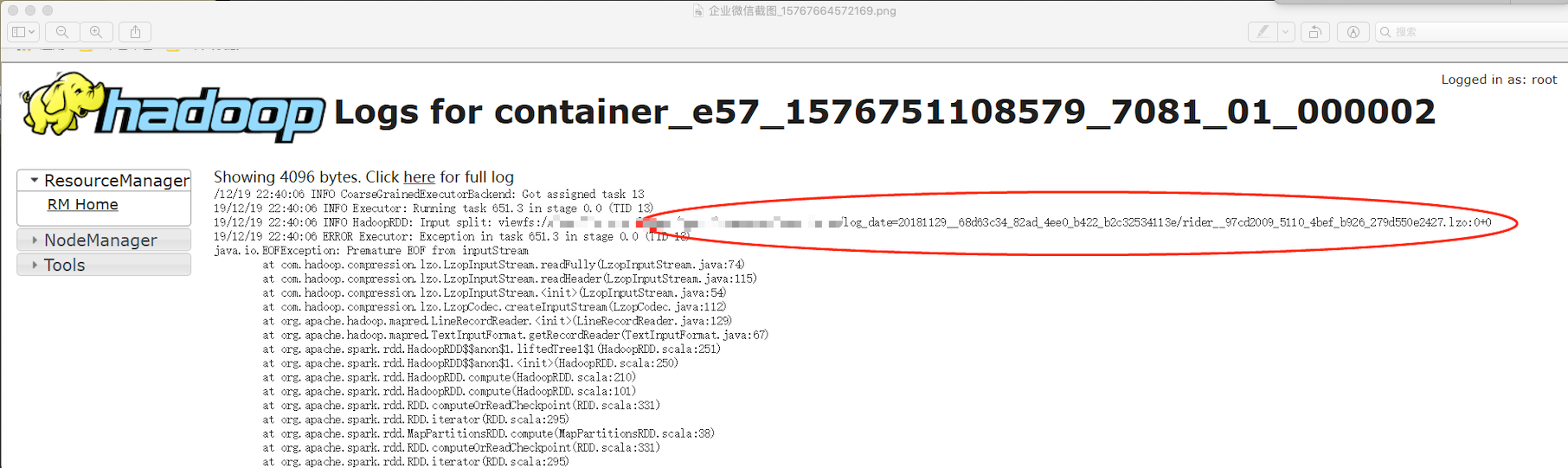
spark 执行报错 java.io.EOFException: Premature EOF from inputStream
使用spark2.4跟spark2.3 做替代公司现有的hive选项。
跑个别任务spark有以下错误
java.io.EOFException: Premature EOF from inputStream
at com.hadoop.compression.lzo.LzopInputStream.readFully(LzopInputStream.java:74)
at com.hadoop.compression.lzo.LzopInputStream.readHeader(LzopInputStream.java:115)
at com.hadoop.compression.lzo.LzopInputStream.<init>(LzopInputStream.java:54)
at com.hadoop.compression.lzo.LzopCodec.createInputStream(LzopCodec.java:112)
at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:129)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:269)
at org.apache.spark.rdd.HadoopRDD$$anon$1.<init>(HadoopRDD.scala:268)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:226)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:97)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:105)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
排查原因 发现是读取0 size 大小的文件时出错
并没有发现spark官方有修复该bug
手动修改代码 过滤掉这种文件
在 HadoopRDD.scala 类相应位置修改如图即可
// We get our input bytes from thread-local Hadoop FileSystem statistics.
// If we do a coalesce, however, we are likely to compute multiple partitions in the same
// task and in the same thread, in which case we need to avoid override values written by
// previous partitions (SPARK-13071).
private def updateBytesRead(): Unit = {
getBytesReadCallback.foreach { getBytesRead =>
inputMetrics.setBytesRead(existingBytesRead + getBytesRead())
}
} private var reader: RecordReader[K, V] = null
private val inputFormat = getInputFormat(jobConf)
HadoopRDD.addLocalConfiguration(
new SimpleDateFormat("yyyyMMddHHmmss", Locale.US).format(createTime),
context.stageId, theSplit.index, context.attemptNumber, jobConf) reader =
try {
if (split.inputSplit.value.getLength != 0) { //文件大小不为零 采取读取
inputFormat.getRecordReader(split.inputSplit.value, jobConf, Reporter.NULL)
} else {
logWarning(s"Skipped the file size 0 file: ${split.inputSplit}")
finished = true //大小为0 即结束 跳过
null
}
} catch {
case e: FileNotFoundException if ignoreMissingFiles =>
logWarning(s"Skipped missing file: ${split.inputSplit}", e)
finished = true
null
// Throw FileNotFoundException even if `ignoreCorruptFiles` is true
case e: FileNotFoundException if !ignoreMissingFiles => throw e
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
null
}
// Register an on-task-completion callback to close the input stream.
context.addTaskCompletionListener[Unit] { context =>
// Update the bytes read before closing is to make sure lingering bytesRead statistics in
// this thread get correctly added.
updateBytesRead()
closeIfNeeded()
}
spark 执行报错 java.io.EOFException: Premature EOF from inputStream的更多相关文章
- 关于spark入门报错 java.io.FileNotFoundException: File file:/home/dummy/spark_log/file1.txt does not exist
不想看废话的可以直接拉到最底看总结 废话开始: master: master主机存在文件,却报 执行spark-shell语句: ./spark-shell --master spark://ma ...
- Spark启动报错|java.io.FileNotFoundException: File does not exist: hdfs://hadoop101:9000/directory
at org.apache.spark.deploy.history.FsHistoryProvider.<init>(FsHistoryProvider.scala:) at org.a ...
- hadoop MR 任务 报错 "Error: java.io.IOException: Premature EOF from inputStream at org.apache.hadoop.io"
错误原文分析 文件操作超租期,实际上就是data stream操作过程中文件被删掉了.一般是由于Mapred多个task操作同一个文件.一个task完毕后删掉文件导致. 这个错误跟dfs.datano ...
- hbase_异常_03_java.io.EOFException: Premature EOF: no length prefix available
一.异常现象 更改了hadoop的配置文件:core-site.xml 和 mapred-site.xml 之后,重启hadoop 和 hbase 之后,发现hbase日志中抛出了如下异常: ...
- Spark报错java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Spark 读取 JSON 文件时运行报错 java.io.IOException: Could not locate executable null\bin\winutils.exe in the ...
- 关于SpringMVC项目报错:java.io.FileNotFoundException: Could not open ServletContext resource [/WEB-INF/xxxx.xml]
关于SpringMVC项目报错:java.io.FileNotFoundException: Could not open ServletContext resource [/WEB-INF/xxxx ...
- Kafka 启动报错java.io.IOException: Can't resolve address.
阿里云上 部署Kafka 启动报错java.io.IOException: Can't resolve address. 本地调试的,报错 需要在本地添加阿里云主机的 host 映射 linux ...
- 文件上传报错java.io.FileNotFoundException拒绝访问
局部代码如下: File tempFile = new File("G:/tempfileDir"+"/"+fileName); if(!tempFile.ex ...
- 完美解决JavaIO流报错 java.io.FileNotFoundException: F:\ (系统找不到指定的路径。)
完美解决JavaIO流报错 java.io.FileNotFoundException: F:\ (系统找不到指定的路径.) 错误原因 读出文件的路径需要有被拷贝的文件名,否则无法解析地址 源代码(用 ...
随机推荐
- bzoj2725
* 给出一张图 * 每次删掉一条边后求 the shortest path from S to T * 线段树维护最短路径树 * 具体维护从某点开始偏离最短路而到达 T 的最小距离 * 首先记录下最短 ...
- Codeforces Round #521 (Div.3)题解
A过水,不讲 题解 CF1077B [Disturbed People] 这题就是个显而易见的贪心可是我考场上差点没想出来 显然把一户被打扰的人家的右边人家的灯关掉肯定比把左边的灯关掉 从左到右扫一遍 ...
- Linux下查看文件和文件夹大小 df,du命令
转自 http://www.cnblogs.com/benio/archive/2010/10/13/1849946.html df可以查看一级文件夹大小.使用比例.档案系统及其挂入点,但对文件却无能 ...
- vue项目,前端导出excel
今天研究一下前端如何导出excel,边查边实践,边记录 1.安装依赖库 xlsx:这是一个功能强大的excel处理库,但是上手难度也很大,还涉及不少二进制的东西 file-saver:ES5新增了相关 ...
- Irrlicht引擎剖析一
代码风格: 1.接口以I开头,实现以C开头,保存数据的结构体以S开头 2.函数名以小写字母开头,变量以大字母开头 3.接口的公共函数,其参数大部分给了默认值 4.采用名字空间 名字空间i ...
- 两大主流开源分布式存储的对比:GlusterFS vs. Ceph
两大主流开源分布式存储的对比:GlusterFS vs. Ceph 存储世界最近发生了很大变化.十年前,光纤通道SAN管理器是企业存储的绝对标准,但现在的存储必须足够敏捷,才能适应在新的基础架构即服务 ...
- Event---事件详解
1.焦点事件 焦点:使浏览器能够区分用户输入的对象,当一个元素有焦点的时候,那么他就可以接收用户的输入. 可以通过以下方式给元素设置焦点: 点击.tab.js 不是所有元素都能够接收焦点的,能够响应用 ...
- SQL-W3School-高级:SQL VIEW(视图)
ylbtech-SQL-W3School-高级:SQL VIEW(视图) 1.返回顶部 1. 视图是可视化的表. 本章讲解如何创建.更新和删除视图. SQL CREATE VIEW 语句 什么是视图? ...
- kotlin 修饰符
在kotlin中有四种修饰符: private 仅在类的内部使用 protected类似private,但在子类中可以访问 internal任何在模块内部类都可以访问 public:任何类都可以访问
- PHP mysql_num_rows() 函数 返回结果集中行的数目。
定义和用法 mysql_num_rows() 函数返回结果集中行的数目. 语法 mysql_num_rows(data) 参数 描述 data 必需.结果集.该结果集从 mysql_query() 的 ...