4.3. Scrapy Shell
Scrapy Shell:模拟scrapy去发送请求
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
启动Scrapy Shell
进入项目的根目录,执行下列命令来启动shell,相当于response:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
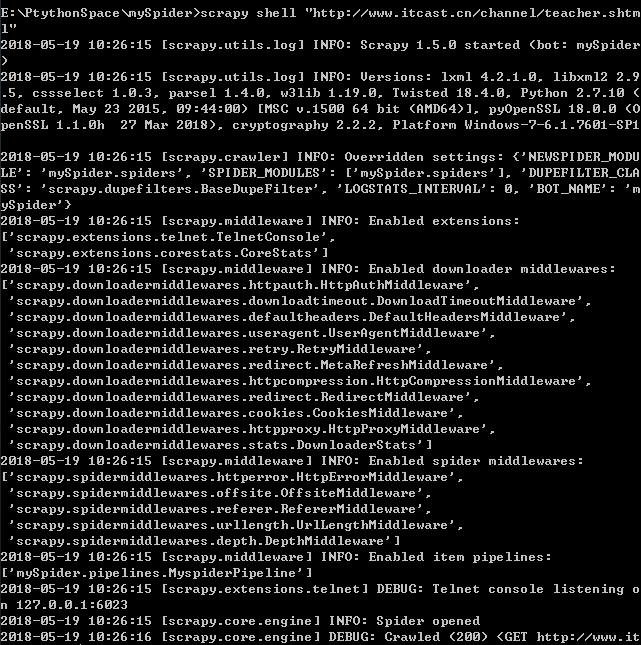
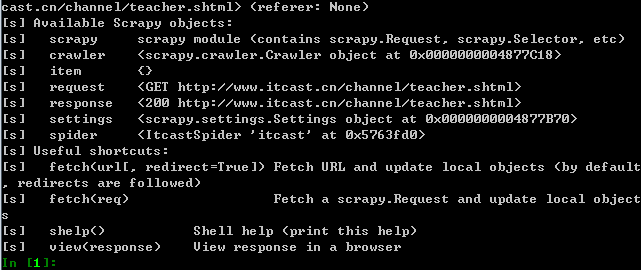
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 Selector 对象 (对HTML及XML内容)。
当shell载入后,将得到一个包含response数据的本地 response 变量,输入
response.body将输出response的包体,输出response.headers可以看到response的包头。输入
response.selector时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用response.selector.xpath()或response.selector.css()来对 response 进行查询。Scrapy也提供了一些快捷方式, 例如
response.xpath()或response.css()同样可以生效(如之前的案例)。
Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
extract(): 序列化该节点为Unicode字符串并返回list
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
XPath表达式的例子及对应的含义:
/html/head/title: 选择<HTML>文档中 <head> 标签内的 <title> 元素
/html/head/title/text(): 选择上面提到的 <title> 元素的文字
//td: 选择所有的 <td> 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
尝试Selector
我们用腾讯社招的网站http://hr.tencent.com/position.php?&start=0#a举例:
# 启动
scrapy shell "http://hr.tencent.com/position.php?&start=0#a" # 返回 xpath选择器对象列表
response.xpath('//title')
[<Selector xpath='//title' data=u'<title>\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058</title'>] # 使用 extract()方法返回 Unicode字符串列表
response.xpath('//title').extract()
[u'<title>\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058</title>'] # 打印列表第一个元素,终端编码格式显示
print response.xpath('//title').extract()[0]
<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title> # 返回 xpath选择器对象列表
response.xpath('//title/text()')
<Selector xpath='//title/text()' data=u'\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058'> # 返回列表第一个元素的Unicode字符串
response.xpath('//title/text()')[0].extract()
u'\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058' # 按终端编码格式显示
print response.xpath('//title/text()')[0].extract()
职位搜索 | 社会招聘 | Tencent 腾讯招聘 response.xpath('//*[@class="even"]')
职位名称: print site[0].xpath('./td[1]/a/text()').extract()[0]
TEG15-运营开发工程师(深圳)
职位名称详情页: print site[0].xpath('./td[1]/a/@href').extract()[0]
position_detail.php?id=20744&keywords=&tid=0&lid=0
职位类别: print site[0].xpath('./td[2]/text()').extract()[0]
技术类
以后做数据提取的时候,可以把现在Scrapy Shell中测试,测试通过后再应用到代码中,当然Scrapy Shell作用不仅仅如此
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html
4.3. Scrapy Shell的更多相关文章
- Scrapy shell调试网页的信息
通过scrapy shell "http://www.thinkive.cn:10000/zentaopms/www/index.php?m=user&f=login"
- scrapy shell 中文网站输出报错.记录.
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 381-382: illegal multibyte sequence 上 ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- Scrapy Shell的使用
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- 14.Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- scrapy shell的作用
1.可以方便我们做一些数据提取的测试代码: 2.如果想要执行scrapy命令,那么毫无疑问,肯定是要先进入到scrapy所在的环境中: 3.如果想要读取某个项目的配置信息,那么应该先进入到这个项目中. ...
- Scrapy shell调试返回403错误
一.问题描述 有时候用scrapy shell来调试很方便,但是有些网站有防爬虫机制,所以使用scrapy shell会返回403,比如下面 C:\Users\fendo>scrapy shel ...
- scrapy shell
一.scrapy shell 1.安装pip install Jupyter 2.在pycharm中的启动命令: scrapy shell 注:启动后关键字高亮显示 3.查看response 执行sc ...
- 在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0, 时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步. 本文展示使用在 Scrapy项目内.项目外scrap ...
随机推荐
- java数据结构之HashSet和TreeSet以及LinkedHashSet
一.HashSet源码注释 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cl ...
- liunx 中如何删除export设置的环境变量
1,网上有资料说,export命令添加的环境变量,利用export -p 删除: 例如:export KUBECONFIG="/etc/kubernetes/admin.conf" ...
- 解读Vue.use()源码
Vue.use() vue.use()的作用: 官方文档的解释: 安装 Vue.js 插件.如果插件是一个对象,必须提供 install 方法.如果插件是一个函数,它会被作为 install 方法.i ...
- Linux中脚本运行错误(坏的解释器:没有那个文件或目录)
原因: 在Linux中有时候我们将在Windows下编写的脚本拷贝到Linux环境中运行时会出现运行不了的情况. 主要还是Windows的换行符为\r\n,而Linux环境中的换行符号为\n. 解决办 ...
- element UI实现动态生成多级表头
一.效果图 二.封装两个组件,分别为DynamicTable.vue和TableColumn.vue,TableColumn.vue主要是使用递归来对表头进行循环生成 DynamicTable.vue ...
- C#ModBus Tcp
C#ModBus Tcp 报文解析 上一篇博客已经完成 C#ModBus Tcp Master的实现 本篇主要对不同的功能码所发出的报文进行解析(包括请求报文及响应报文) 读操作 功能码 0x01 ...
- 简单的搭载Spring cloud框架
大家不懂的可以在评论区给我留言
- [转帖]LINUX网络配置---nmtui&nmcli
LINUX网络配置---nmtui&nmcli https://blog.51cto.com/13625527/2151853?source=dra 两年前曾经打打印过 几页命令 里面就有 n ...
- SQLite进阶-12.Distinct关键字
目录 DISTINCT关键字 DISTINCT关键字 DISTINCT关键字与SELECT语句一起使用,用来消除重复数据,获得唯一数据. -- 语句 SELECT DISTINCT column1, ...
- 今天遇到了不能创建mysql函数
今天用navicat 不能创建函数,查询了 MySQL函数不能创建,是未开启功能: mysql> show variables like '%func%'; +----------------- ...