python scrapy框架爬虫遇到301
1.什么是状态码301
301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
比如,我们访问 http://www.baidu.com 会跳转到 https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
注意: 301请求是可以缓存的, 即通过看status code,可以发现后面写着from cache。
或者你把你的网页的名称从php修改为了html,这个过程中,也会发生永久重定向。
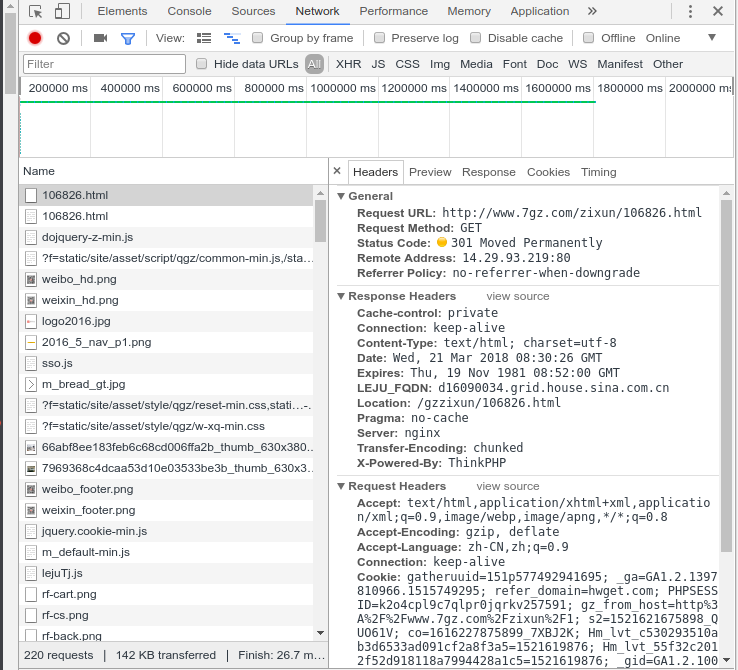
2.如何处理
首先我们可以使用scrapy框架中的 scrapy shell 进行测试
跳转前后的url如果是一致的,我们在终端命令行输入 :
scrapy shell http://www.7gz.com/gzzixun/106826.html
观察到log中信息包含:
[scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.7gz.com/gzzixun/106826.html> (referer: None)
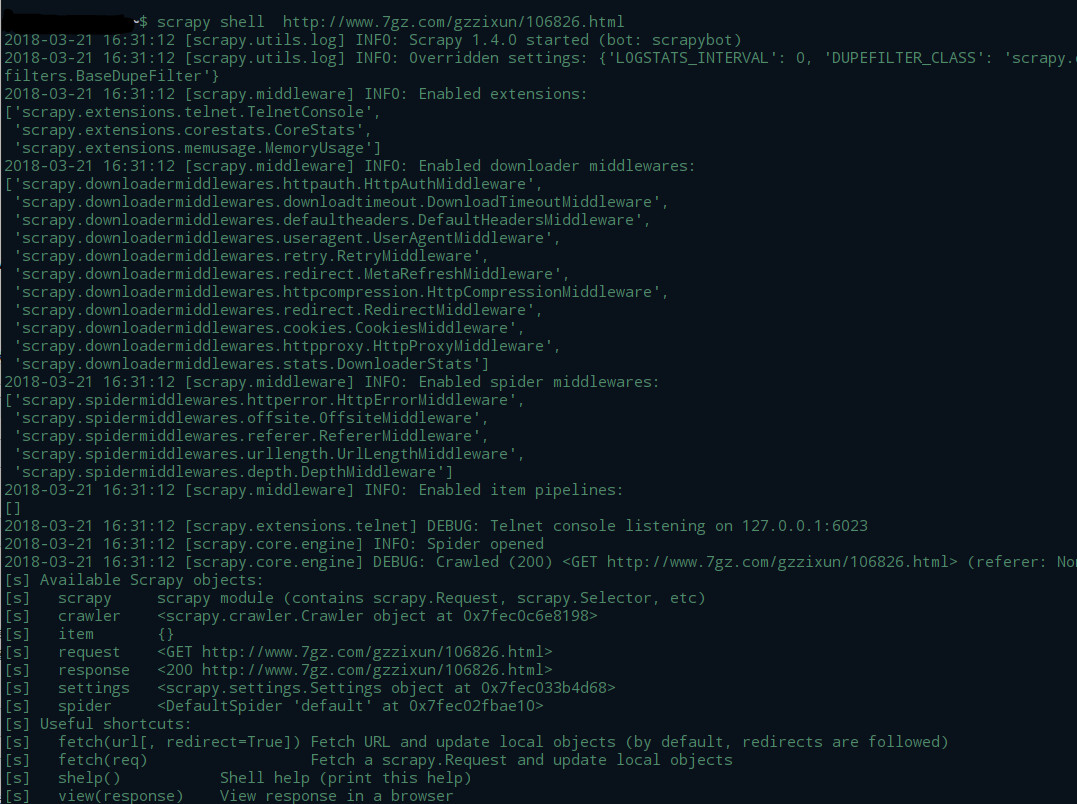
说明我们可以正常访问这个网址,只是跳转网址未改变,状态码是301。
这个时候我们需要在scrapy框架中的 settings.py 文件里添加
HTTPERROR_ALLOWED_CODES = [301]
这样再运行就不会产生301的log信息了,爬虫可以正常运行。
python scrapy框架爬虫遇到301的更多相关文章
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- Python scrapy框架
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
随机推荐
- Error Code: 1305. FUNCTION student.rand_string does not exist
1.错误描述 13:52:42 call new_procedure Error Code: 1305. FUNCTION student.rand_string does not exist 0.0 ...
- box-sizing -- 盒模型
项目开发中,在浏览同事的代码,发现他经常用一个属性--box-sizing,很好奇是什么,于是乎,上网查阅资料学了起来. 首先我们先复习一下盒模型的组成:一个div通常由 content(内容)+ma ...
- OpenGL shader渲染贴图
simple.vert #version core layout (location = ) in vec3 position; layout (location = ) in vec3 color; ...
- JavaScript设计模式(4)-桥接模式
桥接模式 在设计一个 Js API 时,可用来弱化它与使用它的类和对象之间的耦合 1. 事件监听器的回调函数 function getBeerById(id, callback) { asyncReq ...
- TCP/IP协议三次握手与四次握手流程解析(转)
一.TCP报文格式 下面是TCP报文格式图: 上图中有几个字段需要重点介绍下: (1)序号:Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标 ...
- CF908D Arbitrary Arrangement
题目大意: 给定三个数\(k\) , \(p_a\) , \(p_b\) 每次有\(\frac{p_a}{p_a+p_b}\)的概率往后面添加一个'a' 每次有\(\frac{p_b}{p_a+p_b ...
- hive java编写udf函数
(一)创建JAVA 代码--例子 package hiveOpt; import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop ...
- c#多线程同步之Semaphore
一提到Semaphore(信号量)的使用,还挺有意思的,它允许多个线程同时访问多个稀有资源,我立马想到银行的ATM机取钱的场景.看下面的代码: ); public static void StartT ...
- Python账号密码登陆判断(三次机会)
#!/usr/bin/env python #coding=UTF-8 #先设定初始用户名和登录密码 init_usrname=input("Please enter initial use ...
- PAT乙级-1042. 字符统计(20)
请编写程序,找出一段给定文字中出现最频繁的那个英文字母. 输入格式: 输入在一行中给出一个长度不超过1000的字符串.字符串由ASCII码表中任意可见字符及空格组成,至少包含1个英文字母,以回车结束( ...