评价指标整理:Precision, Recall, F-score, TPR, FPR, TNR, FNR, AUC, Accuracy
针对二分类的结果,对模型进行评估,通常有以下几种方法:
Precision、Recall、F-score(F1-measure)
TPR、FPR、TNR、FNR、AUC
Accuracy
| 真实结果 | |||
| 1 | 0 | ||
| 预测结果 | 1 | TP(真阳性) | FP(假阳性) |
| 0 | FN(假阴性) | TN(真阴性) | |
TP(True Positive):预测结果为正类,实际上就是正类
FP(False Positive):预测结果为正类,实际上是反类
FN(False negative):预测结果为反类,实际上是正类
TN(True negative):预测结果为反类,实际上就是反类
1. Precision, Recall, F-score(F-measure)
Precision(准确率)可以理解为预测结果为正类中有多少真实结果是正类的:
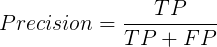
Recall(召回率)可以理解为真实结果为正类中有多少被预测成正类:
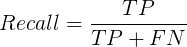
F-score(F值)又称作F1-measure,是综合考虑Precision和Recall的指标:
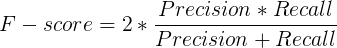
2. TPR, FPR, TNR, FNR, AUC
TPR(True Positive Rate)可以理解为所有正类中,有多少被预测成正类(正类预测正确),即召回率:
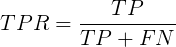
FPR(False Positive Rate)可以理解为所有反类中,有多少被预测成正类(正类预测错误):
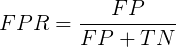
TNR(True Negative Rate)可以理解为所有反类中,有多少被预测成反类(反类预测正确):
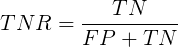
FNR(False Negative Rate)可以理解为所有正类中,有多少被预测成反类(反类预测错误):
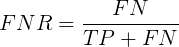
以FPR(False Positive Rate)为横坐标,TPR(True Positive Rate)为纵坐标,称作ROC曲线:

ROC曲线又称作“受试者工作特性曲线”,很明显,越靠近左上角的点,效果越好。
AUC(Area Under Curve)定义为ROC曲线下的面积,很明显,这个值越大越好。
3. Accuracy
Accuracy(精确率)可以理解为所有实验中,分类正确的个数:
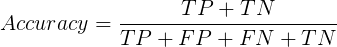
评价指标整理:Precision, Recall, F-score, TPR, FPR, TNR, FNR, AUC, Accuracy的更多相关文章
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1.如果需要很高的置信度的话,查准率会很高,相应的召回率很低:2.如果需要避免假阴性的话,召回率会很高,查准率会很低.下图右边显示的是召回率和查准率在一个学习算法中 ...
- TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area,
TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area, https://www.zhihu.com/question/30643044 T/ ...
- 查准与召回(Precision & Recall)
Precision & Recall 先看下面这张图来理解了,后面再具体分析.下面用P代表Precision,R代表Recall 通俗的讲,Precision 就是检索出来的条目中(比如网页) ...
- Precision/Recall、ROC/AUC、AP/MAP等概念区分
1. Precision和Recall Precision,准确率/查准率.Recall,召回率/查全率.这两个指标分别以两个角度衡量分类系统的准确率. 例如,有一个池塘,里面共有1000条鱼,含10 ...
- Handling skewed data---trading off precision& recall
preision与recall之间的权衡 依然是cancer prediction的例子,预测为cancer时,y=1;一般来说做为logistic regression我们是当hθ(x)>=0 ...
- 通过Precision/Recall判断分类结果偏差极大时算法的性能
当我们对某些问题进行分类时,真实结果的分布会有明显偏差. 例如对是否患癌症进行分类,testing set 中可能只有0.5%的人患了癌症. 此时如果直接数误分类数的话,那么一个每次都预测人没有癌症的 ...
- 机器学习:评价分类结果(Precision - Recall 的平衡、P - R 曲线)
一.Precision - Recall 的平衡 1)基础理论 调整阈值的大小,可以调节精准率和召回率的比重: 阈值:threshold,分类边界值,score > threshold 时分类为 ...
- 机器学习基础梳理—(accuracy,precision,recall浅谈)
一.TP TN FP FN TP:标签为正例,预测为正例(P),即预测正确(T) TN:标签为负例,预测为负例(N),即预测正确(T) FP:标签为负例,预测为正例(P),即预测错误(F) FN:标签 ...
随机推荐
- 课堂笔记及知识点----栈和队列(2018/10/24(am))
栈: Stack<int> xt=new Stack<int>() ; 先进后出,后进先出,水杯结构,顺序表类似 常用方法: .pop---->出栈,弹栈 ...
- 前台js根据当前时间生成订单号
*********前台显示框**************** <input type="text" id="WIDout_trade_no" name=& ...
- Ehcache 3.7文档—基础篇—Tiering Options
Ehcache支持分层缓存的概念,这节主要介绍不同的配置选项,同时也解释了规则和最佳实践. 一. 数据缓存到堆外 当在cache中除了有heap层之外,有一些需要注意的: 添加一个key-value到 ...
- PL-SVO公式推导及代码解析:位姿优化
通过跳过极线约束单独优化图像中每个特征的位置后,必须通过最小化3D特征与图像中相应的2D特征位置之间的重投影误差来进一步细化(3)中获得的相机姿态( 见图5).为此,我们考虑在世界坐标系中3D特征和相 ...
- 如何使用mybatis插入数据之前就具生成id值
SelectKey在Mybatis中是为了解决Insert数据时不支持主键自动生成的问题,该功能可以很随意的设置生成主键的方式. 不管SelectKey有多好,尽量不要遇到这种情况吧,毕竟很麻烦. k ...
- Confluence实现附件下载权限的控制
背景: 公司为了方便的管理过程文档,搭建了一个Confluence服务器,版本6.9.在使用过程中,需要按照用户对空间中上传的附件进行下载权限控制. 解决过程及处理方案: 一.Confluence中导 ...
- Python title()、upper()、lower()方法--string
描述 title()方法: 将字符串中的单词“标题化”,即首字母大写,其余字母转化为小写. upper()方法:将字符串中的小写字母转化为大写字母. lower()方法:将字符串中的大写字母转化为小写 ...
- layui 将后台传过来的值等价替换
<th lay-data="{field:'opentime',width:'12%' , sort: true, align:'center',templet:'#roleTpl'} ...
- springboot热部署配置
1.pom添加spring-boot-devtools依赖和配置编译插件 <dependency> <groupId>org.springframework.boot</ ...
- JavaScript 弹出窗体
//弹出层 //父页面代码.打开弹窗 function ProDBDisp(link) { var url = _spPageContextInfo.webAbsoluteUrl + link; va ...