Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算
Pandas 继承了Numpy的功能,也实现了一些高效技巧。
- 对于1元运算,(函数,三角函数)保留索引和列标签
- 对于2元运算,(加法,乘法),Pandas 会自动对齐索引进行计算。
通用函数:保留索引
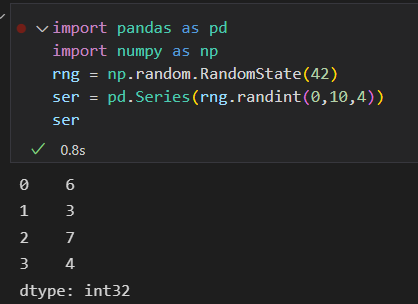
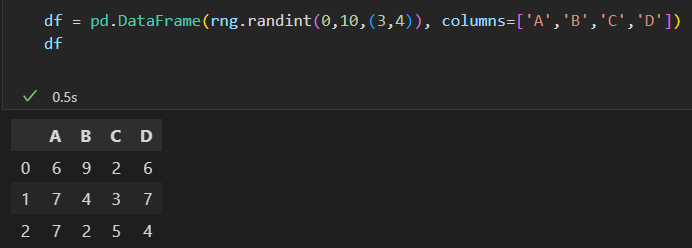
对ser对象或 df对象使用Numpy通用函数,生成的结果是另一个保留索引的Pandas对象。
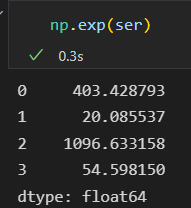
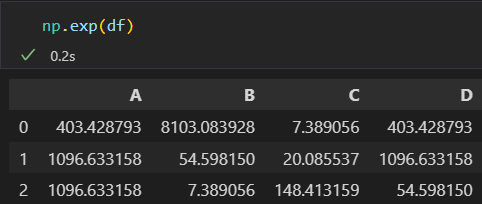
通用函数: 索引对齐
当Series 或 DataFram对象进行二元计算,会对齐俩个对象的索引
当处理不完整的额数据时,这一点非常方便
Series索引对齐
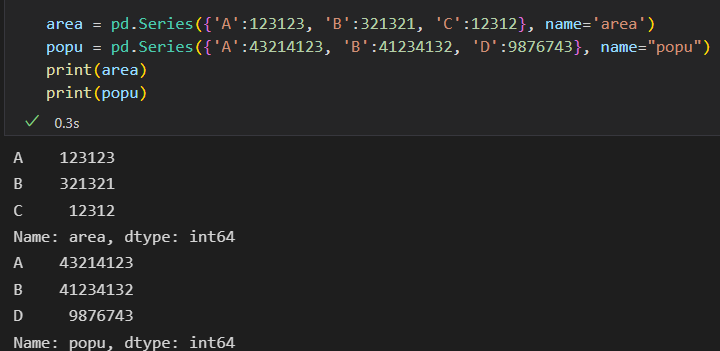
俩个相除
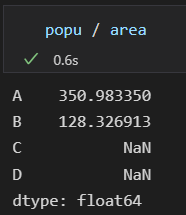
结果数组索引是:俩个输入数组索引的并集,
对于确实位置的数据,Pandas会用NaN填充,表示此处无数。
DataFrame索引对齐
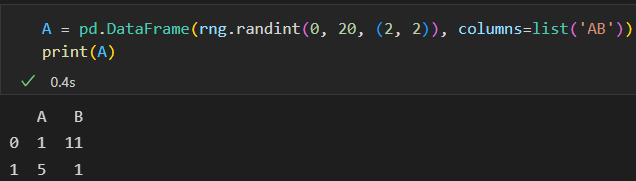
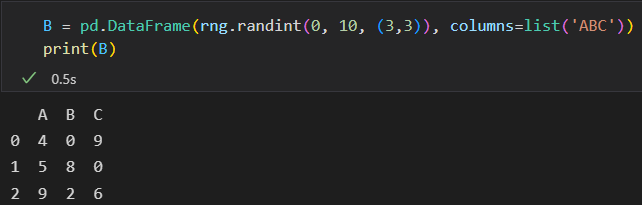
A + B
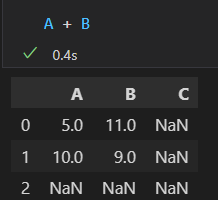
行列索引的顺序可以不同。结果的索引会自动按顺序排列。
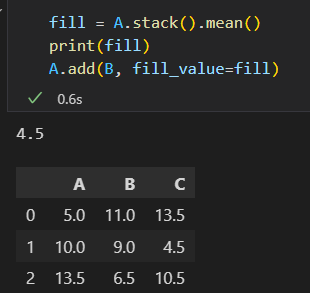
可以通过fill_value 参数自定义缺失值,注意:fill_value填充在A上,然后与B相加,不是运算之后再填fill_value.
DataFrame 与 Series的运算
需要对一个DataFrame和一个Series运算,行列对齐方式与之前类似, 与Numpy 二维数组与一维数组的运算规则是一样的。
广播。
numpy 二维数组和一维数组计算
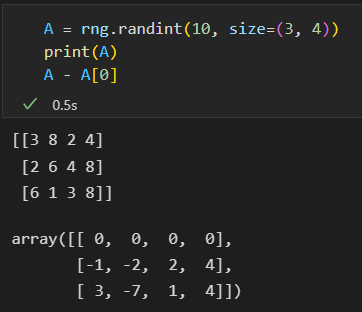
默认按行运算。
Pandas也是默认按行运算
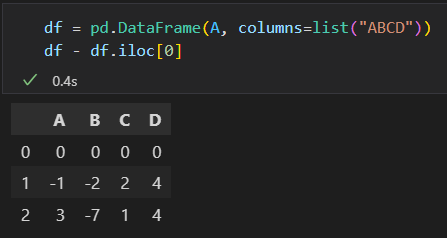
按列计算,使用axis参数。
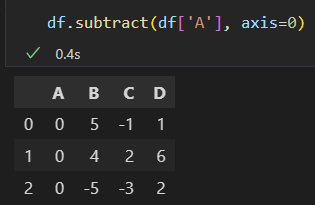
处理缺失值
缺失值三种形式:null NaN NA
识别缺失值的方法:
1)覆盖全局的掩码
2)用一个标签值
Pandas的缺失值
综合考量:Pandas最终选择标签方法表示缺失值。 浮点数据类型的NaN值,以及None对象。
- None: Python对象类型的缺失值
由于None是一个Python对象,所以不能作为任何Numpy/Pandas数组类型的缺失值。
Python中没有定义None和整数之间的加法运算 - NaN:数值类型的缺失值
NaN: not a number. 任何系统中都兼容的特殊浮点数
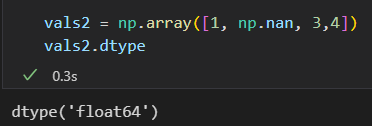
NaN是一个数据类病毒,会同化和它接触的数据, 进行何种操作,结果都是NaN
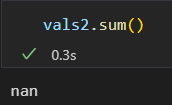
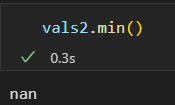
Numpy也提供了特殊的累计函数,可以忽略缺失值的影响
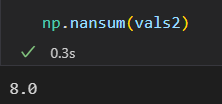
np.nansum() nanmin() nanmax()
处理缺失值
- 发现缺失值 isnull() notnull()
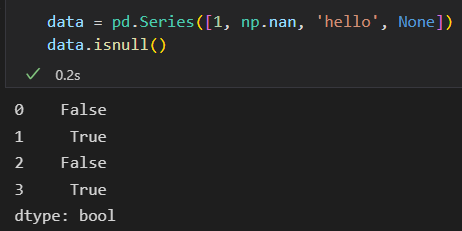
isnull() 创建一个布尔类型的掩码标签 缺失值
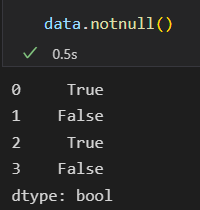
notnull() 与 isnull()相反
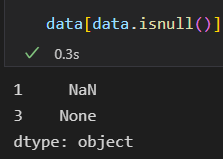
布尔类型掩码数组可以直接作为Series或DataFrame的索引使用
剔除缺失值 dropna()
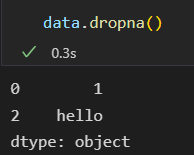
DataFrame 不太一样哦。
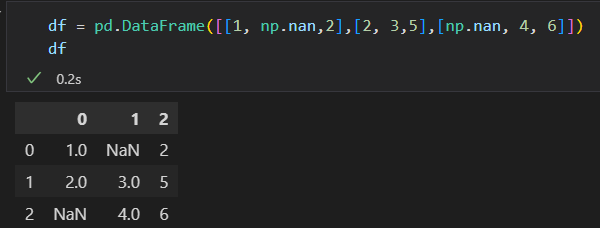
我们没法从datafram单独剔除一个值。要么是整行,要么是整列。
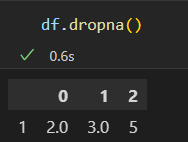
dropna()会剔除任何包含缺失值的整行数据
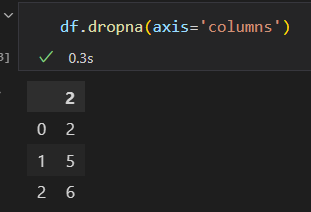
剔除列,axis=1 or axis = 'columns'
行或列全部是缺失值 剔除使用how=any,
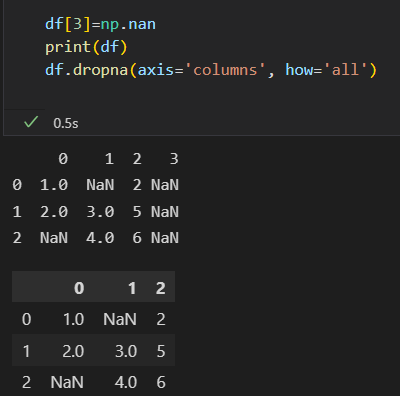
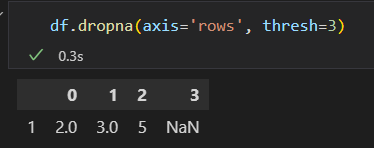
根据缺失值的数量 使用thresh 参数, 行或列中非缺失值的最小数量
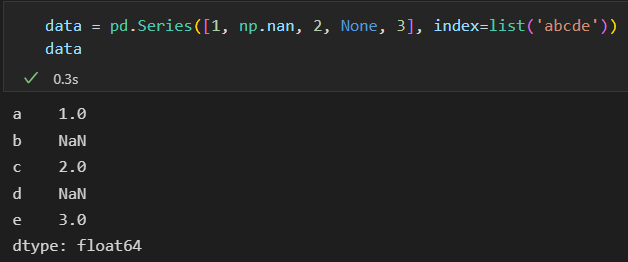
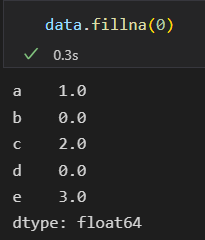
填充缺失值 fillna()
使用0来填充缺失值
从前往后填充
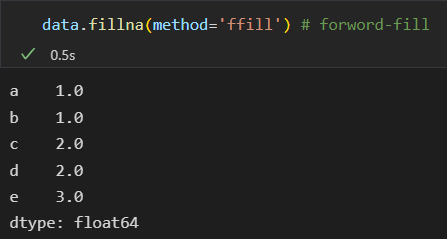
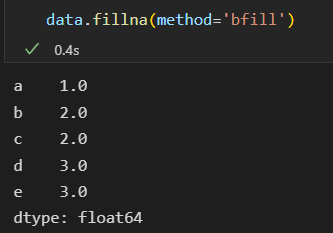
从后往前填充
DataFrame一行。只是需要设置坐标轴参数
axis=1 代表行。
axis=0 代表列。 我去。。。。
Python数据科学手册-Pandas:数值运算方法的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
随机推荐
- 经典的损失函数:交叉熵和MSE
经典的损失函数: ①交叉熵(分类问题):判断一个输出向量和期望向量有多接近.交叉熵刻画了两个概率分布之间的距离,他是分类问题中使用比较广泛的一种损失函数.概率分布刻画了不同事件发生的概率. 熵的定义: ...
- springboot2+jpa+oracle实例
pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="ht ...
- 软件测试—Day2
day2 Q:面试过程中,性能测试你测试什么?关注的点是什么? A:程序的响应时间,系统的吞吐量,以及并发用户数,和tps,qps,以及DB的IOPS,和服务器的系统资源(CPU和内存).通过一定的工 ...
- 开源数据质量解决方案——Apache Griffin入门宝典
提到格里芬-Griffin,大家想到更多的是篮球明星或者战队名,但在大数据领域Apache Griffin(以下简称Griffin)可是数据质量领域响当当的一哥.先说一句:Griffin是大数据质量监 ...
- 5-15 Virtual 虚拟机
虚拟机基本使用 Virtualbox安装流程 RockyLinux VirtualBox清华大学个版本下载路径 https://mirrors.tuna.tsinghua.edu.cn/virtual ...
- DDL_操作数据库_创建&查询和DDL_操作数据库_修改&删除&使用
DDL操作数据库.表 1.操作数据库:CRUD C(Create):创建 创建数据库: create database 数据库名称: 创建数据库判断不存在再创建 create database if ...
- ABC251 题解
典中典比赛 . 目录 A - Six Characters B - At Most 3 (Judge ver.) C - Poem Online Judge D - At Most 3 (Contes ...
- Vue mixin(混入) && 插件
1 # mixin(混入) 2 # 功能:可以把多个组件公用的配置提取成一个混入对象 3 # 使用方法: 4 # 第一步:{data(){return {...}}, methods:{...},.. ...
- LuoguP1922 女仆咖啡厅桌游吧 (树形动态规划)
#include <iostream> #include <cstdio> #include <cstring> #include <algorithm> ...
- Spring 01 概述
简介 Spring 是开源的轻量级 J2EE 框架 我们常说的 Spring 实际上是指 Spring Framework,它是 Spring 家族中的一个重要分支. 官方文档 https://doc ...