Python爬虫之selenium各种注意报错
刚刚写完第一个selenuim+BeautifulSoup实战爬虫 爬淘宝。发现代码写完后不加for 翻页的时候没什么问题 解析 操作 都没问题 也就是说第一页 的内容 完好
pagebtn=wait .until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
soup=BeautifulSoup(browser.page_source,'lxml')
info=soup.find(attrs={'id':'mainsrp-itemlist'})
imglist=info.find_all(attrs={'class':'J_ItemPic img'})
pricelist=info.find_all('strong')
locationlist=info.find_all(attrs={'class':'location'})
shopnamelist=info.find_all(attrs={'class':'shopname J_MouseEneterLeave J_ShopInfo'})
for imgsrcname,price,location, shopname in zip(imglist,pricelist,locationlist, shopnamelist):
data={}
data={
'name':imgsrcname.attrs['alt'],
'imgsrc':imgsrcname.attrs['src'],
'prick':price.get_text(),
'location':location.get_text(),
'shopname':shopname.contents[3].get_text()
}
collection.insert(data) pagebtn.click()
运行完好 数据库也有数据
可是需要频繁点击翻页的时候
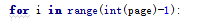

对于刚刚学习的人 一大串英文 显然看不懂 百度翻译 查
检查代码,
也加了等待啊 显示等待
为什么还是报错
说实话我不知道,,

在前面+了一个sleep(5)让他慢点操作 就可以了 完美翻页100
总结:
我觉得在使用selenuim的时候 尽可能的少操作网页(输入,点击),尽量模拟人的行为 机器运行太快 浏览器可能反应不过来。
Python爬虫之selenium各种注意报错的更多相关文章
- python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) selenium.common.excep
在python脚本中,使用selenium启动浏览器报错,原因是未安装浏览器驱动,报错内容如下: # -*- coding:utf-8 -*-from selenium import webdrive ...
- python爬虫,使用urllib2库报错
urllib2发生报错URLError: <urlopen error [Errno 10061]:首先检查网址是否正确其次如果报这种错误,是因为ie里设置了代理,取消即可, 步骤: 打开IE浏 ...
- python中用selenium调Firefox报错问题
python在用selenium调Firefox时报错: Traceback (most recent call last): File "G:\python_work\chapter11 ...
- python中引入包的时候报错AttributeError: module 'sys' has no attribute 'setdefaultencoding'解决方法?
python中引入包的时候报错:import unittestimport smtplibimport timeimport osimport sysimp.reload(sys)sys.setdef ...
- Selenium Grid 运行报错 Exception thrown in Navigator.Start first time ->Error forwarding the new session Empty pool of VM for setup Capabilities
Selenium Grid 运行报错 : Exception thrown in Navigator.Start first time ->Error forwarding the new se ...
- selenium执行js报错
selenium执行js报错 Traceback (most recent call last): dr.execute_script(js) File "C:\Python27\l ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
随机推荐
- RAC Wait Event: gcs log flush sync 等待事件 转
RAC Wait Event: gcs log flush sync https://www.hhutzler.de/blog/rac-wait-event_gcs_log_flush_sync/#o ...
- [原创]一种专门用于前后端分离的web服务器(JerryServer)
如果你还不了解现在的前后端分离,推荐阅读淘宝前端团队的前后端分离的思考与实践 1.问题 随着现在整个软件开发行业的发展,在开发模式上逐渐由以前的一个人完成服务端和前端web页面,演变为前端和后端逐渐分 ...
- 10 Django RESTful api 实现匿名访问
# views_send_code.py from rest_framework.permissions import AllowAny class MsgCodeViewSet(CreateMode ...
- ABP之Caching
简介 ABP提供缓存抽象,默认使用MemoryCache.但是可以替换成其他缓存程序,比如 Abp.RedisCache 是使用Redis实现缓存. ICacheManager 缓存的主要接口是ICa ...
- 01-Django介绍和安装
01-Django介绍和安装 1.Django介绍 1.1介绍 Django是一个开放源代码的Web应用框架,由Python写成.采用了MVC的框架模式,即模型M(Model),视图V(View)和控 ...
- 【递归】hex2dec
自己捉摸了好久,由于不熟悉. #include <stdio.h> int dec2hex(char *p); int base; int num; int main(void) { ch ...
- 树 相关知识总结以及Java实现
最近在温习树相关的知识,并且用java实现了一下树的遍历相关,先贴上代码供大家参考吧. package tree_problems; import java.util.ArrayDeque; impo ...
- python之路day11--装饰器形成的过程、作用、装饰器的固定模式
装饰器形成的过程# 装饰器的作用# 原则:开放封闭原则#装饰器的固定模式 import time # print(time.time()) #1551251400.416998 当前时间() #让程序 ...
- JDK TOMCAT MYSQL 配置
Java 开发环境 环境和版本介绍: 系统环境: CentOS-7-x86_64- 1810 软件本版 J d k 版本 jdk-8u181-linux-x64 Tomcat 版本 apac ...
- re模块正则表达式
regular expression / regex / RE 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配.Python 自1.5版本起增加了re 模块,它提供 ...