myeclipse下搭建hadoop2.7.3开发环境
需要下载的文件:链接:http://pan.baidu.com/s/1i5yRyuh 密码:ms91
一 下载并编译 hadoop-eclipse-plugin-2.7.3.jar
二 将hadoop-eclipse-plugin-2.7.3.jar放到myeclipse的安装目录下的plugins目录下,并重启myeclipse
在windows->preferences下可看见hadoop Map/Reduce界面,路径选择你WINDOWS下的hadoop解压后的路径。

三 选择Windows->show view->others下的MapReduce Locations

四 新建一个配置 配置如下
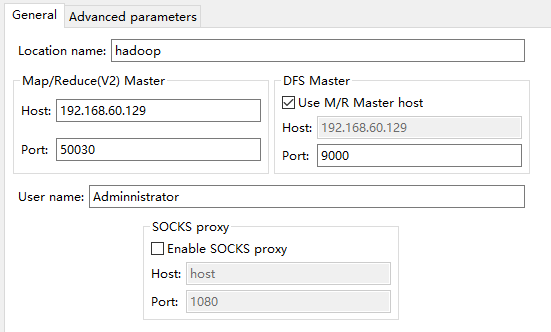
host为你的远程hadoop待连接的主机IP地址
Port:50030 对应mapred-site.xml下的jobtracher地址,如下

Port:9000对应core-site.xml下的fs.default.name的端口

user name 填你windows的用户名;
修改Advanced parameters下的参数

值对应 core-site.xml下的hadoop.tmp.dir参数

修改hdfs-site.xml下的dfs.permissions参数,允许连接

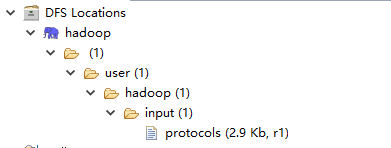
四 保存配置参数并重启myeclipse,可以看见如下的文件结构说明配置连接成功。
五 下载hadoop.ll和winutils.exe 到windows的hadoop/bin目录下

并将hadoop.dll添加到windows->system32目录下
五 环境测试
新建项目:File-->New-->Other-->Map/Reduce Project ,项目名可以随便取
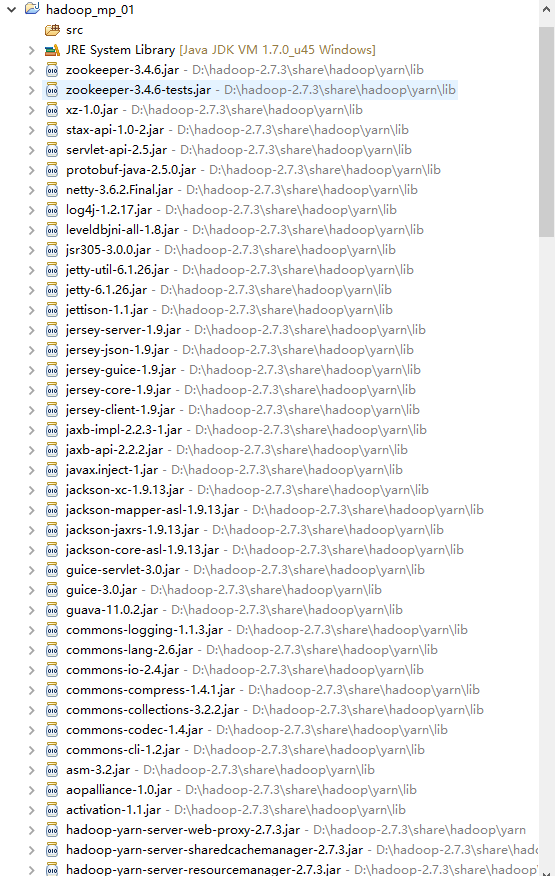
它会自动添加依赖包,如下:
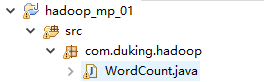
新建如下文件:
编写实现代码,与官方例子为例
package com.duking.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(otherArgs.length);
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
右击wordcount,选择run as - run configurations

右击wordcount-run as -run on hadoop
注意:HDFS的目录结构应如下:

protocols为输入待计算的数据。
查看运行结果


至此环境搭建成功!!!!!!!!!!
问题总结:环境搭建好后运行mapreduce程序发现output目录下为空,但把程序打包为jar到hadoop环境下运行是有数据输出的。
最后查资料解决方法如下:首先把

这个文件加入工程目录,注意解压的hadoop目录下有两个这个文件,不要加错了。
最后工程目录如下

然后运行程序发现报错了,错误提示为:Could not locate executable null

查阅资料后发现是没有添加HADOOP_HOME环境变量,添加即可。
如果不想重启电脑可以在代码下加如下代码

注意路径改为自己的windows hadoop路径
myeclipse下搭建hadoop2.7.3开发环境的更多相关文章
- Eclipse下搭建Hadoop2.4.0开发环境
一.安装Eclipse 下载Eclipse,解压安装,例如安装到/usr/local,即/usr/local/eclipse 4.3.1版本下载地址:http://pan.baidu.com/s/1e ...
- 在Ubuntu下搭建ASP.NET 5开发环境
在Ubuntu下搭建ASP.NET 5开发环境 0x00 写在前面的废话 年底这段时间实在太忙了,各种事情都凑在这个时候,没时间去学习自己感兴趣的东西,所以博客也好就没写了.最近工作上有个小功能要做成 ...
- react-native —— 在Windows下搭建React Native Android开发环境
在Windows下搭建React Native Android开发环境 前段时间在开发者头条收藏了 @天地之灵_邓鋆 分享的<在Windows下搭建React Native Android开发环 ...
- windows下搭建Apache+Mysql+PHP开发环境
原文:windows下搭建Apache+Mysql+PHP开发环境 要求 必备知识 熟悉基本编程环境搭建. 运行环境 windows 7(64位); Apache2.2;MySQL Server 5. ...
- Linux下搭建gtk+2.0开发环境
安装gtk2.0 sudo apt-get install libgtk2.0-dev 查看 2.x 版本 pkg-config --modversion gtk+-2.0 #有可能需要sudo ap ...
- Ruby on Rails入门——macOS 下搭建Ruby Rails Web开发环境
这里只介绍具体的过程及遇到的问题和解决方案,有关概念性的知识请参考另一篇:Ruby Rails入门--windows下搭建Ruby Rails Web开发环境 macOS (我的版本是:10.12.3 ...
- Mac下搭建Cocos2d-x-3.2的开发环境
配置:OS X 10.9.4 + Xcode 6.0 + Cocos2d-x-3.2 摘要:本文目标为在Xcode成功运行HelloWorld程序. 一.下载必要项 1.从官网下载Cocos2d-x- ...
- Ubuntu 14.04下搭建Node.js的开发环境
最近想找一个轻量级且支持快速开发的服务开发平台,选来选去选择了Node.js,当时有几种选择: Python + Django(用过Django,虽然开发快速,但是感觉性能并不太好). Ruby + ...
- 各种环境下搭建ruby on rails开发环境
win10上搭建raby on rails环境: 步骤如下 1.安装ruby (我选择的版本是ruby 2.2.3p173) 2.安装rails gem 在这之前建议先把gem的源换成淘宝的源,速度快 ...
随机推荐
- EditTextView
package com.egojit.android.sops.views.EditText; import android.content.Context; import android.graph ...
- CodeIgniter框架——nginx下的配置
odeigniter(CI)是一个轻量型的PHP优秀框架,但是它是在apache服务器下开发的,在nginx下需要特别的配置才可以使用. 对nginx的配置如下: server { listen 80 ...
- HDU3037 附Lucas简单整理
Saving Beans Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- .net framework 4.5 在Visual studio 2015中丢失
解决办法:从另一台C:\Program Files(x86)\Reference Assemblies\Microsoft\.NetFramework 成功的环境中copy .net4.5 文件夹到错 ...
- 《从零开始学Swift》学习笔记(Day5)——我所知道的标识符和关键字
Swift 2.0学习笔记(Day5)——我所知道的标识符和关键字 原创文章,欢迎转载.转载请注明:关东升的博客 好多计算机语言都有标识符和关键字,一直没有好好的总结,就是这样的用着,现在小小的整 ...
- jQuery之获取select选中的值
本来以为jQuery("#select1").val();是取得选中的值, 那么jQuery("#select1").text();就是取得的文本. 这是不正确 ...
- 我的Android进阶之旅------>百度地图学习:BDLocation.getLocType ( )值分析
BDLocation类,封装了定位SDK的定位结果,在BDLocationListener的onReceive方法中获取.通过该类用户可以获取error code,位置的坐标,精度半径等信息.具体方法 ...
- Oracle学习笔记—数据库,实例,表空间,用户、表之间的关系
之前一直使用的关系型数据库是Mysql,而新公司使用Oracle,所以最近从网上搜集了一些资料,整理到这里,如果有不对的地方,欢迎大家讨论. 基本概念: 数据库:Oracle 数据库是数据的物理存储. ...
- (转)js获取内网ip地址,操作系统,浏览器版本等信息
这次呢,说一下使用js获取用户电脑的ip信息,刚开始只是想获取用户ip,后来就顺带着获取了操作系统和浏览器信息. 先说下获取用户ip地址,包括像ipv4,ipv6,掩码等内容,但是大部分都要根据浏览器 ...
- rails 下载 send_file
def download send_file File.join(Rails.root, "public", @doc.link), :filename => @title+ ...