Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware
通过scrapy官网最新的架构图来理解:
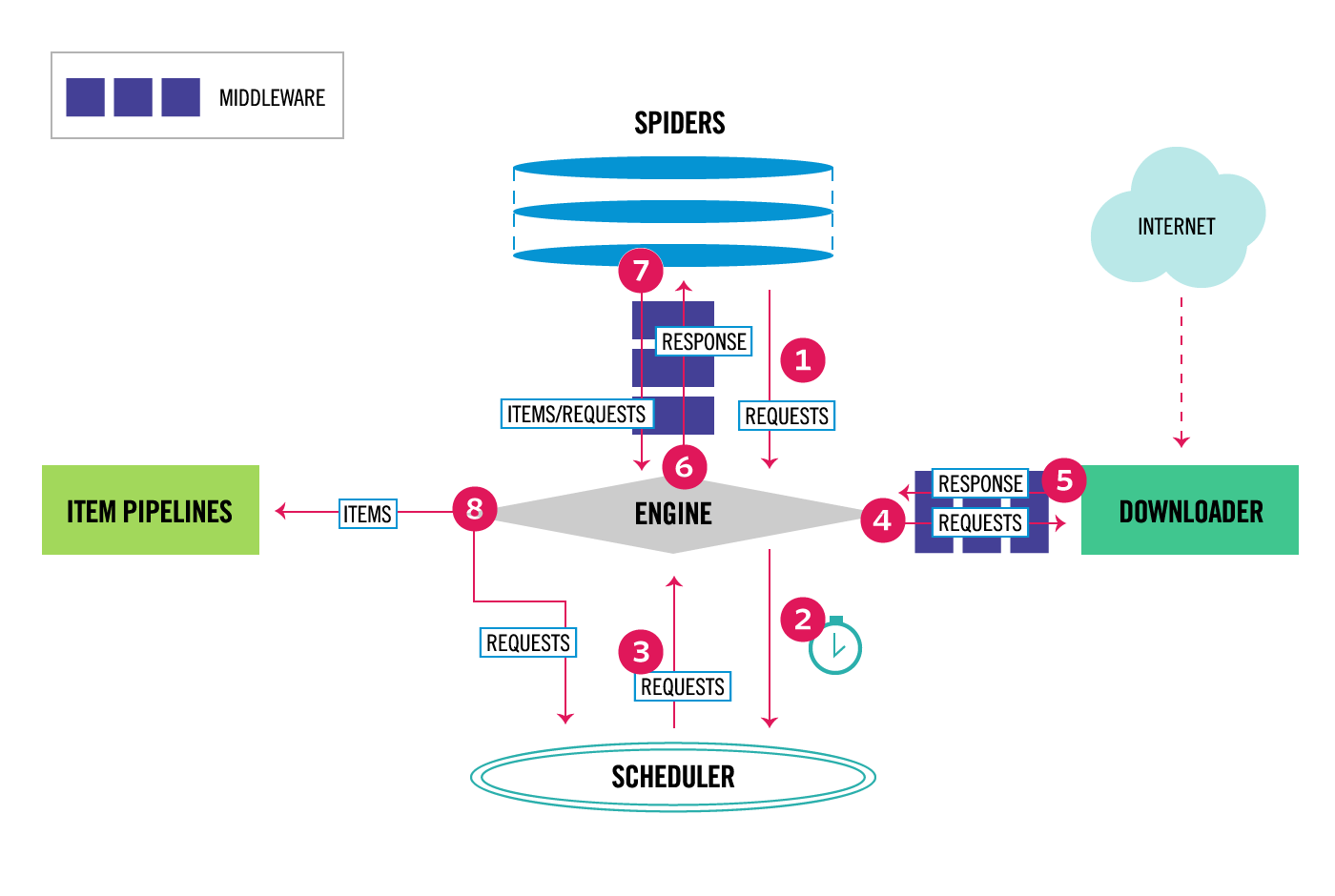
这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可以设置中间件,两者是双向的,并且是可以设置多层.
关于Downloader Middleware我在http://www.cnblogs.com/zhaof/p/7198407.html 这篇博客中已经写了详细的使用介绍。
如何实现随机更换User-Agent
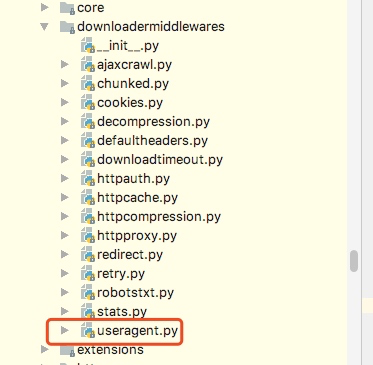
这里要做的是通过自己在Downlaoder Middleware中定义一个类来实现随机更换User-Agent,但是我们需要知道的是scrapy其实本身提供了一个user-agent这个我们在源码中可以看到如下图:
from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent""" def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent @classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent) def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
从源代码中可以知道,默认scrapy的user_agent=‘Scrapy’,并且这里在这个类里有一个类方法from_crawler会从settings里获取USER_AGENT这个配置,如果settings配置文件中没有配置,则会采用默认的Scrapy,process_request方法会在请求头中设置User-Agent.
关于随机切换User-Agent的库
github地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:
from fake_useragent import UserAgent ua = UserAgent() print(ua.ie)
print(ua.chrome)
print(ua.Firefox)
print(ua.random)
print(ua.random)
print(ua.random)
这里可以获取我们想要的常用的User-Agent,并且这里提供了一个random方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下:
DOWNLOADER_MIDDLEWARES = {
'jobboleSpider.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RANDOM_UA_TYPE= 'random'
这里我们要将系统的UserAgent中间件设置为None,这样就不会启用,否则默认系统的这个中间会被启用
定义RANDOM_UA_TYPE这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在middleares.py中添加如下代码:
class RandomUserAgentMiddleware(object):
'''
随机更换User-Agent
'''
def __init__(self,crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') @classmethod
def from_crawler(cls,crawler):
return cls(crawler) def process_request(self,request,spider): def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault('User-Agent',get_ua())
上述代码的一个简单分析描述:
1. 通过crawler.settings.get来获取配置文件中的配置,如果没有配置则默认是random,如果配置了ie或者chrome等就会获取到相应的配置
2. 在process_request方法中我们嵌套了一个get_ua方法,get_ua其实就是为了执行ua.ua_type,但是这里无法使用self.ua.self.us_type,所以利用了getattr方法来直接获取,最后通过request.heasers.setdefault来设置User-Agent
通过上面的配置我们就实现了每次请求随机更换User-Agent
Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换的更多相关文章
- scrapy的中间件Downloader Middleware实现User-Agent随机切换
scrapy的中间件Download Middleware实现User-Agent随机切换 总架构理解Middleware 通过scrapy官网最新的架构图来理解: 从图中我们可以看出,在spid ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python 爬虫(二十五) Cookie的处理--cookielib库的使用
Python中cookielib库(python3中为http.cookiejar)为存储和管理cookie提供客户端支持. 该模块主要功能是提供可存储cookie的对象.使用此模块捕获cookie并 ...
- Py修行路 python基础 (二十五)线程与进程
操作系统是用户和硬件沟通的桥梁 操作系统,位于底层硬件与应用软件之间的一层 工作方式:向下管理硬件,向上提供接口 操作系统进行切换操作: 把CPU的使用权切换给不同的进程. 1.出现IO操作 2.固定 ...
- Appium+python自动化(二十五)- 那些让人抓耳挠腮、揪头发和掉头发的事 - 获取控件ID(超详解)
简介 在前边的第二十二篇文章里,已经分享了通过获取控件的坐标点来获取点击事件的所需要的点击位置,那么还有没有其他方法来获取控件点击事件所需要的点击位置呢?答案是:Yes!因为在不同的大小屏幕的手机上获 ...
- Python学习(二十五)—— Python连接MySql数据库
转载自http://www.cnblogs.com/liwenzhou/p/8032238.html 一.Python3连接MySQL PyMySQL 是在 Python3.x 版本中用于连接 MyS ...
- Python学习札记(二十五) 函数式编程6 匿名函数
参考:匿名函数 NOTE 1.Python对匿名函数提供了有限的支持. eg. #!/usr/bin/env python3 def main(): lis = list(map(lambda x: ...
- Python学习日记(二十五) 接口类、抽象类、多态
接口类 继承有两种用途:继承基类的方法,并且做出自己的改变或扩展(代码重用)和声明某个子类兼容于某基类,定义一个接口类interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子 ...
随机推荐
- Arduino连接LCD1602显示屏
简介 LCD1602是一种工业字符型液晶,能够同时显示16x02即32个字符.LCD1602液晶显示的原理是利用液晶的物理特性,通过电压对其显示区域进行控制,即可以显示出图形.[百度百科] 引脚说明 ...
- 将反向传播讲解的深入透彻的神一样的文章(numpy实现人工神经网络)
为了完成机器学习课的项目,规定不许调tensorflow,pytorch这些包.可是要手工实现一个可训练的神经网络是非常困难的一件事,难点无他,就在于反向传播的实现.这不,我在网上发现了这篇文章.怎么 ...
- VSCode + WSL 2 + Ruby环境搭建详解
vscode配置ruby开发环境 vscode近年来发展迅速,几乎在3年之间就抢占了原来vim.sublime text的很多份额,犹记得在2015-2016年的时候,ruby推荐的开发环境基本上都是 ...
- 谈谈spring-boot-starter-data-redis序列化
在上一篇中springboot 2.X 集成redis中提到了在spring-boot-starter-data-redis中使用JdkSerializationRedisSerializerl来实现 ...
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- xutils工具上传日志文件--使用https并且带进度条显示
package logback.ecmapplication.cetcs.com.myapplication; import android.app.Activity; import android. ...
- java scoket Blocking 阻塞IO socket通信二
在上面一节中,服务端收到客户端的连接之后,都是new一个新的线程来处理客户端发送的请求,每次new 一个线程比较耗费系统资源,如果100万个客户端,我们就要创建100万个线程,相当的 耗费系统的资源, ...
- 同步/异步/阻塞/非阻塞/BIO/NIO/AIO各种情况介绍
常规的误区 假设有一个展示用户详情的需求,分两步,先调用一个HTTP接口拿到详情数据,然后使用适合的视图展示详情数据. 如果网速很慢,代码发起一个HTTP请求后,就卡住不动了,直到十几秒后才拿到HTT ...
- linux环境搭建单机kafka
准备工作: jdk-8u191-linux-x64.rpm | zookeeper-3.4.6.tar.gz | kafka_2.11-2.2.0.tgz 对应的地址 zookeeper: ...
- Java设计模式十九——责任链模式
责任链模式 老李的苦恼 每个人在出生的时候,都早已在暗中被标好了三六九等. 老李是一名建筑工地的木匠,和大多数生活在社会最底层的农民工一样,一辈子老实本分,胆小怕事.在他们的心中,谁当老爷都没有区别, ...