爬虫系列(六) 用urllib和re爬取百度贴吧
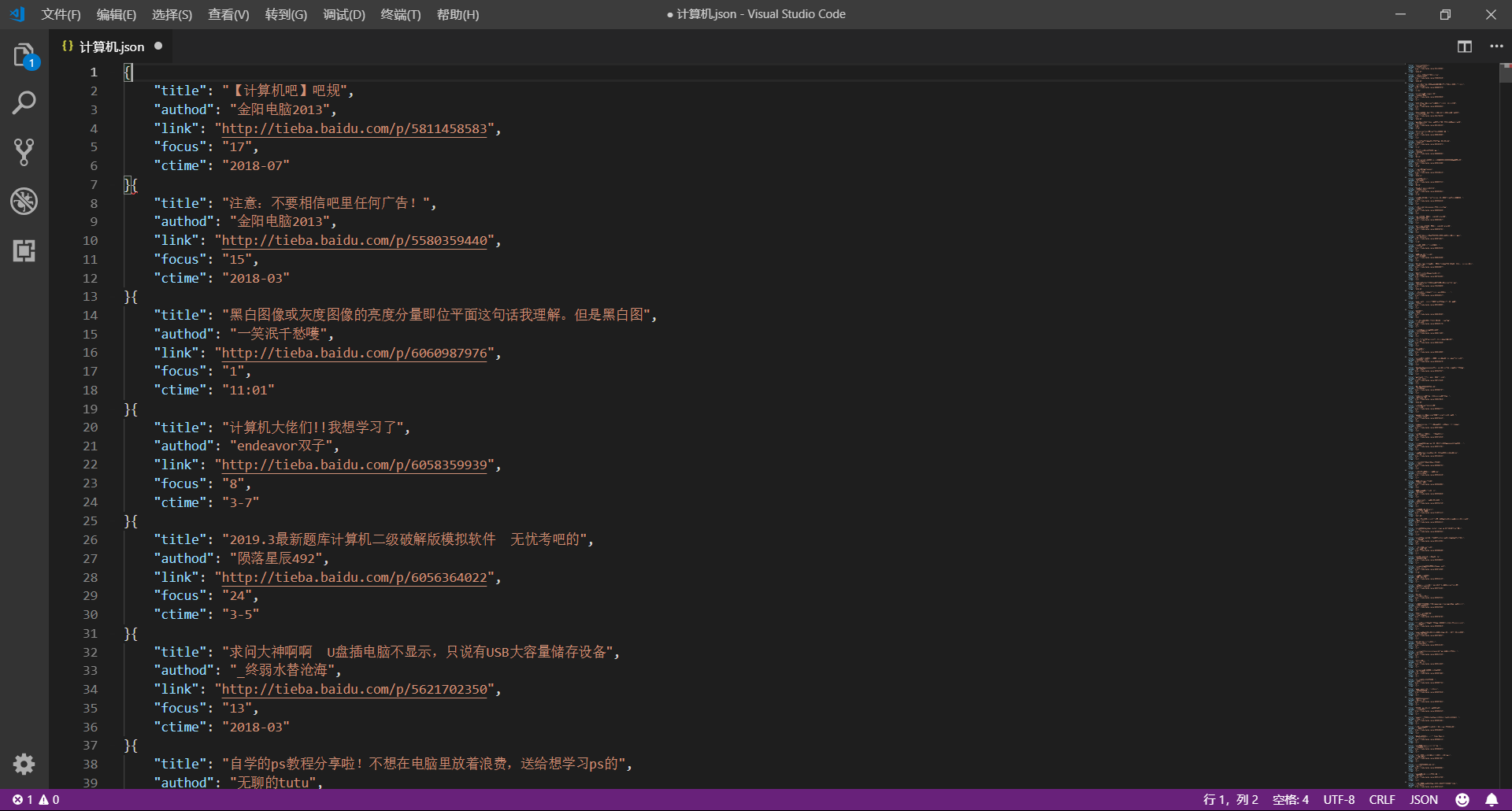
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图
1、网页分析
(1)准备工作
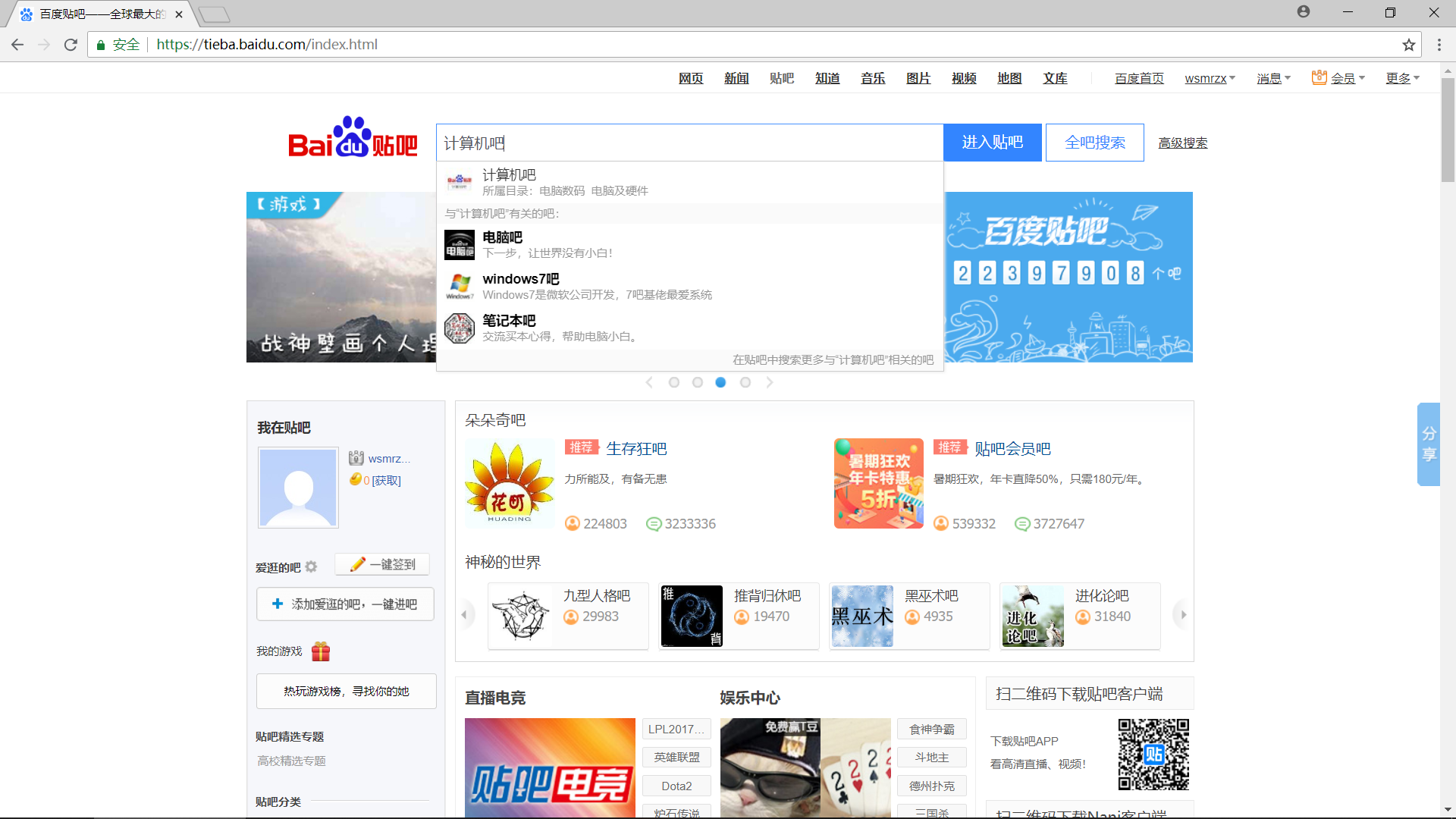
首先我们使用 Chrome 浏览器打开 百度贴吧,在输入栏中输入关键字进行搜索,这里示例为 “计算机吧”
(2)分析 URL 规律
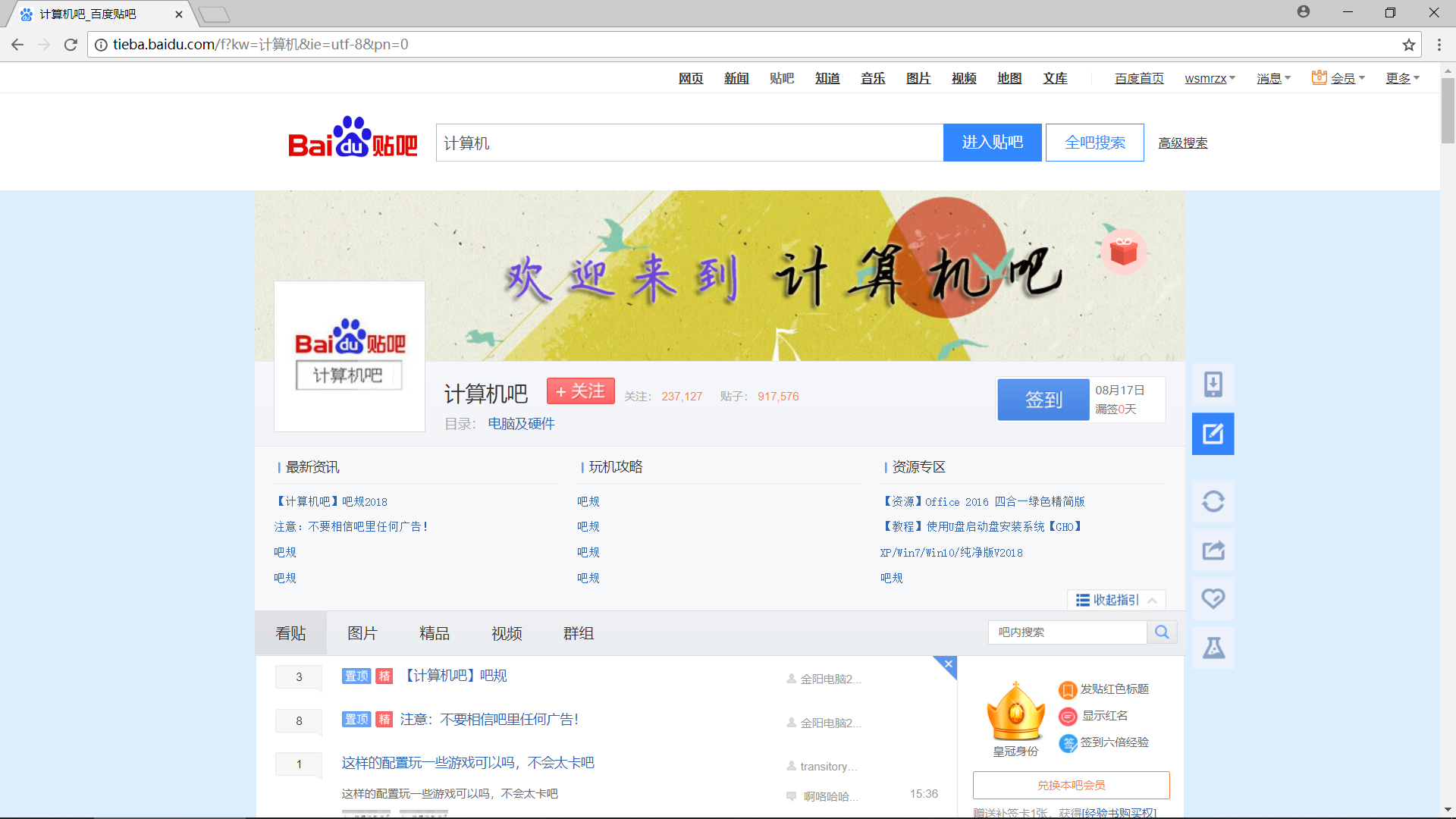
接下来我们开始分析网站的 URL 规律,以便于通过构造 URL 获取网站中所有网页的内容
第一页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=0
第二页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=50
第三页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=100
...
通过观察不难发现,它的 URL 十分有规律,主要的请求参数分析如下:
kw:搜索的关键字,使用 URL 编码,可以通过urllib.parse.quote()方法实现ie:字符编码的格式,其值为 utf-8pn:当前页面的页码,并且以 50 为步幅增长
所以完整的 URL 可以泛化如下:http://tieba.baidu.com/f?kw={keyword}&ie=utf-8&pn={page}
核心代码如下:
import urllib.request
import urllib.parse
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,headers=headers)
# 发送请求,得到响应
response = urllib.request.urlopen(req)
# 获得网页源代码
html = response.read().decode('utf-8')
# 返回网页源代码
return html
(3)分析内容规律
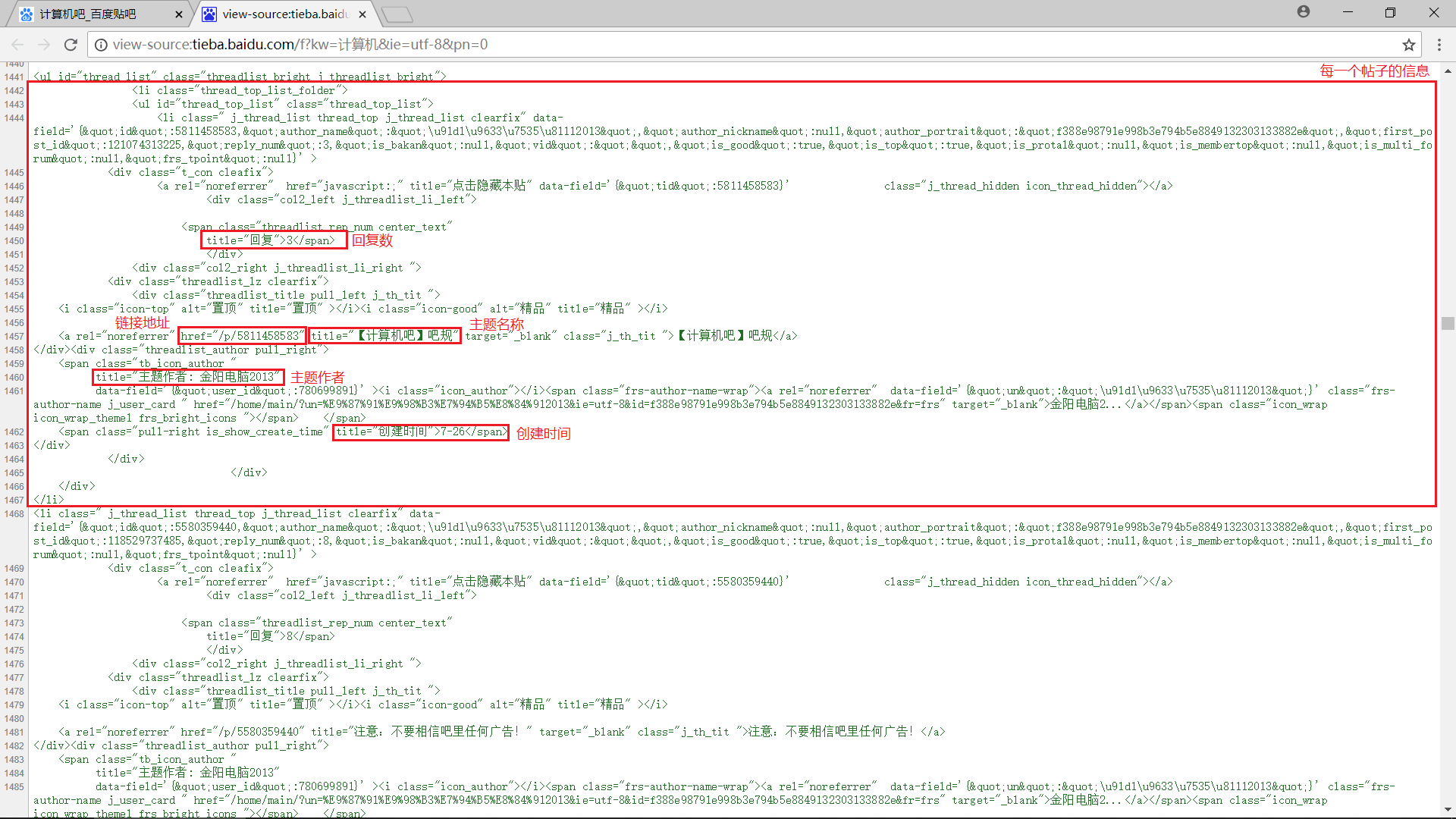
接下来我们直接使用快捷键 Ctrl+U 打开网页的源代码,认真分析每一页中我们需要抓取的数据
容易发现每一个帖子的内容都被包含在一个 <li> 标签中,我们可以使用正则表达式进行匹配,具体包括:
- 主题名称:
r'href="/p/\d+" title="(.+?)"'
- 主题作者:
r'title="主题作者: (.+?)"' - 链接地址:
r'href="/p/(\d+)"' - 回复数:
r'title="回复">(\d+)<' - 创建日期:
r'title="创建时间">(.+?)<'
核心代码如下:
import re
# 解析网页源代码,提取数据
def parse_page(html):
# 主题名称
titles = re.findall(r'href="/p/\d+" title="(.+?)"',html)
# 主题作者
authods = re.findall(r'title="主题作者: (.+?)"',html)
# 链接地址
nums = re.findall(r'href="/p/(\d+)"',html)
links = ['http://tieba.baidu.com/p/'+str(num) for num in nums]
# 回复数量
focus = re.findall(r'title="回复">(\d+)',html)
# 创建时间
ctimes = re.findall(r'title="创建时间">(.+?)<',html)
# 获得结果
data = zip(titles,authods,links,focus,ctimes)
# 返回结果
return data
(4)保存数据
下面将数据保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm,fileName):
fd = None
if fm == 'txt':
fd = open(fileName+'.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open(fileName+'.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open(fileName+'.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('title:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('link:' + str(item[2]) + '\n')
fd.write('focus:' + str(item[3]) + '\n')
fd.write('ctime:' + str(item[4]) + '\n')
if fm == 'json':
temp = ('title','authod','link','focus','ctime')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、编码实现
完整代码如下,也很简单,还不到 100 行
import urllib.request
import urllib.parse
import re
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
return html
# 解析网页源代码,提取数据
def parse_page(html):
titles = re.findall(r'href="/p/\d+" title="(.+?)"',html)
authods = re.findall(r'title="主题作者: (.+?)"',html)
nums = re.findall(r'href="/p/(\d+)"',html)
links = ['http://tieba.baidu.com/p/'+str(num) for num in nums]
focus = re.findall(r'title="回复">(\d+)',html)
ctimes = re.findall(r'title="创建时间">(.+?)<',html)
data = zip(titles,authods,links,focus,ctimes)
return data
# 打开文件
def openfile(fm,fileName):
if fm == 'txt':
return open(fileName+'.txt','w',encoding='utf-8')
elif fm == 'json':
return open(fileName+'.json','w',encoding='utf-8')
elif fm == 'csv':
return open(fileName+'.csv','w',encoding='utf-8',newline='')
else:
return None
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('title:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('link:' + str(item[2]) + '\n')
fd.write('focus:' + str(item[3]) + '\n')
fd.write('ctime:' + str(item[4]) + '\n')
if fm == 'json':
temp = ('title','authod','link','focus','ctime')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
kw = input('请输入主题贴吧名字:')
base_url = 'http://tieba.baidu.com/f?kw=' + urllib.parse.quote(kw) + '&ie=utf-8&pn={page}'
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm,kw)
page = 0
total_page = int(re.findall(r'共有主题数<span class="red_text">(\d+)</span>个',get_page(base_url.format(page=str(0))))[0])
print('开始爬取')
while page < total_page:
print('正在爬取第', int(page/50+1), '页.......')
html = get_page(base_url.format(page=str(page)))
data = parse_page(html)
save2file(fm,fd,data)
page += 50
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
【爬虫系列相关文章】
爬虫系列(六) 用urllib和re爬取百度贴吧的更多相关文章
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- Python3爬虫(1)_使用Urllib进行网络爬取
网络爬虫 又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- 爬虫第六篇:scrapy框架爬取某书网整站爬虫爬取
新建项目 # 新建项目$ scrapy startproject jianshu# 进入到文件夹 $ cd jainshu# 新建spider文件 $ scrapy genspider -t craw ...
- 爬虫系列(四) 用urllib实现英语翻译
这篇文章我们将以 百度翻译 为例,分析网络请求的过程,然后使用 urllib 编写一个英语翻译的小模块 1.准备工作 首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器 ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
随机推荐
- hibernate 普通字段延迟载入无效的解决的方法
关联对象的延迟载入就不说了.大家都知道. 关于普通字段的延迟载入,尤其是lob字段,若没有延迟载入,对性能影响极大.然而简单的使用 @Basic(fetch = FetchType.LAZY) 注解并 ...
- HTML_项目符号使用图片
本文出自:http://blog.csdn.net/svitter 创建一个HTML页面. 其内容为一个无序列表. 列表中至少包括了5本畅销书,每本书之前的项目符号必须採用概述封面的缩略图. 这些信息 ...
- 多工程联编的Pods如何设置
多工程联编的Pods如何设置 (2014-07-17 13:57:10) 转载▼ 标签: 联编 多工程 分类: iOS开发 如今,CocoaPods使用越来越多,几乎每个项目都会使用到.有时候我们的项 ...
- 一个jeecg整合activiti的学习样例,源代码下载
社区成员:刘京华採用技术:jeecg+ activiti源代码下载地址:http://pan.baidu.com/s/1dDxOHrV 截图演示: 2.jpg (71.81 KB, 下载次数: 0) ...
- Java:Socket通信
Socket通常也称作"套接字".用于描写叙述IP地址和port,是一个通信链的句柄.应用程序通常通过"套接字"向网络发出请求或者应答网络请求. ServerS ...
- C#遍历DataSet与DataSet元素实现代码
C#中的Dataset就像一个数据库,有多个表(Table),一般只有一个表,然后每个表中有行(DataRow)和列(DataColumn),DataRow[DataColumn]可以得到某行某列数据 ...
- mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置
mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置 转载自勤奋的小青蛙 mongodb占用内存非常高,这是因为官方为了提升存储的效率,设计就这么设计的. 但是大部分的个人 ...
- python统计ES存储空间占用的代码
import os from os.path import join, getsize def get_dir_size(dir, suffix_filter=None): size = 0L if ...
- [NOIP 2014] 生活大爆炸版石头剪刀布
[题目链接] http://uoj.ac/problem/15 [算法] 按题意模拟即可[代码] #include<bits/stdc++.h> using namespace std; ...
- 洛谷 P3959 NOIP2017 宝藏 —— 状压搜索
题目:https://www.luogu.org/problemnew/show/P3959 搜索: 不是记忆化,而是剪枝: 邻接矩阵存边即可,因为显然没有那么多边. 代码如下: #include&l ...