简单scrapy爬虫实例
简单scrapy爬虫实例
流程分析
抓取内容:网站课程
页面:https://edu.hellobi.com
数据:课程名、课程链接及学习人数
观察页面url变化规律以及页面源代码帮助我们获取所有数据
1、scrapy爬虫的创建
在pycharm的Terminal中输入以下命令:
创建scrapy项目:scrapy startproject ts
进入到项目目录中:cd first
创建一个新的spider:scrapy genspider -t basic lesson hellobi.com
2、scrapy爬虫代码编写
2.1items文件编写
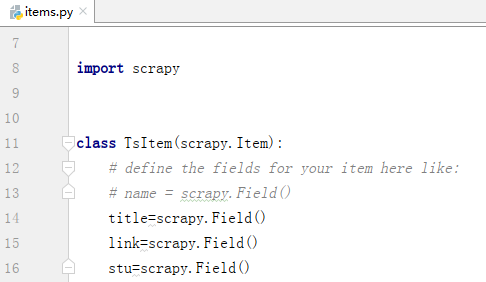
在items.py文件中定义自己要抓取的数据,我们要爬取天善智能网站的课程、课程链接和学习人数,需要这三者的数据,所以此时创建item的三个类。
2.2编写spider文件(lesson.py)
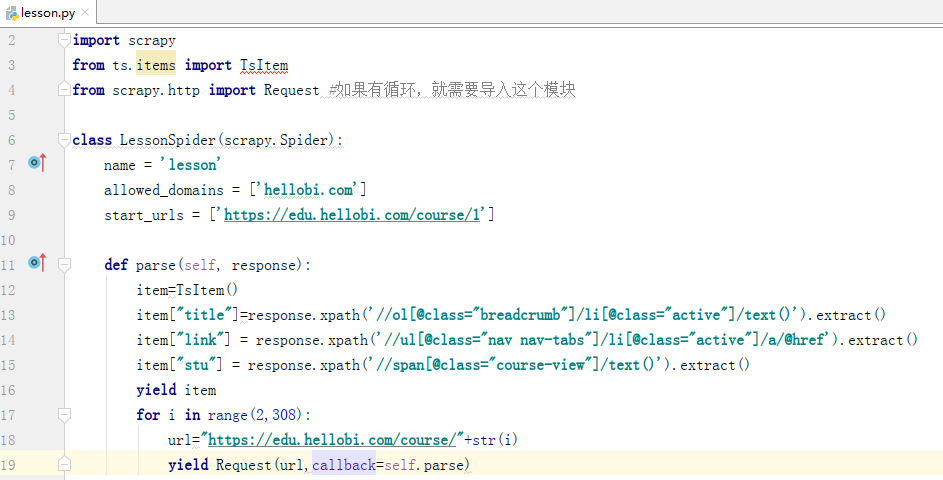
由于要提取该网站所有课程的消息,需要构造了所有的课程url。此时观察观察多个url,找出其中url变化的规律,以此来构造所有的url。由于每个课程都需要包含课程名、课程链接以及学习人数,所有设置相应的xpath,分别匹配item的三个类。
2.3修改pipeline.py的内容:
将爬取到的数据写入“F:/天善课程爬取/1.txt”中。

2.4修改settings.py文件,配置pipeline:

3、总结
至此,爬虫就全部编写完成了,在scrapy中xpath很重要,如果xpath提取错误的话,可能会造成许多错误。另外在输出和写入文件时也要注意,不然也会有错误发生。在程序的最后一定要关闭文件,不然最后打开文件的内容为空。
简单scrapy爬虫实例的更多相关文章
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- scrapy爬虫实例(1)
爬虫实例 对象 阳光问政平台 目标 : 主题,时间,内容 爬取思路 预先设置好items import scrapy class SuperspiderItem(scrapy.Item): title ...
- Scrapy爬虫实例——校花网
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地.Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能. Scrapy官方定义:Scrapy是用于抓取网 ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- Scrapy 爬虫实例教程(一)---简介及资源列表
Scrapy(官网 http://scrapy.org/)是一款功能强大的,用户可定制的网络爬虫软件包.其官方描述称:" Scrapy is a fast high-level screen ...
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- python scrapy 爬虫实例
1 创建一个项目 scrapy startproject basicbudejie 2 编写爬虫 import scrapy class Basicbudejie(scrapy.Spider): na ...
- 简单python爬虫实例
先放上url,https://music.douban.com/chart 这是豆瓣的一个音乐排行榜,这里爬取了左边部分的歌曲排行榜部分,爬虫很简单,就用到了beautifulsoup和request ...
随机推荐
- python笔记23(面向对象课程五)
今日内容 上节作业 单例模式 class Foo: pass obj1 = Foo() # 实例,对象 obj2 = Foo() # 实例,对象 日志模块(logging) 程序的目录结构 内容回顾 ...
- ViewPager调用notifyDataSetChanged() 刷新问题解决方案
一.问题来由 ViewPager控件很大程度上满足了开发者开发页面左右移动切换的功能,使用非常方便.但是使用中发现,在删除或者修改数据的时候,PagerAdapter无法像BaseAdapter那样仅 ...
- Python股票量化 选股操作不好用 完结
这几日,写了一些python的代码,打算来选择股票的, 那么这个思路和开始的一篇文章类似,你会不会被贾跃亭坑?,所以基本的思路也是这样的,举一个简单的例子,就是通过连续几年的ROE数据,和其他的一些财 ...
- Kubernetes label简单使用
# 查看集群中的node节点 # kubectl get nodes NAME STATUS ROLES AGE VERSION server01 Ready <none> 130d v1 ...
- 阿里妈妈的iconfont的引用问题
一.先进官网 我们看到了上面的这些图标,是不是很心动,阿里妈妈就是给力,给马老师点赞,但是问题来了我们怎么去使用呢. 二.点击图标 嘿嘿,上面的操作步骤我就不多说了吧,我相信大家都会做的,接下来我们就 ...
- 详细讲解Codeforces Round #624 (Div. 3) F. Moving Points
题意:给定n个点的初始坐标x和速度v(保证n个点的初始坐标互不相同), d(i,j)是第i个和第j个点之间任意某个时刻的最小距离,求出n个点中任意一对点的d(i,j)的总和. 题解:可以理解,两个点中 ...
- P2024 NOI2001 种类冰茶鸡
展开 题目描述 动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形.A 吃 B,B 吃 C,C 吃 A. 现有 N 个动物,以 1 - N 编号.每个动物都是 A,B,C 中的一种, ...
- 关于GC(垃圾回收)
当我用new创建一个对象时,当可分配的内存不足GC就会去回收未使用的对象,但是GC的操作是非常复杂的,会占用很多CPU时间,对于移动设备来说频繁的垃圾回收会严重影响性能.下面的建议可以避免GC频繁操作 ...
- java.lang.ClassCastException:java.util.LinkedHashMap不能转换为com.testing.models.xxx
后台接收前台的json字符串 转pojo 问题(Object 对应定义的pojo) ObjectMapper mapper=new ObjectMapper(); Object object = ma ...
- docker常见操作总结
一.原理 1.Hypervisor是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,它能直接访问物理设备,会给每一台虚拟机分配内存.CPU.网络.磁盘等资 ...