Python爬虫之selenium各种注意报错
刚刚写完第一个selenuim+BeautifulSoup实战爬虫 爬淘宝。发现代码写完后不加for 翻页的时候没什么问题 解析 操作 都没问题 也就是说第一页 的内容 完好
pagebtn=wait .until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
soup=BeautifulSoup(browser.page_source,'lxml')
info=soup.find(attrs={'id':'mainsrp-itemlist'})
imglist=info.find_all(attrs={'class':'J_ItemPic img'})
pricelist=info.find_all('strong')
locationlist=info.find_all(attrs={'class':'location'})
shopnamelist=info.find_all(attrs={'class':'shopname J_MouseEneterLeave J_ShopInfo'})
for imgsrcname,price,location, shopname in zip(imglist,pricelist,locationlist, shopnamelist):
data={}
data={
'name':imgsrcname.attrs['alt'],
'imgsrc':imgsrcname.attrs['src'],
'prick':price.get_text(),
'location':location.get_text(),
'shopname':shopname.contents[3].get_text()
}
collection.insert(data) pagebtn.click()
运行完好 数据库也有数据
可是需要频繁点击翻页的时候
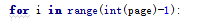

对于刚刚学习的人 一大串英文 显然看不懂 百度翻译 查
检查代码,
也加了等待啊 显示等待
为什么还是报错
说实话我不知道,,

在前面+了一个sleep(5)让他慢点操作 就可以了 完美翻页100
总结:
我觉得在使用selenuim的时候 尽可能的少操作网页(输入,点击),尽量模拟人的行为 机器运行太快 浏览器可能反应不过来。
Python爬虫之selenium各种注意报错的更多相关文章
- python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) selenium.common.excep
在python脚本中,使用selenium启动浏览器报错,原因是未安装浏览器驱动,报错内容如下: # -*- coding:utf-8 -*-from selenium import webdrive ...
- python爬虫,使用urllib2库报错
urllib2发生报错URLError: <urlopen error [Errno 10061]:首先检查网址是否正确其次如果报这种错误,是因为ie里设置了代理,取消即可, 步骤: 打开IE浏 ...
- python中用selenium调Firefox报错问题
python在用selenium调Firefox时报错: Traceback (most recent call last): File "G:\python_work\chapter11 ...
- python中引入包的时候报错AttributeError: module 'sys' has no attribute 'setdefaultencoding'解决方法?
python中引入包的时候报错:import unittestimport smtplibimport timeimport osimport sysimp.reload(sys)sys.setdef ...
- Selenium Grid 运行报错 Exception thrown in Navigator.Start first time ->Error forwarding the new session Empty pool of VM for setup Capabilities
Selenium Grid 运行报错 : Exception thrown in Navigator.Start first time ->Error forwarding the new se ...
- selenium执行js报错
selenium执行js报错 Traceback (most recent call last): dr.execute_script(js) File "C:\Python27\l ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
随机推荐
- 014_zk路径过滤分析
一.线上zk访问延迟特别高需要统计一段时间内的zk写入路径top10,实现如下: #!/usr/bin/env python # -*- coding:utf-8 -*- import re,trac ...
- postman使用详解
前言: Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件. 接口请求流程 一.get请求 GET请求:点击Params,输入参数及value,可输入多个,即时显示在URL ...
- 02-Django框架介绍
02-Django框架介绍 1.MVC框架介绍 MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式 具有耦合性低.重用性高.生 ...
- SpringMVC 接受请求参数、作用域传值
目录 原生servlet接收参数 Spring MVC最基础的参数获取 接收基本数据类型参数 方法参数列表和请求参数不一致的处理方式 接收对象引用数据类型 接收复选框这种多个同名的参数 接收obj.f ...
- spring整合redis使用RedisTemplate的坑Could not get a resource from the pool
一.背景 项目中使用spring框架整合redis,使用框架封装的RedisTemplate来实现数据的增删改查,项目上线后,我发现运行一段时间后,会出现异常Could not get a resou ...
- MongoDB 4.0.* 远程连接及用户名密码认证登陆配置——windows
- 能ping通虚拟机中的Ubuntu,使用XShell连不上
1.在宿主机上telnet 虚拟机ip 22如果显示端口无法接通,说明你的/etc/init.d/sshd 是stop或者是异常的. 2.如果没有sshd服务,使用" sudo apt-g ...
- 使用c++如何实现在gRPC中传输文件
使用c++实现gRPC远程调用框架中传输文件,proto文件如下: syntax = "proto3"; package transferfile; service Transfe ...
- DAY18、常用模块
一.random:随机数1.(0,1) 小数:random.random()2.[1,10] 整数:random.randint(1,10)3.[1,10) 整数:random.randrange(1 ...
- Kafka学习笔记-如何保证高可用
一.术语 1.1 Broker Kafka 集群包含一个或多个服务器,服务器节点称为broker. broker存储topic的数据. 如果某topic有N个partition,集群有N个broker ...