利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文:
你可能需要的工作环境:
我们这里以sogou作为爬取的对象。
首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它…
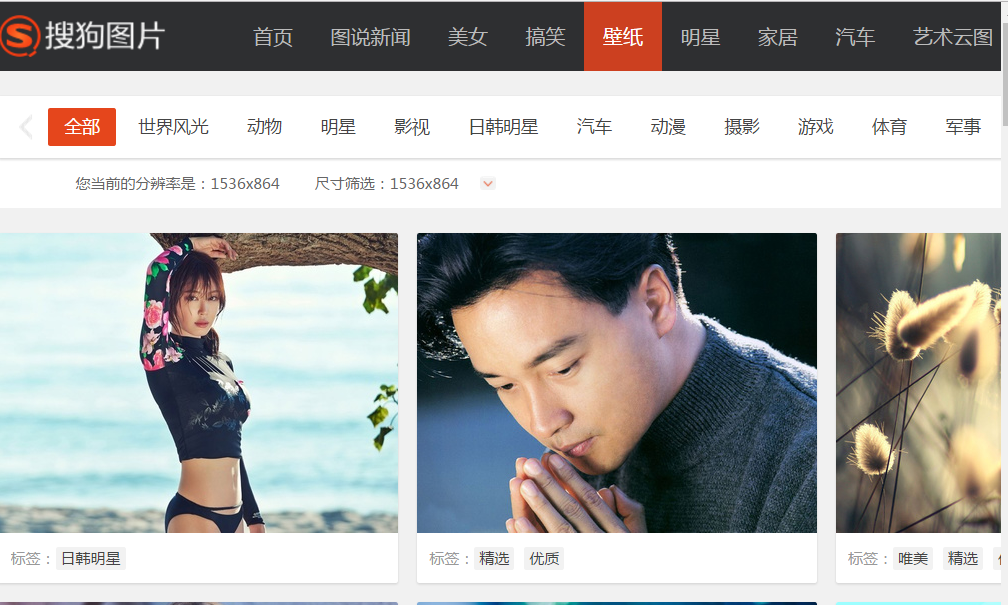
进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome。
右键图片>>检查

发现我们需要的图片src是在img标签下的,于是先试着用 Python 的 requests提取该组件,进而获取img的src然后使用 urllib.request.urlretrieve逐个下载图片,从而达到批量获取资料的目的,思路好了,下面应该告诉程序要爬取的url为http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD,此url来自进入分类后的地址栏。明白了url地址我们来开始愉快的代码时间吧:
在写这段爬虫程序的时候,最好要逐步调试,确保我们的每一步操作正确,这也是程序猿应该有的好习惯。笔者不知道自己算不算个程序猿哈。线面我们来剖析该url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))
output:

发现输出内容并不包含我们要的图片元素,而是只剖析到logo的img,这显然不是我们想要的。也就是说需要的图片资料不在url 即 http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD里面。因此考虑可能该元素是动态的,细心的同学可能会发现,当在网页内,向下滑动鼠标滚轮,图片是动态刷新出来的,也就是说,该网页并不是一次加载出全部资源,而是动态加载资源。这也避免了因为网页过于臃肿,而影响加载速度。下面痛苦的探索开始了,我们是要找到所有图片的真正的url 笔者也是刚刚接触,找这个不是太有经验。最后找的位置F12>>Network>>XHR>>(点击XHR下的文件)>>Preview。
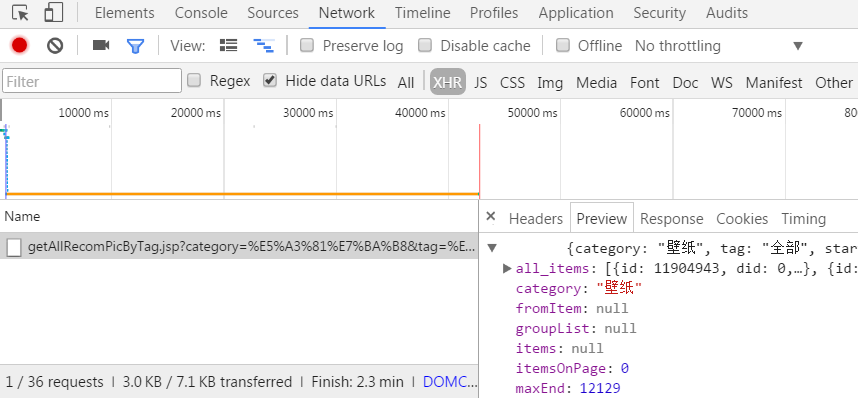
发现,有点接近我们需要的元素了,点开all_items 发现下面是0 1 2 3...一个一个的貌似是图片元素。试着打开一个url。发现真的是图片的地址。找到目标之后。点击XHR下的Headers
得到第二行
import requests
import json
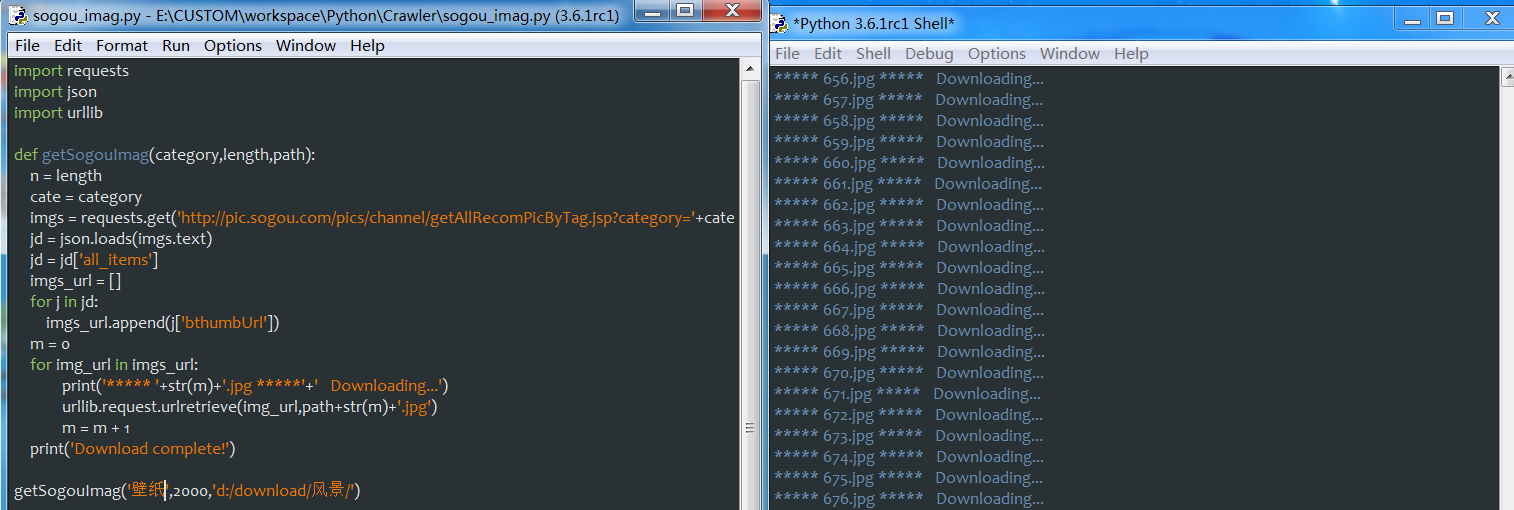
import urllib def getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = []
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!') getSogouImag('壁纸',2000,'d:/download/壁纸/')


利用Python爬取网页图片的更多相关文章
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
- 用python 爬取网页图片
import re import string import sys import os import urllib url="http://tieba.baidu.com/p/252129 ...
- python爬取网页图片
# html:网页地址 def getImg2(html): soup = BeautifulSoup(html, 'html.parser') href_regex = re.compile(r'^ ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
随机推荐
- Linux 桌面玩家指南:15. 深度学习可以这样玩
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用$标记数学公式的开始和结束.如果某条评论中出现了两个$,MathJax 会将两个$之 ...
- Pytorch系列教程-使用字符级RNN对姓名进行分类
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/char_rnn_classification_t ...
- mpvue小程序开发之 iconfont图标引入
背景: mpvue进行小程序项目开发时候,会有很多图标需求,但是小程序官方提供的icon图标库实在有限而且也不利于调样式,所有想到和之前前端项目一样引入iconfont. 图标加入购物车及项目 下载到 ...
- 每日分享!~ JavaScript(js数组如何在指定的位置插入一个元素)
这个想法是在一个面试题中看到的: 题目是这样的: // 一个数组,在指定的index 位置插入一个元素,返回一个新的数组,不改变原来的数组 <script> function inse ...
- perl学习笔记---标量
1.perl 输出时,使用 逗号,连接多个字符串 如:print “The answer is ”,6*7, “.\n” 2.当一个字符串由双引号括起来时,如果变量前没有反斜线,则变量会被其值内插 $ ...
- [小技巧]C#中如何为枚举类型添加描述方法
背景 在我们的日常开发中,我们会经常使用枚举类型.有时我们只需要显示枚举的值或者枚举值对应名称, 但是在某些场景下,我们可能需要将枚举值显示为不同的字符串. 例: 当前我们有如下枚举Level pub ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- 前端性能核对表Checklist-2018
前端性能核对表Checklist-2018 1. 计划与度量 Get Ready: Planning and Metrics ☐ Establish a performance culture. ☐ ...
- Office组件无法正常使用的解决方法
问题与现象 开发时调用Office组件,代码编译是通过的,但在运行时当ApplicationClass对象初始化后程序出现异常. 异常信息如下: 无法将类型为“Microsof ...