[读书笔记] Python数据分析 (五) pandas入门
pandas: 基于Numpy构建的数据分析库
pandas数据结构:Series, DataFrame
Series: 带有数据标签的类一维数组对象(也可看成字典)
values, index
缺失数据检测:pd.isnull(), pd.notnull(), Series对象的实例方法
Series对象本身及其索引都有一个name属性,和pandas其他关键功能关系很密切
DataFrame: 表格型数据结构,列和行都有索引
获取DataFrame列:字典标记方式,或者属性方式(frame2['state']/frame2.state)
获取DataFrame行:ix()方法
通过索引方式返回的列只是相应的数据视图,而不是副本,Series的Copy方法可以显示地复制列
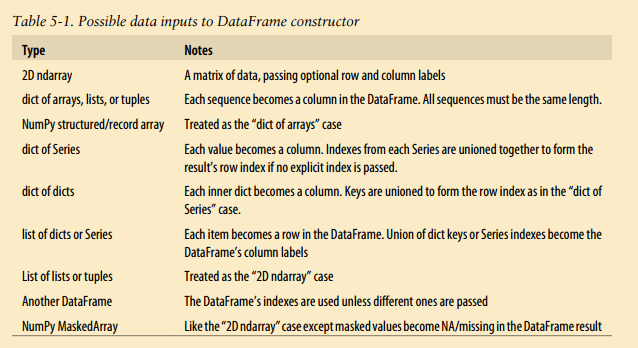
DataFrame的index和column也有name属性,可以自己设置
索引对象:pandas索引对象负责管理轴标签和其他元数据,构建Series或者DataFrame时,所用到的任何数组或者其他序列的标签会被转换成一个Index. Index对象是不可以修改(immutable)的.

Index属性
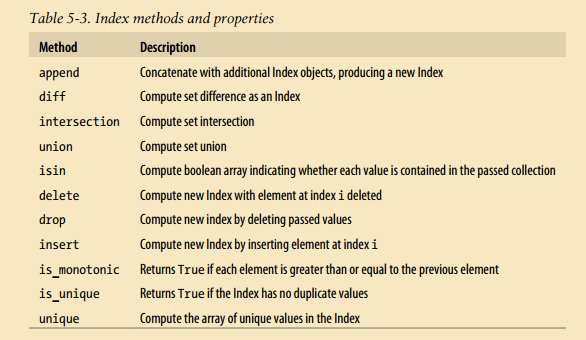
基本功能
重新索引:创建一个适合新索引的对象reindex()

指定丢弃对象:drop()
索引选取和过滤:ix()

算术运算和数据对齐
pandas可以对不同索引对象进行算术运算,对不重叠值自动填充NA
在算术方法中填充值:fill_value
DataFrame和Series之间的运算:broadcast()
默认情况下DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame列,然后沿着行向下传播;如果想匹配行且在列上广播,必须使用算术运算方法
函数应用和映射
numpy的ufuncs(元素级数组方法),也可以用于操作pandas对象
DataFrame的apply()方法,可以将函数应用到行或者列形成的一维数组
排序和排名
排序:
sort_index() 对行或者列的索引排序(按照字典顺序)
sort_index(by = ) 按照一个或者多个列中值进行排序
Series按值进行排序, order方法
排名:
rank()
带有重复值的轴索引
索引的is_unique()属性可以告诉你它的值是否是唯一的
汇总和计算描述性统计
sum()
mean()
describe()

描述和汇总统计函数
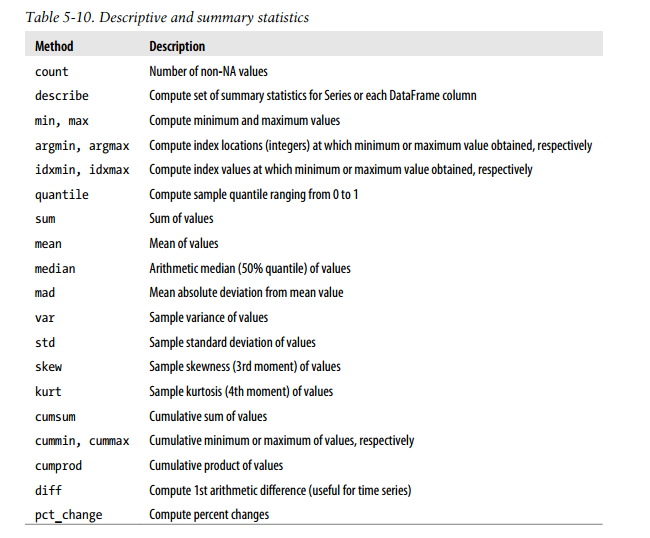
相关系数和协方差
对参数对进行计算得到,Series和DataFrame方法
唯一值,值计数,以及成员资格
唯一值:unique()方法
值计数:value_counts()方法计算一个Series中各个值出现的频率
成员资格:isin, 用于判断矢量化集合的成员资格,可以选取Series或DataFrame列中数据的子集

处理缺失数据

过滤缺失数据:dropna
对于DataFrame对象,dropna默认丢弃任何含有缺失值的行; dropna(how = 'all') 丢弃全为NA那些行.
如果是针对列,传入axis = 1便可
填充缺失数据:fillna
传入常数值:所有na被替换为常数值
传入字典:不同的列填充不同的值
默认返回新的对象,但是也可以就地修改 inplace = TRUE

层次化索引:数据重塑和基于分组的操作(透视表)
stack和unstack
对DataFrame来说,每条轴都可以有分层索引.
根据级别进行汇总:DataFrame和Series的描述和汇总统计都用一个level选项.
使用列作为行索引,将行索引变为DataFrame的列:set_index() 相反reset_index()
[读书笔记] Python数据分析 (五) pandas入门的更多相关文章
- Python数据分析之pandas入门
一.pandas库简介 pandas是一个专门用于数据分析的开源Python库,目前很多使用Python分析数据的专业人员都将pandas作为基础工具来使用.pandas是以Numpy作为基础来设计开 ...
- [读书笔记] Python数据分析 (二) 引言
1. 数据分析的任务:数据读写,数据准备(清洗,修整,规范化,重塑,切片切块,变形),转换,建模计算,呈现(模型/数据) 2. 数据集: bit.ly的1.usa.gov数据:URL缩短服务bit ...
- [读书笔记] Python数据分析 (一) 准备工作
1. python中数据结构:矩阵,数组,数据框,通过关键列相互联系的多个表(SQL主键,外键),时间序列 2. python 解释型语言,程序员时间和CPU时间衡量,高频交易系统 3. 全局解释器锁 ...
- [读书笔记] Python数据分析 (三) IPython
1. 什么是IPython IPyhton 本身没有提供任何的计算或者数据分析功能,在交互式计算和软件开发者两个方面最大化地提高生产力,execute-explore instead of edit- ...
- [读书笔记] Python数据分析 (四) 数组和矢量计算
Numpy:高性能计算和数学分析的基础包 ndarray, 一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组 用于对数组数据进行快速运算的标准数学函数 用于读写磁盘数据的工具和用于操作内存 ...
- [读书笔记] Python 数据分析 (十一)经济和金融数据应用
resample: 重采样函数,可以按照时间来提高或者降低采样频率,fill_method可以使用不同的填充方式. pandas.data_range 的freq参数枚举: Alias Descrip ...
- [读书笔记] Python 数据分析 (八)画图和数据可视化
ipython3 --pyplot pyplot: matplotlib 画图的交互使用环境
- [读书笔记] Python 数据分析 (十二)高级NumPy
da array: 一个快速而灵活的同构多维大数据集容器,可以利用这种数组对整块的数据进行一些数学运算 数据指针,系统内存的一部分 数据类型 data type/dtype 指示数据大小的元组 str ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- [Libre 6282] 数列分块入门 6 (分块)
原题:传送门 code: //By Menteur_Hxy #include<cstdio> #include<iostream> #include<algorithm& ...
- OSI层次介绍
1.应用层:为应用软件提供接口,使应用程序能够使用网络服务. 2.表示层:①数据的解码和编码,②数据的加密和解密,③数据的压缩和解压缩. 3.会话层:建立.维护.管理应用程序之间的会话. 功能:对话控 ...
- MongoDB记录(坑在末尾)
Mongo数据库基本配置 基本配置 密码配置 pymongo认证 参考资料 基本配置 基本配置包括 1.端口号:默认27017,安全性较低 2.数据库文件位置 3.日志文件位置 4.日志写入模式 5. ...
- docker 下载镜像 ( 以 mysql为例 )
一.官方镜像仓库 https://hub.docker.com/explore/ 二.常用操作 三.使用命令查看 mysql [root@localhost fw]# docker search my ...
- SSH框架整合截图(二)
客户拜访管理 1 什么是客户拜访 (1)客户:与公司有业务往来的 (2)用户:可以使用系统的人 2 用户和客户关系 (1)用户和客户之间是拜访的关系 (2)用户 和 客户 是 多对多关系 ** 一个用 ...
- C++ constexpr类型说明符
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50864210 关键字 constexp ...
- BA-设计施工调试流程
工程范围 1.楼宇自控系统的工程设计首先要了解目标建筑物所处的地理环境.建筑物用途.楼宇自控系统的建设目标定位.建筑设备规模与控制工艺及监控范围等工程情况.这些情况一般在工程招标技术文件中介绍,设计者 ...
- 使用magento eav数据模型为用户提供图片上传功能的实践
一,在megento表中,增加一个存储上传图片路径的属性, 给magento的customer实体类型增加一个audit_file_path属性,因为要customer使用的是EAV模型,得操作几个关 ...
- 双向链表的实现与操作(C语言实现)
双向链表也叫双链表,是链表的一种,它的每一个数据结点中都有两个指针,分别指向直接后继和直接前驱.所以,从双向链表中的随意一个结点開始,都能够非常方便地訪问它的前驱结点和后继结点. 单链表的局限 1.单 ...
- UI组件之AdapterView及其子类(三)Spinner控件具体解释
Spinner提供了从一个数据集合中高速选择一项值的办法. 默认情况下Spinner显示的是当前选择的值.点击Spinner会弹出一个包括全部可选值的dropdown菜单或者一个dialog对话框,从 ...