<爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况:
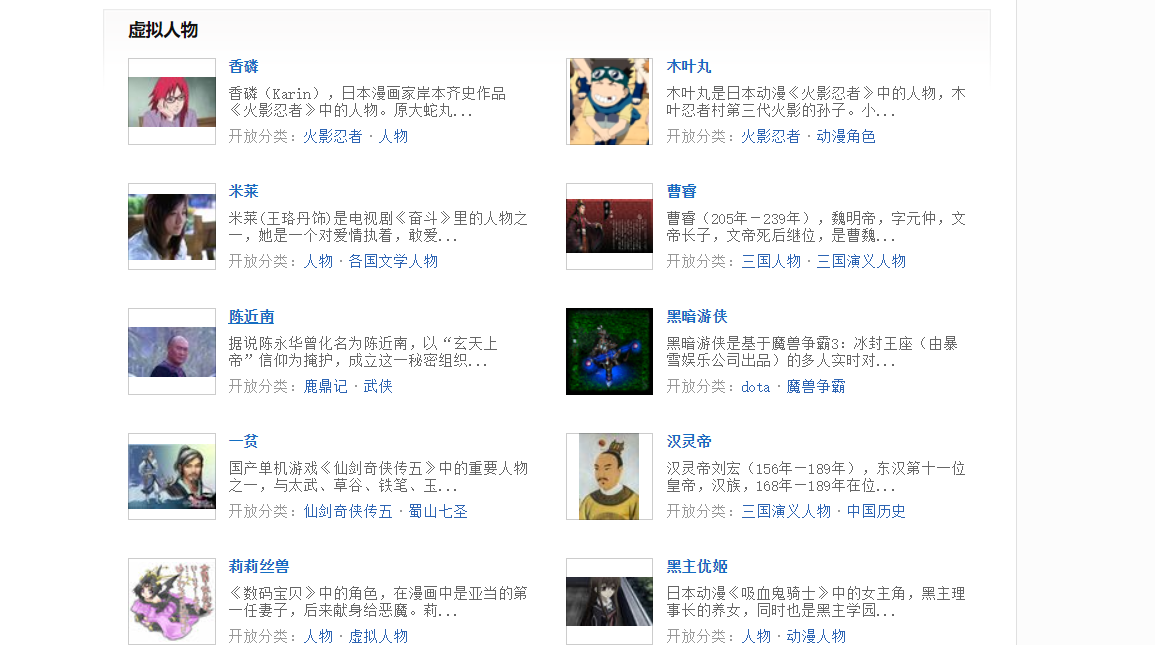
代码:
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup as bs
import re
import time
import pymysql def get_one_page(url):
#得到一页的内容
try:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
return None def parse_one_page(html):
#使用BeautifuSoup解析一页的内容
soup = bs(html,'lxml')
for data in soup.find_all('div',class_="photo"):
name = data.a['title']
href = "https://baike.baidu.com"+data.a['href']
img = data.img['src']
#有些人物没有图片,图片链接有误需要拼接
if re.search("^/static",img):
img ="https://baike.baidu.com" + img
yield {
'name':name,
'href':href,
'img':img
} def write_mysql(item):
#写入Mysql数据库
conn = pymysql.connect(
host='localhost',
user='root',
password='',
database='baidu',
charset='utf8' # 别写成utf-8
)
cursor = conn.cursor() # 建立游标 sql = "insert into baidu_baike(name,href,img) values(%s,%s,%s)"
cursor.execute(sql,(item['name'],item['href'],item['img'])) # 注意excute的位置参数的问题
conn.commit() # 修改值的时候,一定需要commit
cursor.close() # 关闭
conn.close() # 关闭 def main(url):
#主函数
html = get_one_page(url)
items = parse_one_page(html)
for item in items:
write_mysql(item) if __name__ == '__main__':
#分析URL构成,拼接URL
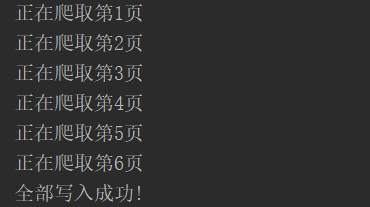
for i in range(1,7):
url = "http://baike.baidu.com/fenlei/虚拟人物?limit=30&index=" + str(i) + "&offset=" + str(
30 * (int(i) - 1)) + "# gotoList"
main(url)
print('正在爬取第%s页'%i)
time.sleep(1)
print("全部写入成功!")
运行结果:
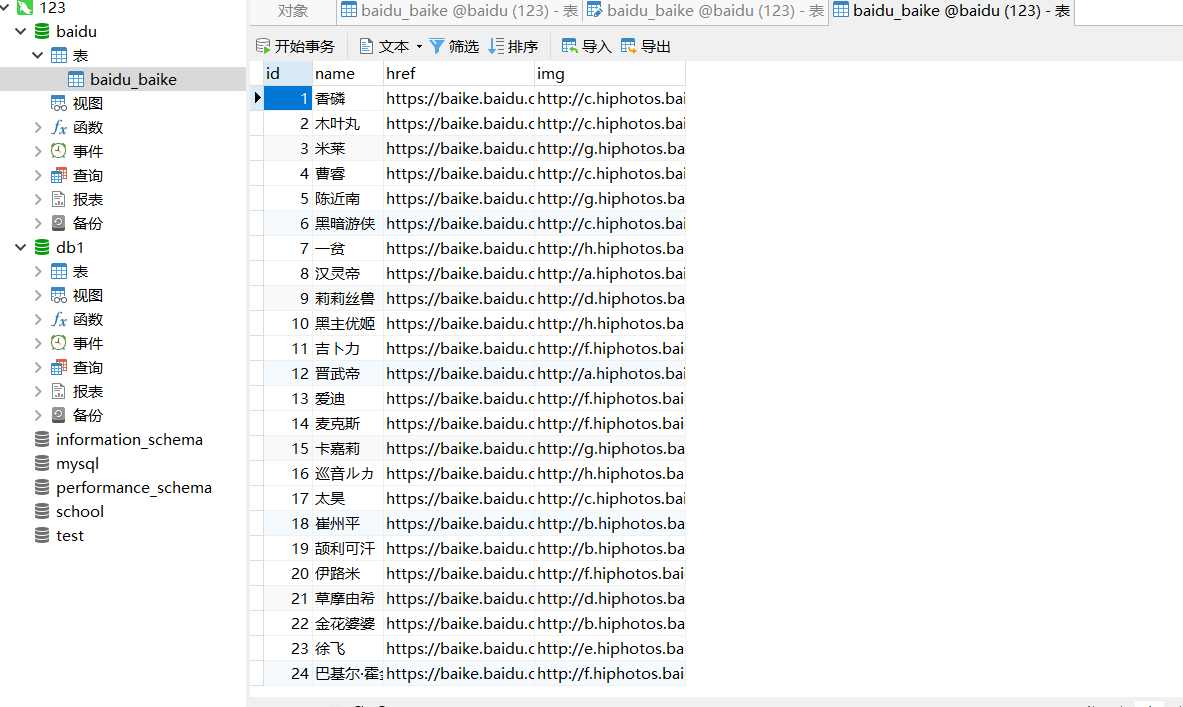
mysql数据库结果:
<爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库的更多相关文章
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业 说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me) 例如 互 ...
随机推荐
- Tesseract&tesseractOCRiOS
安装tesseract在上篇. 1.安装之后默认语言包只有英文包,在github上下载中文简体,链接:https://github.com/tesseract-ocr/tessdata 然后放入tes ...
- 《构建之法》CH5~6读书笔记 PB16110698 第九周(~5.15)
这段时间我阅读了<构建之法>的大部分章节,包括个人技能.软件测试.用户体验和需求分析等相关内容.之前的个人作业和结对作业结束后,我们的工作重心终于转向了团队项目,作为团队中前端组的组长,我 ...
- List<> ,string[]和string的相互转换
1.string转换成string[]数组 string str = "aaa,bbb,ccc,dddd"; string[] strs = str.Split(','); 2.s ...
- Spring知识点整理
1.bean什么时候被实例化 第一:如果你使用BeanFactory作为Spring Bean的工厂类,则所有的bean都是在第一次使用该Bean的时候实例化第二:如果你使用ApplicationCo ...
- leetcode-220-存在重复元素③*
题目描述: 方法一:二叉搜索树+滑动窗口 方法二:桶排序 O(N) class Solution: def containsNearbyAlmostDuplicate(self, nums: List ...
- Eclipse注释快捷键、如何生成API以及可能遇到的问题解决
1.Java注释方式单行注释// 快捷键:ctrl+/多行注释/* 快捷键:shift+ctrl+/*/文档注释/** 快捷键:shift+Alt+j */ 2.生成API文档 打开index.htm ...
- NOI2016
luoguP1712 [NOI2016]区间 这是一道送分题. 对于我这种每天抄题解不动脑子思维僵化得厉害的智障选手就是送命题. 一直在想端点排序各种Treap搞... 正解: 已知一些区间,如何判断 ...
- c++中变量、变量名、变量地址、指针、引用等含义
首先了解内存,内存就是一排房间,编号从0开始,0,1,2,3,4,5...... 房间里面一定要住人,新人住进去了,原来的人就走了:不管你住不住,里面都有人. 编号就是地址.里面的人就是内容,为了我们 ...
- JS switch 分支语句
描述:根据一个变量的不同取值,来执行不同的代码. 语法结构: switch(变量) { case 值1: 代码1; break; case 值2: 代码2; break; case 值3: 代码3; ...
- linux环境变量设置错误后的恢复方法(转)
原文: http://blog.csdn.net/hoholook/article/details/2793447 linux环境变量设置错误后的恢复方法 中国自学编程网收集整理 发布日期:2008 ...