Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目。通过如下命令即可创建 Scrapy 项目:
scrapy startproject ZhipinSpider
在上面命令中,scrapy 是Scrapy 框架提供的命令;startproject 是 scrapy 的子命令,专门用于创建项目;ZhipinSpider 就是要创建的项目名。
scrapy 除提供 startproject 子命令之外,它还提供了 fetch(从指定 URL 获取响应)、genspider(生成蜘蛛)、shell(启动交互式控制台)、version(查看 Scrapy 版本)等常用的子命令。可以直接输入 scrapy 来查看该命令所支持的全部子命令。
运行上面命令,将会看到如下输出结果:
New Scrapy project 'ZhipinSpider', using template directory 'd:\python3.6\lib\site-packages\scrapy\templates\project', created in:
C:\Users\mengma\ZhipinSpider You can start your first spider with:
cd ZhipinSpider
scrapy genspider example example.com
上面信息显示 Scrapy 在当前目录下创建了一个 ZhipinSpider 项目,此时在当前目录下就可以看到一个 ZhipinSpider 目录,该目录就代表 ZhipinSpider 项目。
查看 ZhipinSpider 项目,可以看到如下文件结构:
ZhipinSpider
│ scrapy.cfg
│
└──ZhipinSpider
│ item.py
│ middlewares.py
│ pipelines.py
│ setting.py
│
├─ spiders
│ │ __init__.py
│ │
│ └─ __pycache__
└─ __pycache__
下面大致介绍这些目录和文件的作用:
- scrapy.cfg:项目的总配置文件,通常无须修改。
- ZhipinSpider:项目的 Python 模块,程序将从此处导入 Python 代码。
- ZhipinSpider/items.py:用于定义项目用到的 Item 类。Item 类就是一个 DTO(数据传输对象),通常就是定义 N 个属性,该类需要由开发者来定义。
- ZhipinSpider/pipelines.py:项目的管道文件,它负责处理爬取到的信息。该文件需要由开发者编写。
- ZhipinSpider/settings.py:项目的配置文件,在该文件中进行项目相关配置。
- ZhipinSpider/spiders:在该目录下存放项目所需的蜘蛛,蜘蛛负责抓取项目感兴趣的信息。
为了更好地理解 Scrapy 项目中各组件的作用,下面给出 Scrapy 概览图,如图 1 所示。
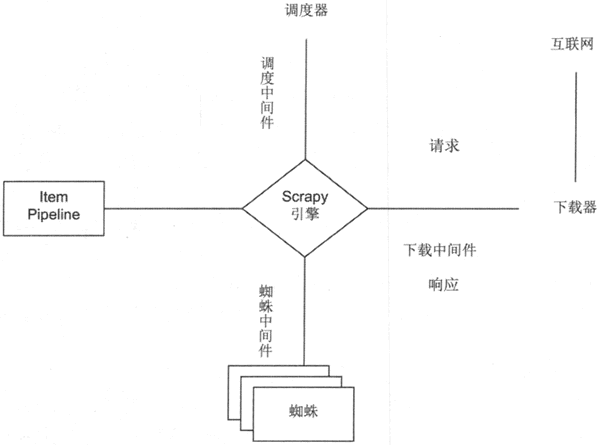
图 1 Scrapy 概览图
在图 1 中可以看到,Scrapy 包含如下核心组件:
- 调度器:该组件由 Scrapy 框架实现,它负责调用下载中间件从网络上下载资源。
- 下载器:该组件由 Scrapy 框架实现,它负责从网络上下载数据,下载得到的数据会由 Scrapy 引擎自动交给蜘蛛。
- 蜘蛛:该组件由开发者实现,蜘蛛负责从下载数据中提取有效信息。蜘蛛提取到的信息会由 Scrapy 引擎以 Item 对象的形式转交给 Pipeline。
- Pipeline:该组件由开发者实现,该组件接收到 Item 对象(包含蜘蛛提取的信息)后,可以将这些信息写入文件或数据库中。
经过上面分析可知,使用 Scrapy 开发网络爬虫主要就是开发两个组件,蜘蛛和 Pipeline。
Python Scrapy项目创建(基础普及篇)的更多相关文章
- Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情 一.新建项目(scrapy startproject) 在开始爬取之前,必须创建一个新的Scrapy项目.进入自定义的项目目录中,运行下列命令: PS C:\scra ...
- python Django 项目创建
注:后续如不特色说明,使用python版本均为python3 创建项目 django-admin startproject projectName 启动服务 python manage.py runs ...
- python django项目创建及前期准备(使用pycharm)
一.创建django项目 1.打开pycharm软件 2.点击菜单栏 File-->New Project,弹出如下对话框,如下图设置 二.基本配置 1.静态文件目录配置(用于客户端访问后台服务 ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- cocos2dx基础篇(1) Cocos2D-X项目创建
已经入行工作半年多时间了,以前都是把这些东西记录在有道云上面的,现在抽出些时间把以前的笔记腾过来. 具体的环境配置就不用说了,因为现在已经是2018年,只需要下载对应版本解压后就能使用,不用再像多年前 ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- (转)Python成长之路【第九篇】:Python基础之面向对象
一.三大编程范式 正本清源一:有人说,函数式编程就是用函数编程-->错误1 编程范式即编程的方法论,标识一种编程风格 大家学习了基本的Python语法后,大家就可以写Python代码了,然后每个 ...
随机推荐
- 《代码整洁之道》(Clean Code)- 读书笔记
一.关于Bob大叔的Clean Code <代码整洁之道>主要讲述了一系列行之有效的整洁代码操作实践.软件质量,不但依赖于架构及项目管理,而且与代码质量紧密相关.这一点,无论是敏捷开发流派 ...
- 《HelloGitHub》第 27 期
公告 网站新增了简单的搜索功能,可以通过项目名称或地址搜索.查看项目.欢迎star和推荐项目,我们一只在路上,希望志同道合者加入进来. 现招募专栏负责人: C# Java <HelloGitHu ...
- Chrome浏览器下自动填充的输入框背景
记录下从张鑫旭老师的微博中看到关于input输入框的属性 1.autocomplete="off" autocomplete 属性规定输入字段是否应该启用自动完成功能 自动完成允许 ...
- Neo4j入门之中国电影票房排行浅析
什么是Neo4j? Neo4j是一个高性能的NoSQL图形数据库(Graph Database),它将结构化数据存储在网络上而不是表中.它是一个嵌入式的.基于磁盘的.具备完全的事务特性的Java持 ...
- Vue源码解析(一):入口文件
在学习Vue源码之前,首先要做的一件事情,就是去GitHub上将Vue源码clone下来,目前我这里分析的Vue版本是V2.5.21,下面开始分析: 一.源码的目录结构: Vue的源码都在src目录下 ...
- Tomcat的常用内置对象
Tomcat的常用内置对象 1.request内置对象 所谓内置对象就是容器已经创建好了的对象,如果收到一个用户的请求就会自动创建一个对象来处理客户端发送的一些信息,这个内置对象就是request.类 ...
- 26 , CSS 构造表单
1. 表单标签使用 2. 下拉菜单背景 3. 滚动条的使用 4. 结构化表单布局 1 1 1 1. . . . 表单标签的使用 <label for=”name”>姓名: <inpu ...
- 可以让你神操作的手机APP推荐 个个都是爆款系列
手机在我们的生活中显得日益重要,根据手机依赖度调查显示,69%的人出门时必带手机,20%的人经常在吃饭睡觉.上卫生间时使用手机:43%的人早上起床第一件事就是查看手机,不用多说,我们对于手机的依赖性越 ...
- 海量数据,大数据处理技术--【Hbase】
- 【Java】itext根据模板生成pdf(包括图片和表格)
1.导入需要的jar包:itext-asian-5.2.0.jar itextpdf-5.5.11.jar. 2.新建word文档,创建模板,将文件另存为pdf,并用Adobe Acrobat DC打 ...