转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。

layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
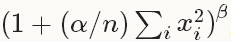 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
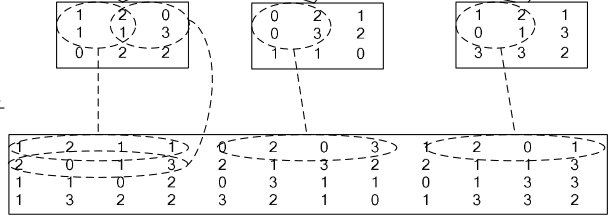
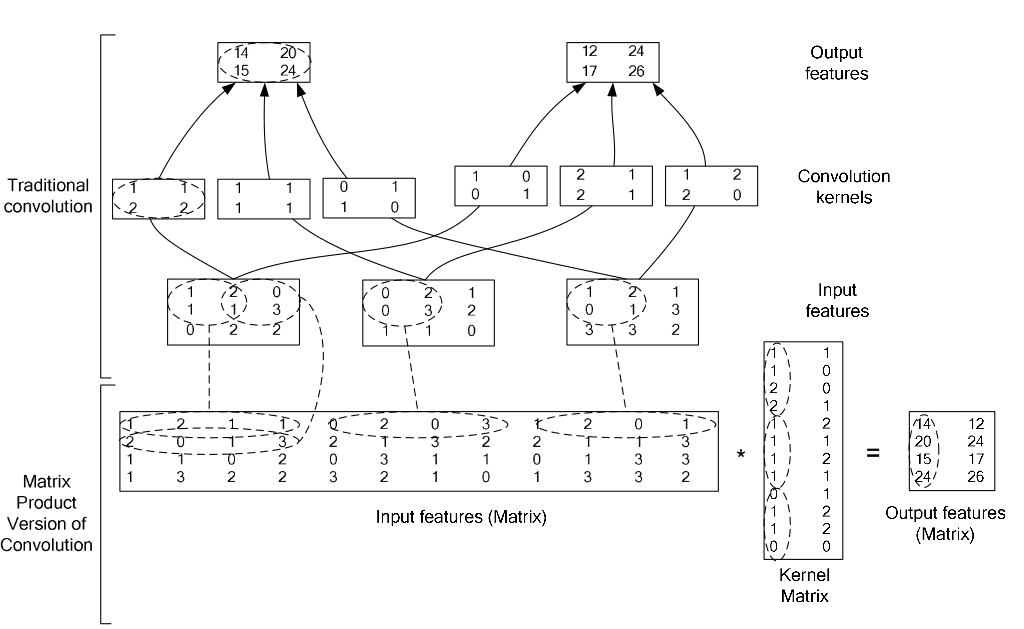
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
转 Caffe学习系列(3):视觉层(Vision Layers)及参数的更多相关文章
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- JAVA常用知识点总结---集合篇
一.Collection 与 Collections的区别:1. Collections:java.util.Collections 是一个包装类.它包含有各种有关集合操作的静态多态方法.此类不能实例 ...
- aop难点解析。
静态织入和动态织入的区别? 需求示例:假设有一个包,一个包当中有一个方法,我们想在这个方法的前后,加上环绕. 那么怎么加呢? 把知道的都说一遍. 1.建立JsonService 2.建立JSONASP ...
- HDU 4372 Count the Buildings [第一类斯特林数]
有n(<=2000)栋楼排成一排,高度恰好是1至n且两两不同.现在从左侧看能看到f栋,从右边看能看到b栋,问有多少种可能方案. T组数据, (T<=100000) 自己只想出了用DP搞 发 ...
- POJ 2187 Beauty Contest [凸包 旋转卡壳]
Beauty Contest Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 36113 Accepted: 11204 ...
- 如何使用 scikit-learn 为机器学习准备文本数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 文本数据需要特殊处理,然后才能开始将其用于预测建模. 我们需要解析文本,以删除被称为标记化的单词.然后,这些词还需要被编码为整型或浮点型,以用作 ...
- element ui 1.4 升级到 2.0.11
公司的框架 选取的是 花裤衩大神开源的 基于 element ui + Vue 的后台管理项目, 项目源码就不公开了,记录 分享下 步骤 1. 卸载 element ui 1.4的依赖包 2. 卸载完 ...
- SDN第二次作业
作业链接 阅读文章<软件定义网络(SDN)研究进展>,并根据所阅读的文章,书写一篇博客,回答以下问题(至少3个): 为什么需要SDN?SDN特点? 随着网络规模的不断扩大,封闭的网络设备内 ...
- 保存文件名至txt文件中,不含后缀
准备深度学习的训练数据时,可能会用到将图片文件名保存到txt文件中,所以用python实现了该功能.输入参数只设了两个,图片存放路径,和输出的txt文件名. 代码里写死了只识别.jpg格式,并不进行目 ...
- ThreadLocal 简述
ThreadLocal的理解 Java中的ThreadLocal类允许我们创建只能被同一个线程读写的变量.因此,如果一段代码含有一个ThreadLocal变量的引用,即使两个线程同时执行这段代码,它们 ...
- Apache设置二级域名和虚拟主机
apache httpd.conf 最后: ------------------------------NameVirtualHost *:80<VirtualHost *:80> ...