scrapy 爬取纵横网实战
前言
闲来无事就要练练代码,不知道最近爬取什么网站好,就拿纵横网爬取我最喜欢的雪中悍刀行练手吧
准备
- python3
- scrapy
项目创建:
cmd命令行切换到工作目录创建scrapy项目 两条命令 scarpy startproject与scrapy genspider 然后用pycharm打开项目
D:\pythonwork>scrapy startproject zongheng
New Scrapy project 'zongheng', using template directory 'c:\users\11573\appdata\local\programs\python\python36\lib\site-packages\scrapy\templates\project', created in:
D:\pythonwork\zongheng You can start your first spider with:
cd zongheng
scrapy genspider example example.com D:\pythonwork>cd zongheng D:\pythonwork\zongheng>cd zongheng D:\pythonwork\zongheng\zongheng>scrapy genspider xuezhong http://book.zongheng.com/chapter/189169/3431546.html
Created spider 'xuezhong' using template 'basic' in module:
zongheng.spiders.xuezhong
确定内容
首先打开网页看下我们需要爬取的内容
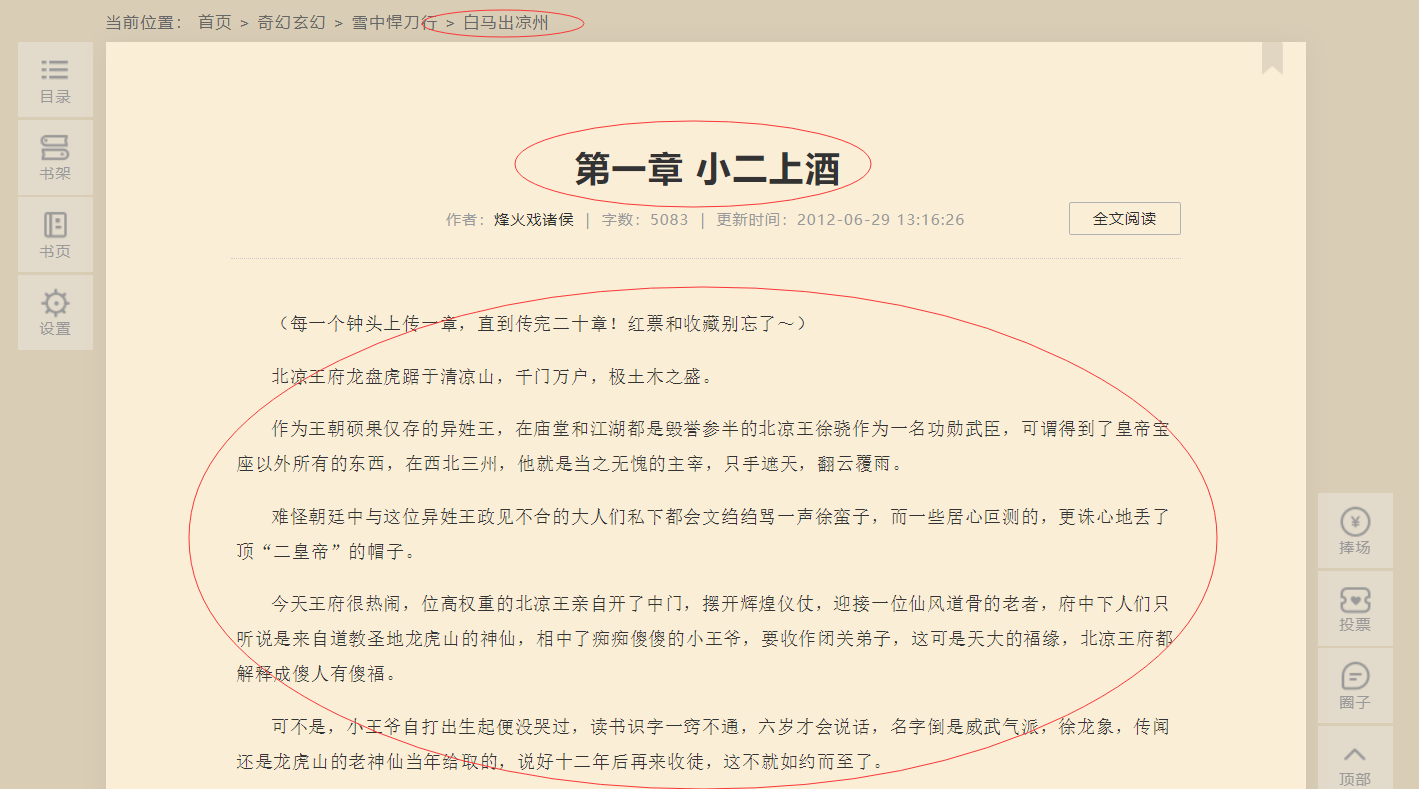
其实小说的话结构比较简单 只有三大块 卷 章节 内容
因此 items.py代码:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ZonghengItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
book = scrapy.Field()
section = scrapy.Field()
content = scrapy.Field()
pass
内容提取spider文件编写
还是我们先创建一个main.py文件方便我们测试代码
from scrapy import cmdline
cmdline.execute('scrapy crawl xuezhong'.split())
然后我们可以在spider文件中先编写
# -*- coding: utf-8 -*-
import scrapy class XuezhongSpider(scrapy.Spider):
name = 'xuezhong'
allowed_domains = ['http://book.zongheng.com/chapter/189169/3431546.html']
start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/'] def parse(self, response):
print(response.text)
pass
运行main.py看看有没有输出
发现直接整个网页的内容都可以爬取下来,说明该网页基本没有反爬机制,甚至不用我们去修改user-agent那么就直接开始吧
打开网页 F12查看元素位置 并编写xpath路径 然后编写spider文件
需要注意的是我们要对小说内容进行一定量的数据清洗,因为包含某些html标签我们需要去除
# -*- coding: utf-8 -*-
import scrapy
import re
from zongheng.items import ZonghengItem class XuezhongSpider(scrapy.Spider):
name = 'xuezhong'
allowed_domains = ['book.zongheng.com']
start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/'] def parse(self, response):
xuezhong_item = ZonghengItem()
xuezhong_item['book'] = response.xpath('//*[@id="reader_warp"]/div[2]/text()[4]').get()[3:]
xuezhong_item['section'] = response.xpath('//*[@id="readerFt"]/div/div[2]/div[2]/text()').get() content = response.xpath('//*[@id="readerFt"]/div/div[5]').get()
#content内容需要处理因为会显示<p></p>标签和<div>标签
content = re.sub(r'</p>', "", content)
content = re.sub(r'<p>|<div.*>|</div>',"\n",content ) xuezhong_item['content'] = content
yield xuezhong_item nextlink = response.xpath('//*[@id="readerFt"]/div/div[7]/a[3]/@href').get()
print(nextlink)
if nextlink:
yield scrapy.Request(nextlink,callback=self.parse)
有时候我们会发现无法进入下个链接,那可能是被allowed_domains过滤掉了 我们修改下就可以
唉 突然发现了到第一卷的一百多章后就要VIP了 那我们就先只弄一百多章吧 不过也可以去其他网站爬取免费的 这次我们就先爬取一百多章吧
内容保存
接下来就是内容的保存了,这次就直接保存为本地txt文件就行了
首先去settings.py文件里开启 ITEM_PIPELINES
然后编写pipelines.py文件
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html class ZonghengPipeline(object):
def process_item(self, item, spider):
filename = item['book']+item['section']+'.txt'
with open("../xuezhongtxt/"+filename,'w') as txtf:
txtf.write(item['content'])
return item
由于选址失误导致了我们只能爬取免费的一百多章节,尴尬,不过我们可以类比运用到其他网站爬取全文免费的书籍
怎么样 使用scrapy爬取是不是很方便呢

scrapy 爬取纵横网实战的更多相关文章
- 使用scrapy爬取海外网学习频道
一:创建项目文件 1:首先在终端使用命令scrapy startproject huaerjieribao 创建项目 2:创建spider 首先cd进去刚刚创建的项目文件overseas 然后执行ge ...
- scrapy 爬取当当网产品分类
#spider部分import scrapy from Autopjt.items import AutopjtItem from scrapy.http import Request class A ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- scrapy爬取相似页面及回调爬取问题(以慕课网为例)
以爬取慕课网数据为例 慕课网的数据很简单,就是通过get方式获取的 连接地址为https://www.imooc.com/course/list?page=2 根据page参数来分页
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
随机推荐
- D-【乐】k进制数(同余)
题目 https://ac.nowcoder.com/acm/contest/907/D 做法 \((x)_k\)定义编号,如果\(a+b\)加到一起能进一位,\(a+b\rightarrow 1+( ...
- 【2018.07.29】(深度优先搜索/回溯)学习DFS算法小记
参考网站:https://blog.csdn.net/ldx19980108/article/details/76324307 这个网站里有动态图给我们体现BFS和DFS的区别:https://www ...
- Django 测试开发4 Django 模板和分页器
Django结合前端框架Bootstrap来开发web页面.pip install django-bootstrap3 在setting.py添加‘bootstrap3’. 继承模板. 在base页面 ...
- MacOS系统降级
从MacOS 10.14 降级到 10.12,下载好系统镜像文件.打开,复制到Application. 准备一个至少8G的U盘,,打开磁盘工具,『抹掉』(格式化)成Mac OS扩展(日志式),名称可随 ...
- TreeSet和TreeMap不能存放重复元素?能不能存放null?其实不是这样的——灵活的二叉树
TreeSet和TreeMap不能存放重复元素?能不能存放null?其实不是这样的——灵活的二叉树 本文链接:https://blog.csdn.net/u010698072/article/de ...
- Mongo查询百万级数据性能问题及JAVA优化问题
Mongo查询百万级数据 使用分页 skip和limit 效率会相当慢 那么怎么解决呢 上代码 全部查询数据也会特别慢 Criteria criteria = new Criteria(); ...
- jmeter 查看结果树,获取响应体写法校验是否提取写法是否正确的方法
JSON Path Expression里面写入提出值的写法,点击Test测试提取
- Linux -- PHP-FPM的源码解析和模型
1.进程管理模式 PHP-FPM由1个master进程和N个worker进程组成.其中,Worker进程由master进程fork而来. PHP-FPM有3种worker进程管理模式. 1. Stat ...
- 多线程分页处理批量数据--jdbc方式
/** * 同步数据信息到ES * @return */ public boolean syncNhReportSeessToEs(){ long begin = System.currentTime ...
- CentOS7下配置Tomcat以APR模式+Tomcat Native运行
在慢速网络上Tomcat线程数开到300以上的水平,不配APR,基本上300个线程狠快就会用满,以后的请求就只好等待.但是配上APR之后,Tomcat将以JNI的形式调用Apache HTTP服务器的 ...