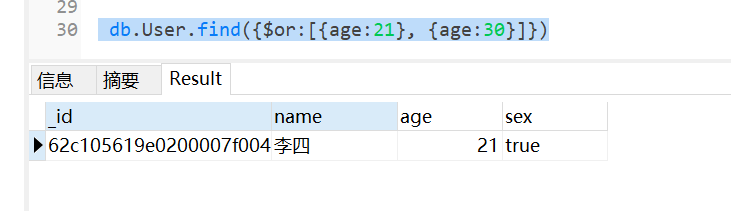
9 OR ( 或者)
age 是 20 或者 30 都满足条件 类似于 |
示例: select * from User where age = 21 or age = 30
转换的 SQL: db.User.find({$or:[{age:21}, {age:30}]})
10 aggregate(聚合)
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)
插入测试数据
db.article.insert({title: 'MongoDB Overview',description: 'MongoDB is no sql database',by_user: 'runoob.com',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100})
db.article.insert({title: 'NoSQL Overview',description: 'No sql database is very fast',by_user: 'runoob.com',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 10})
db.article.insert({title: 'Neo4j Overview',description: 'Neo4j is no sql database',by_user: 'Neo4j',url: 'http://www.neo4j.com',tags: ['neo4j', 'database', 'NoSQL'],likes: 750})
常见的聚合表达式
| 表达式 | 描述 | 示例 |
|---|---|---|
| $sum | 计算总和 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
11 索引
索引通常能够极大的提高
查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
db.User.createIndex({"name":1})
语法中 **name****值为你要创建的索引字段,
1** 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可
MongoDB 的安装和基本操作的更多相关文章
- MongoDB的安装和基本操作
一.使用前的准备(windows下的安装) 1.下载 目前MongoDB的官网不知道问什么不能进行下载了,但是可以在MongoDB中文论坛进行下载, 地址如下:http://www.mongoing ...
- MongoDB的安装、基本操作
此说明文档针对的community版本是v4.2.0(1)下载下载官网,此时的community版本是v4.2.0https://www.mongodb.com/download-center/com ...
- Linux系统下MongoDB的简单安装与基本操作
这篇文章主要介绍了Linux系统下MongoDB的简单安装与基本操作,需要的朋友可以参考下 Mongo DB ,是目前在IT行业非常流行的一种非关系型数据库(NoSql),其灵活的数据存储方式,备 ...
- MongoDB的安装配置、基本操作及Perl操作MongoDB
MongoDB的安装配置.基本操作及Perl操作MongoDB http://www.myhack58.com/Article/60/63/2014/42353.htm
- MongoDB与RoboMongo的安装+python基本操作MongoDB
MongoDB(来自于英文单词“Humongous”,中文含义为“庞大”)是可以应用于各种规模的企业.各个行业以及各类应用程序的开源数据库.作为一个适用于敏捷开发的数据库,MongoDB的数据 ...
- mongodb(二) 安装和使用
mongodb的安装和使用 最近的项目需要使用到mongodb,从而开始熟悉nosql,有了本篇文章,记录和方便他人. mongodb的安装 下载地址:http://www.mongodb.org/d ...
- mongoDB的安装及基本使用
1.mongoDB简介 1.1 NoSQL数据库 数据库:进行高效的.有规则的进行数据持久化存储的软件 NoSQL数据库:Not only sql,指代非关系型数据库 优点:高可扩展性.分布式计算.低 ...
- python操作三大主流数据库(7)python操作mongodb数据库①mongodb的安装和简单使用
python操作mongodb数据库①mongodb的安装和简单使用 参考文档:中文版:http://www.mongoing.com/docs/crud.html英文版:https://docs.m ...
- MongoDB文档的基本操作
1. MongoDB的安装方法 (1)下载MongoDB 相应的版本: (2)设置数据文件和日志文件的存放目录: (3)启动MongoDB服务: (4)将MongoDB作为服务启动. 2. Mongo ...
随机推荐
- python 多进程共享全局变量之Manager()
Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和A ...
- Apache Hudi 如何加速传统的批处理模式?
1. 现状说明 1.1 数据湖摄取和计算过程 - 处理更新 在我们的用例中1-10% 是对历史记录的更新.当记录更新时,我们需要从之前的 updated_date 分区中删除之前的条目,并将条目添加到 ...
- TCP 连接的建立 & 断开
TCP 连接的建立过程 一开始,客户端和服务端都处于 close 状态. 先是服务端监听某个端口,此时服务端处于 listen 状态. 这个时候客户端就可以发送连接请求报文了. 第一次握手 客户端会主 ...
- 超耐心地毯式分析,来试试这道看似简单但暗藏玄机的Promise顺序执行题
壹 ❀ 引 就在昨天,与朋友聊到JS基础时,她突然想起之前在面试时,遇到了一道难以理解的Promise执行顺序题.由于我之前专门写过手写promise的文章,对于部分原理也还算了解,出于兴趣我便要了这 ...
- Linux网卡绑定bond0-实验
虚拟机添加网卡 ip addr 查看新增的网卡是否读取 添加bonding接口 [root@centos8~]$nmcli con add type bond con-name mybond0 ifn ...
- Unity实现简单的对象池
一.简介 先说说为什么要使用对象池 在Unity游戏运行时,经常需要生成一些物体,例如子弹.敌人等.虽然Unity中有Instantiate()方法可以使用,但是在某些情况下并不高效.特别是对于那些需 ...
- 聊聊 HTTPS
聊聊 HTTPS 本文写于 2021 年 6 月 30 日 最近工作也是越来越忙了,不像上学的时候,一天下来闲着没事可以写两篇博客. 今天来聊一下 HTTPS. HTTP HTTP 是不安全的协议. ...
- CentOS6.x静默安装Oracle12c
一.准备 1.1 安装环境 系统要求 内存 > 2G 安装目录空间 > 6.5G /tmp目录空间 > 1G 操作系统 cat /etc/redhat-release 用rpm命令确 ...
- 292. Nim Game - LeetCode
Question 292. Nim Game Solution 思路:试着列举一下,就能发现一个n只要不是4的倍数,就能赢. n 是否能赢 1 true 2 true 3 true 4 false 不 ...
- CentOS7防火墙firewalld的配置
开机启动的开启与禁止 # 开机启动 systemctl enable firewalld # 禁止开机启动 systemctl disable firewalld 基本操作 # 查看状态 system ...