精进之路之HashMap
HashMap本质的核心就是“数组+链表”,数组对于访问速度很快,而链表的优势在于插入速度快,HashMap集二者于一身。
提到HashMap,我们不得不提各个版本对于HashMap的不同。本文中先从1.6版本谈起,分别从结构,hash,扩容等几方面展开来看。在具体讨论之前,我们先了解下HashMap的结构:
JDK1.6之结构: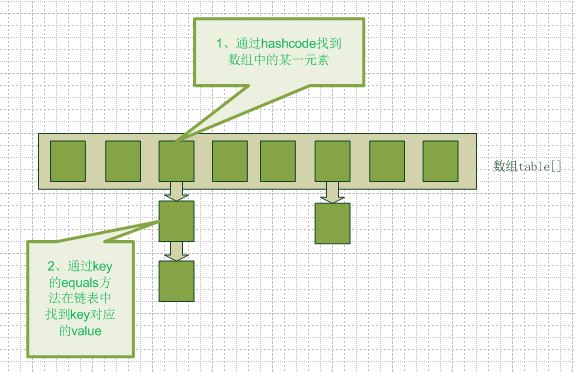
从图中我们可以看到一个hashmap就是一个数组结构,当新建一个hashmap的时候,就会初始化一个数组。我们来看看java代码:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* 表,根据需要调整大小。长度必须是2的幂
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; //当前的key
V value;//当前的value
Entry<K,V> next;//下一个元素
final int hash;// hash值
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
......
} 上面的Entry就是数组中的元素,它持有一个指向下一个元素的引用,这就构成了链表。
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。
如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的。 JDK1.6之hash算法:
我们可以看到在hashmap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。
前面说过hashmap的数据结构是数组和链表的结合,所以我们当然希望这个hashmap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,
那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
所以我们首先想到的就是把hashcode对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。
但是,“模”运算的消耗还是比较大的,能不能找一种更快速,消耗更小的方式那?java中时这样做的,
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
} 首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。
比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。
很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,
我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,
产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,
得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,
那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,
更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
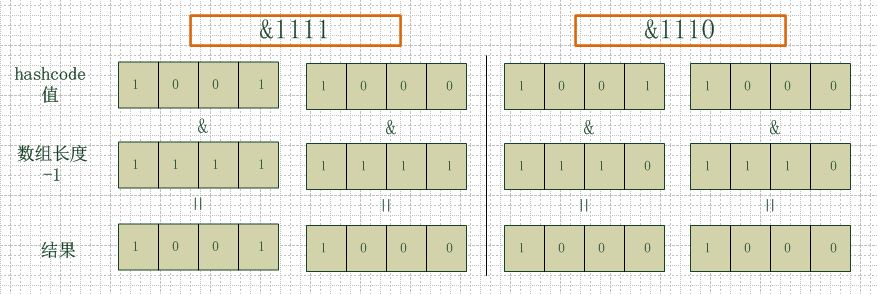
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
所以,在存储大容量数据的时候,最好预先指定hashmap的size为2的整数次幂次方。就算不指定的话,也会以大于且最接近指定值大小的2次幂来初始化的,代码如下(HashMap的构造方法中):
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1; JDK1.6之resize(默认扩充为原来的两倍):
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);//转换新表
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;//扩容前
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {//进行老entry遍历
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),
所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,
所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,
而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,
也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,
而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new
HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new
HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size >
1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
1.7
- 加入了jdk.map.althashing.threshold这个jdk的参数用来控制是否在扩容时使用String类型的新hash算法。
- 把1.6的构造方法中对表的初始化挪到了put方法中。
- 1.6中的tranfer方法对旧表的节点进行置null操作(存在多线程问题),1.7中去掉了。
1.8
hashmap有了重大更新,其内部实现采用了红黑树,entry链表长度超过阈值8,就会转为树结构,性能有了较大提升。
ConcurrentHashMap同样进行了巨大更新,放弃使用之前的分区锁,而是使用CAS原子操作来提供修改树节点的原子操作,其锁的粒度实际是节点,
故性能比以前有了不少的提升。和hashmap一样采用树结构,但是树的根节点是不一样的,也就是数组节点不一样。
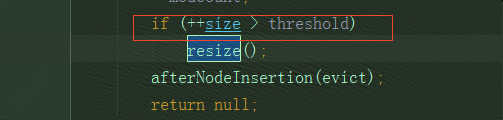
注意: resize 发生在大于等于临界值,而不单单是大于临界值,以下代码为例:当前size先进性了自增1操作,故size=threshold 时,便会发生resize()
注:本文摘自、整理如下文章,感谢原作者的倾心分享:http://www.iteye.com/topic/539465
推荐相关文章:http://www.importnew.com/28263.html
精进之路之HashMap的更多相关文章
- python精进之路1---基础数据类型
python精进之路1---基本数据类型 python的基本数据类型如上图,重点需要掌握字符串.列表和字典. 一.int.float类型 int主要是用于整数类型计算,float主要用于小数. int ...
- ❤️【Android精进之路-01】定计划,重行动来学Android吧❤️
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦. Android精进之路第一篇,确定安卓学习计划. 干货满满,建议收藏,需要用到时常看看.小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~. 前言 ...
- 《Go 精进之路》 读书笔记 (第一次更新)
<Go 精进之路> 读书笔记.简要记录自己打五角星的部分,方便复习巩固.目前看到p120 Go 语言遵从的设计哲学为组合 垂直组合:类型嵌入,快速让一个类型复用其他类型已经实现的能力,实现 ...
- 精进之路之lru
原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. 实现1 最常见的实现是 ...
- python精进之路 -- open函数
下面是python中builtins文件里对open函数的定义,我将英文按照我的理解翻译成中文,方便以后查看. def open(file, mode='r', buffering=None, enc ...
- 精进之路之AQS及相关组件
AQS ( AbstractQueuedSynchronizer)是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Sem ...
- 精进之路之CAS
CAS (Compare And Swap) 即比较交换, 是一种实现并发算法时常用到的技术,Java并发包中的很多类都使用了CAS技术,本文将深入的介绍CAS的原理. 其算法核心思想如下 执行函数: ...
- 精进之路之volatile
volatile 首先了解下Java 内存模型中的可见性.原子性和有序性. 可见性: 可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉.通常,我们无法确保执行读操作的线程能适时地看到其他 ...
- 精进之路之JMM
JMM (Java Memory Model) java内存模型 Java内存模型的抽象 Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一 ...
随机推荐
- navicat premium 破解版
下载链接:https://pan.baidu.com/s/1oNwtr2hdUN9F452xkji0aQ
- Asp.Net MVC 从客户端<a href="http://www....")中检测到有潜在危险的 Request.Form 值
Asp.Net MVC应用程序, Framework4.0: 则需要在webconfig文件的 <system.web> 配置节中加上 <httpRuntime requestVal ...
- 从身份证管理系统思考企业CMDB的建设
关注嘉为科技,获取运维新知 对大部分中大型的企业来说,CMDB建设对于整个IT服务和IT运维管理的重要性不言而喻,但是目前仍然有非常多的企业无法建设好CMDB. 我最近刚好接触了一个公安系统的朋友,他 ...
- 【转】解决Android 6.0 NoSuchContextException 和WEBVIEW_undefined 的问题
在 Android 4.4 操作系统上测试混合应用时,可以直接顺利的在native模式和webview模式之间切换,但是在Android6.0 操作系统上却报NoSuchContextExceptio ...
- rocketMQ No route info of this topic 错误
最近在使用rocketmq 发送消息,出现了No route info of this topic 异常,但奇怪的是我的其它的服务都可以成功发送,唯有crs服务不能成功发送,在网上搜索的解决方式基本上 ...
- 记录下自己VUE项目用Hbuider打包后启动白屏问题
刚用VUE做项目,之前测试时vue创建的自身项目打包都是启动OK没问题.今天打包自己的时,启动一直白屏.折磨了好久,百度了一堆.终于找到了方法. 首先是在config/index.js里面 build ...
- python3读写csv文件
python读取CSV文件 python中有一个读写csv文件的包,直接import csv即可.利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下. 1. 读文件 csv_ ...
- [转]利用Jenkins的Pipeline实现集群自动化部署SpringBoot项目
环境准备 Git: 安装部署使用略. Jenkins: 2.46.2版本安装部署略(修改jenkins执行用户为root,省得配置权限) JDK: 安装部署略. Maven: 安装部署略. 服务器免密 ...
- package.json和npm install、cnpm install 的問題
問題:最近使用cnpm安装项目依赖后,运行项目出现样式错乱问题. 描述:最近项目开发,需求参插了很多个版本,所以在前端项目的主干上拉好几套分支代码.拉的分支并不会把node_modules也拉过去,所 ...
- Treap标准模板
这是Treap的模板程序,支持Left/Right Rotate,Find the maxnum/minnum,Find the predecessor/successor of a node,Add ...