Elasticsearch 快照生命周期管理 (SLM) 实战指南
文章转载自:https://mp.weixin.qq.com/s/PSfgPJc4dKN2pOZd0Y02wA
1、Elasticsearch 保证高可用性的方式
Elasticsearch 保证集群高可用的方式包含但不限于如下三种:
方式一:副本分片。主分片失效后,副本分片会被提升为主分片。
方式二:跨集群复制主从同步。简称:CCR,指的是索引数据从一个 Elasticsearch 集群复制到另一个 Elasticsearch 集群。对于主集群的索引数据的任何修改都会直接复制同步到从索引集群。
方式三:快照。快照在给定时刻对集群或者索引按了暂停键且拍摄了当时的全部“照片”。这样,当在之后的某个时间点,倘若集群或索引出现故障,可以基于之前的快照进行快速恢复。
2、Elasticsearch 7.6 之前版本备份方式及存在问题
7.6 之前的版本快照都是手动创建、手动控制的。不支持:定时快照、定时删除历史快照等功能。
实际业务中,如何定时创建快照、定时删除时间比较久的历史快照呢?
关于快照的定时管理功能在 Elasticsearch 7.6+ 版本已经实现。
借助什么实现的呢?快照生命周期管理 (SLM) !
快照生命周期管理 (SLM) 是定期备份集群的最简单方法。SLM 策略会按照预设计划自动拍摄快照。该策略还可以根据用户自定义的保留规则(retention)删除快照。
3、Elasticsearch 快照生命周期管理(SLM)实现
如下实战演示是基于 Elasticsearch 8.1.3 版本进行的,没有涉及权限,只保留了最最核心的步骤。
步骤1:配置快照存储路径及注册快照存储库
在 elasticsearch 中添加如下配置:
path.repo: ["/www/elasticsearch_0801/backup_0801"]
注册快照存储库,同时设置存储路径。
PUT _snapshot/mytx_backup
{
"type": "fs",
"settings": {
"location": "/www/elasticsearch_0801/backup_0801"
}
}
步骤2:配置定时快照任务
这部分内容属于新版本才有的特性,我们逐行解释一下。
PUT _slm/policy/test-snapshots
{
"schedule": "0 0/15 * * * ?",
"name": "<test-snap-{now/d}>",
"repository": "mytx_backup",
"config": {
"indices": "*",
"include_global_state": true
},
"retention": {
"expire_after": "30d",
"min_count": 5,
"max_count": 50
}
}
- "schedule": "0 0/15 * * * ?"
含义:定时任务,类似 linux 下面的 crontab 命令。
直接看下面这张图:
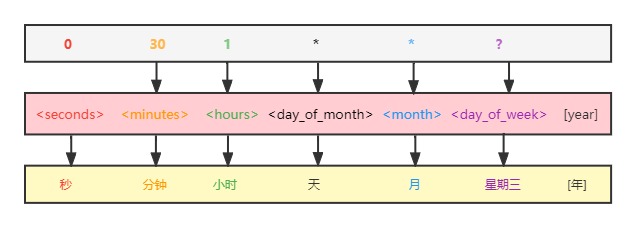
分别对应的是:秒、分钟、小时、天、月、星期、[年(可选)]。
"0 0/15 * * * ?"中:0/15 代表每15分钟创建一次快照。
15分钟是最小的时间间隔,不能再小了,再小会报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "invalid schedule [0 0/1 * * * ?]: schedule would be too frequent, executing more than every [15m]"
}
],
"type" : "illegal_argument_exception",
"reason" : "invalid schedule [0 0/1 * * * ?]: schedule would be too frequent, executing more than every [15m]"
},
"status" : 400
}
也可以从磁盘的角度考虑,周期时间越多,备份的次数越多,涉及重复备份数据越多,磁盘会扛不住。
星期部分的“?”问号指代的是——当我们不关心是星期几的时候,都可以使用“?”问号代表。
- "name": "<test-snap-{now/d}>"
含义:快照的名称。
- "repository": "mytx_backup"
含义:第一步创建的快照存储库。
- "config": { "indices": "*","include_global_state": true},
含义如果设置为true(默认为true),则创建的快照包括集群状态以及 feature 状态。
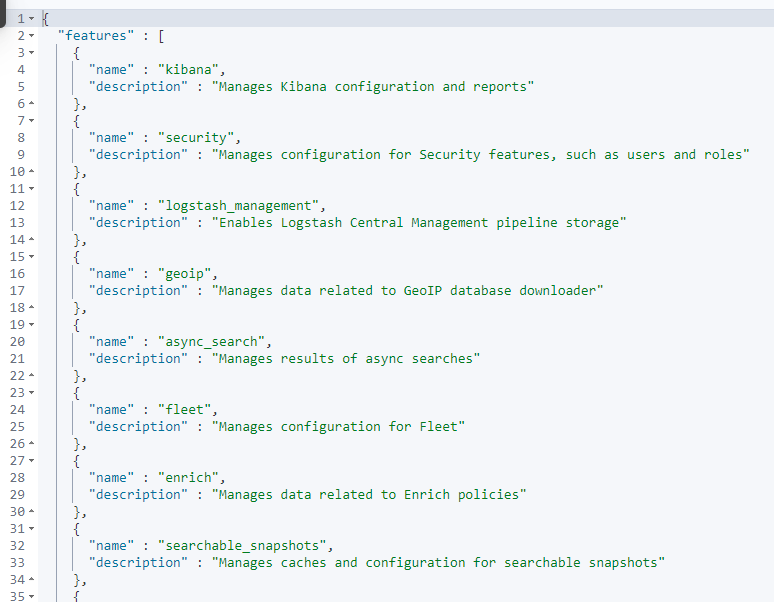
啥是 featrue 特征状态?
GET _features
- "retention": { "expire_after": "30d", "min_count": 5, "max_count": 50}
含义:配置可选的保留规则。如上的配置将快照保留 30 天,保留至少保留 5 个且最多不超过 50 个快照。
步骤3:执行步骤2创建的 policy
POST _slm/policy/test-snapshots/_execute
返回结果如下:
{
"snapshot_name" : "test-snap-2022.05.04-2vsflay-syotenwvgbh0kw"
}
执行完毕后,每15分钟会创建一个快照。最终在设定的快照存储路径下的结果为:
扩展:retention 快照的保留规则有定时执行或者手动立即执行两种方式。
retention 定时执行:
PUT _cluster/settings
{
"persistent" : {
"slm.retention_schedule" : "0 30 1 * * ?"
}
}
retention 立即执行:
POST _slm/_execute_retention
4、恢复快照
4.1
步骤1:查看特定快照存储库下的所有快照
GET _snapshot/mytx_backup/*?verbose=false
返回结果如下:
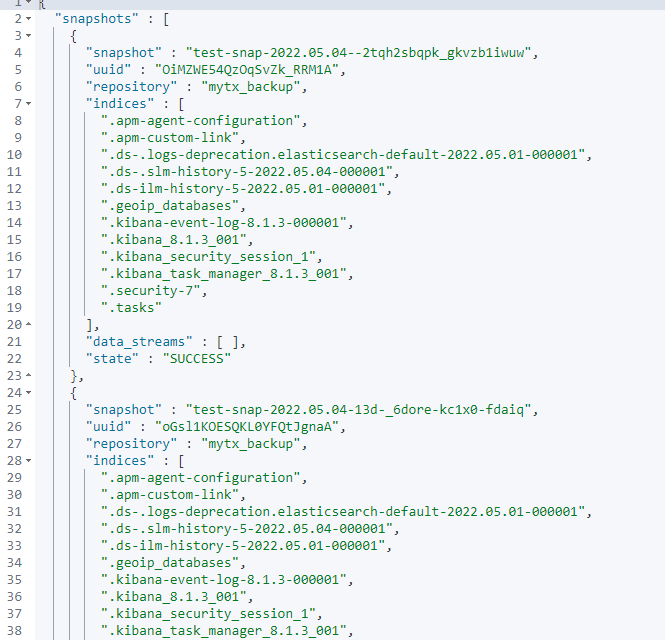
想恢复哪一个?需要通过如上命令行或通过 kibana 可视化界面操作选择。

4.2 恢复快照
选择要恢复的快照后,执行恢复即可。
注意:原恢复索引若存在是不可以的,需要提前删除后再恢复。
DELETE .kibana-event-log-8.1.3-000001
POST _snapshot/mytx_backup/test-snap-2022.05.04-13d-_6dore-kc1x0-fdaiq/_restore
{
"indices": ".kibana-event-log-8.1.3-000001"
}
恢复成功后返回:
{
"accepted" : true
}
5、Elasticsearch 快照生命周期管理(SLM)常见命令
5.1 监视任何当前正在运行的快照
GET _snapshot/mytx_backup/_current
5.2 返回任何当前正在运行的快照的每个细节
GET _snapshot/_status
5.3 查看全量 SLM policy 执行的历史
GET _slm/stats
召回结果如下:
{
"retention_runs" : 0,
"retention_failed" : 0,
"retention_timed_out" : 0,
"retention_deletion_time" : "0s",
"retention_deletion_time_millis" : 0,
"total_snapshots_taken" : 67,
"total_snapshots_failed" : 0,
"total_snapshots_deleted" : 0,
"total_snapshot_deletion_failures" : 0,
"policy_stats" : [
{
"policy" : "test-snapshots",
"snapshots_taken" : 67,
"snapshots_failed" : 0,
"snapshots_deleted" : 0,
"snapshot_deletion_failures" : 0
}
]
}
其中, "snapshots_taken" : 67 是执行快照的次数。
我是:2022-05-04 14:21执行的快照,现在是:2022-05-05 6:51,时间间隔为正好接近 67 的 15 倍分钟数。
5.4 查看特定 SLM policy 执行的历史
GET _slm/policy/test-snapshots
返回结果:
{
"test-snapshots" : {
"version" : 1,
"modified_date_millis" : 1651645270018,
"policy" : {
"name" : "<test-snap-{now/d}>",
"schedule" : "0 0/15 * * * ?",
"repository" : "mytx_backup",
"config" : {
"indices" : "*",
"include_global_state" : true
},
"retention" : {
"expire_after" : "30d",
"min_count" : 5,
"max_count" : 50
}
},
"last_success" : {
"snapshot_name" : "test-snap-2022.05.05-l4eldgoorfkkik8khlmuiq",
"start_time" : 1651733999879,
"time" : 1651734000637
},
"next_execution_millis" : 1651734900000,
"stats" : {
"policy" : "test-snapshots",
"snapshots_taken" : 100,
"snapshots_failed" : 0,
"snapshots_deleted" : 49,
"snapshot_deletion_failures" : 0
}
}
}
- last_success 代表上一次执行成功快照的名称;。
- start_time 快照执行时间:2022-05-05 14:29:59。
- next_execution_millis 下一次快照执行时间:2022-05-05 14:45:00。
- snapshots_taken - snapshots_deleted 之差和retention 里规定的 50 个是基本一致的。
5.5 删除快照
DELETE _snapshot/mytx_backup/test-snap-2022.05.05-uhbwjyj8qwwhdxqvcgejbq
执行成功,会返回:
{
"acknowledged" : true
}
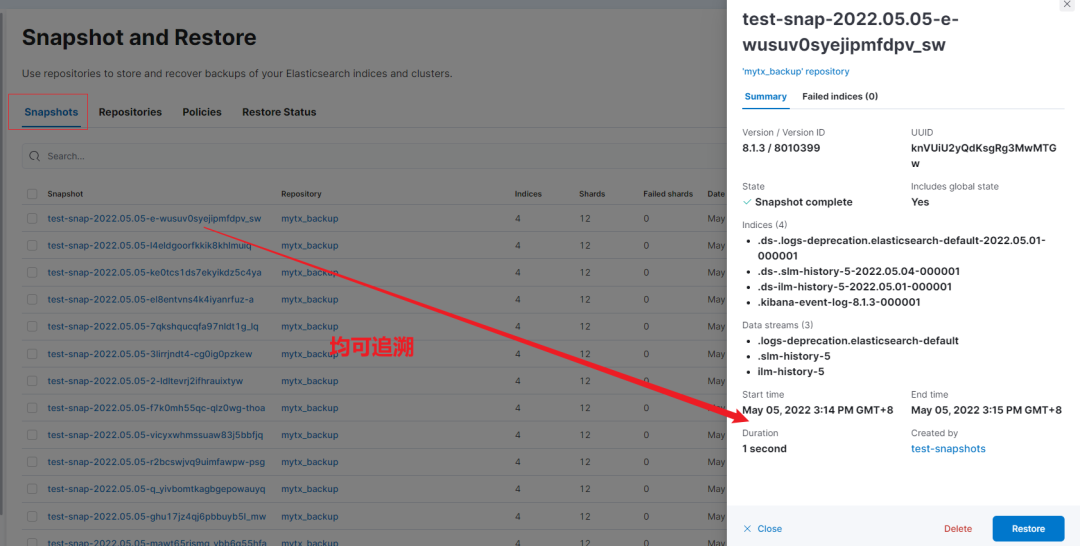
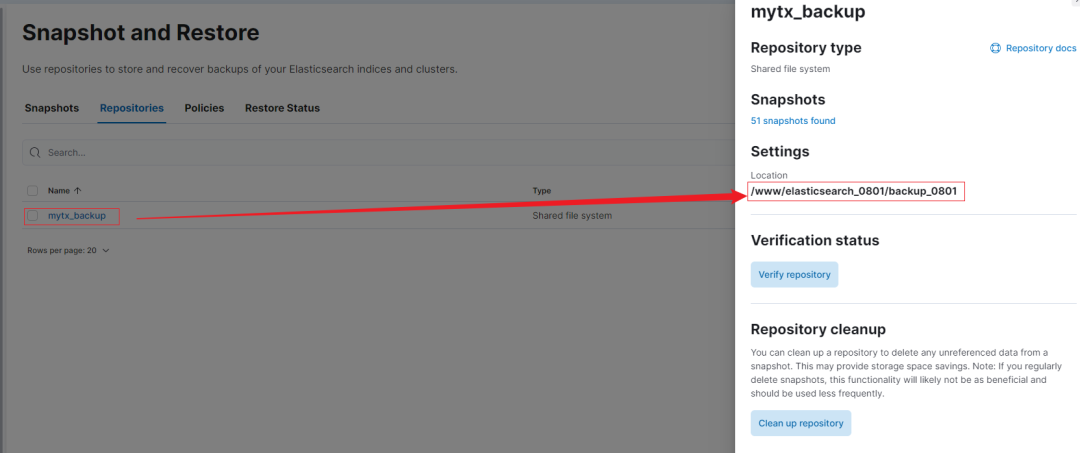
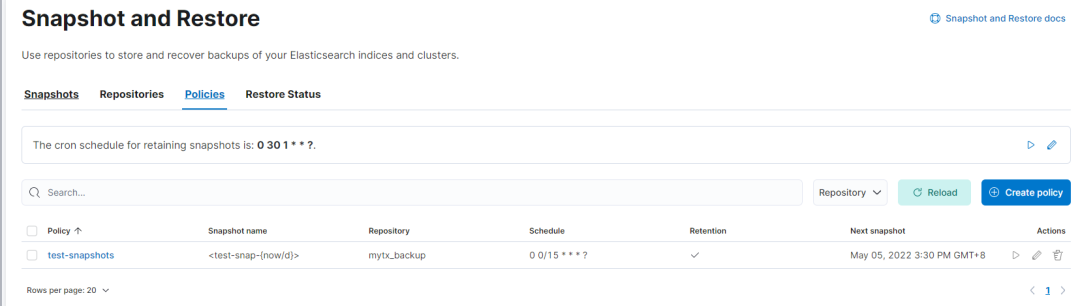
6、kibana 图形化界面操作快照生命周期SLM
有图有真相,不必过多解释!
7、小结
快照生命周期管理SLM 会让我们立即想到之前讲过的一个概念:索引生命周期管理 ILM。
ILM:解决的是基于冷热集群架构的时序索引的生、老、病、死全生命周期的管理。
SLM:解决的是快照的定时备份、定时清理功能。相较于之前的手动执行方式,自动执行的好处就是:全自动化,无需人工干预,能极大的提高开发和运维人员工作效率。
Elasticsearch 快照生命周期管理 (SLM) 实战指南的更多相关文章
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- ElasticSearch——索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management] 本文仅通 ...
- ElasticSearch生命周期管理-索引策略配置与操作
概述 本文是在本人学习研究ElasticSearch的生命周期管理策略时,发现官方未提供中文文档,有的也是零零散散,此文主要是翻译官方文档Policy phases and actions模块. 注: ...
- Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离) 一.“索引生命周期管理”概述 Elasticsearch索引生命周期管理指:Elasticsearch从设置.创建.打开.关闭.删 ...
- Logstash & 索引生命周期管理(ILM)
Grok语法 Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式.它拥有更多的模式,默认,Logstash拥有120个模式.如果这些模式不满足我们解析日志 ...
- Jasper:用户指南 / 设备 / 生命周期管理 / SIM 卡状态
ylbtech-Jasper:用户指南 / 设备 / 生命周期管理 / SIM 卡状态 1.返回顶部 1. SIM 卡状态 每个设备都有一个状态,决定了它能否在网络上建立数据连接,并且会影响设备是否计 ...
- Elasticsearch:Index生命周期管理入门
如果您要处理时间序列数据,则不想将所有内容连续转储到单个索引中. 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵. 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低 ...
随机推荐
- Tapdata Cloud 版本上新!新增ClickHouse,ADB MySQL等5个数据源支持
Tapdata Cloud cloud.tapdata.net Tapdata Cloud 是国内首家异构数据库实时同步云平台,目前支持Oracle.MySQL.PG.SQL Server.Mongo ...
- JDBCTools 第一个版本
JDBCToolV1: package com.dgd.test; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax ...
- 绝对路径-相对路径和File类的构造方法
绝对路径和相对路径 绝对路径:是一个完整的路径,以盘符开始(c: d:)c:\a.txt 相对路径:相对指的是相对于当前项目的根目录(可以省略项目的根目录) 注意: 1.路径不区分大小写 2.路径中的 ...
- scanf读入与printf输出
作为一个资深$cin,cout$玩家,在多次因为$cin$太慢被吊打后,开始反思有必要认真地学一下$scanf$和$printf$了$\cdot \cdot \cdot$ 格式 $scanf( &qu ...
- docker容器管理操作
Docker容器的四种状态: 运行 已暂停 重新启动 已退出 1.容器的创建 容器创建:就是将镜像加载到容器的过程. 创建容器时如果没有指定容器名称,系统会自动创建一个名称. 新创建的容器默认处于停止 ...
- mybatis-plus时间字段自动填充
时间代码自动填充的2种方式 数据库方式 将数据库字段create_time和update_time设置CURRENT_TIMESTAMP,create_time字段后面不需要勾选更新,update_t ...
- 使用JAVA CompletableFuture实现流水线化的并行处理,深度实践总结
大家好,又见面啦. 在项目开发中,后端服务对外提供API接口一般都会关注响应时长.但是某些情况下,由于业务规划逻辑的原因,我们的接口可能会是一个聚合信息处理类的处理逻辑,比如我们从多个不同的地方获取数 ...
- 常用的函数式接口Consumer接口练习字符串拼接输出
题目 下面的字符串数组当中有多条信息,请按照格式"姓名: XX 性别: XX"的格式将信息打印出来,要求将 打印姓名的动作为第一个Consumer接口的Lambda实例,将打印性别 ...
- 关于python文件打包成exe的调试问题
python文件使用pyinstaller打包的问题 常用pyinstaller相关命令 文件整体打包, 会自动打包相关依赖 pyinstaller -F file 分文件打包,只打包单个文件,其他文 ...
- Vue3 computed && watch(watchEffect)
1 # Vue3 计算属性与监视 2 # 1.computed函数:与Vue2.x中的computed配置功能一致 3 inport {ref,computed,watch} from 'vue'; ...