Python 爬虫-BeautifulSoup
2017-07-26 10:10:11
Beautiful Soup可以解析html 和 xml 格式的文件。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。使用BeautifulSoup库非常简单,只需要两行代码,就可以完成BeautifulSoup类的创建,这里命名为soup,接下来就可以对soup进行相关处理了。一个BeautifulSoup类对应html或者xml的全部内容。
BeautifulSoup库将任意html文件转换成utf-8格式

一、解析器
BeautifulSoup类创建的时候第二个参数是解析器,上面的代码中用的解析器为‘html.parser’,BeautifulSoup支持的解析器有:

二、BeautifulSoup类的基本元素


- 使用soup.tag来访问一个标签的内容,如:soup.title;soup.a等,这里的返回值为访问标签的第一个出现的值
- 使用soup.tag.name可以得到当前标签的名字,返回值为字符串,如:soup.a.name 会返回字符串 ‘a’,也可以使用soup.a.parent.name来查看 a 标签父母的名字
- 使用soup.tag.attrs可以得到当前标签的属性,返回值为一个字典,如果没有属性会返回一个空字典,如:soup.a.attrs 会返回 a 标签的属性信息
- 使用soup.tag.string可以得到当前标签的字符串,如:soup.a.string 会返回 a 标签的内容字符串
- 内容字符串有两种类型一是NavigableString类型,一种是Comment类型,Comment类型的格式是<p> <!-- This is an comment --></p>,在调用soup.p.string是会返回This is an comment,但是其类型是Comment类型。
三、soup的内容遍历
标签树的遍历有三种方式,即下行遍历,上行遍历和平行遍历。
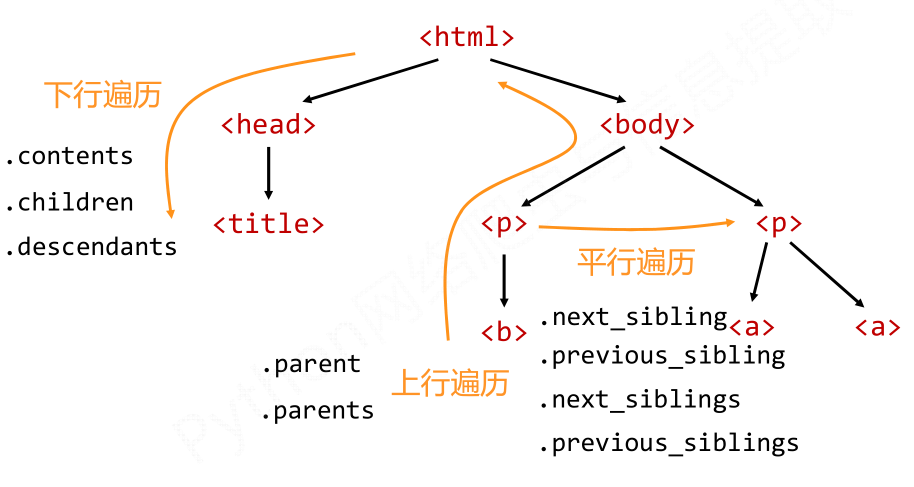
(1)下行遍历属性

举例:
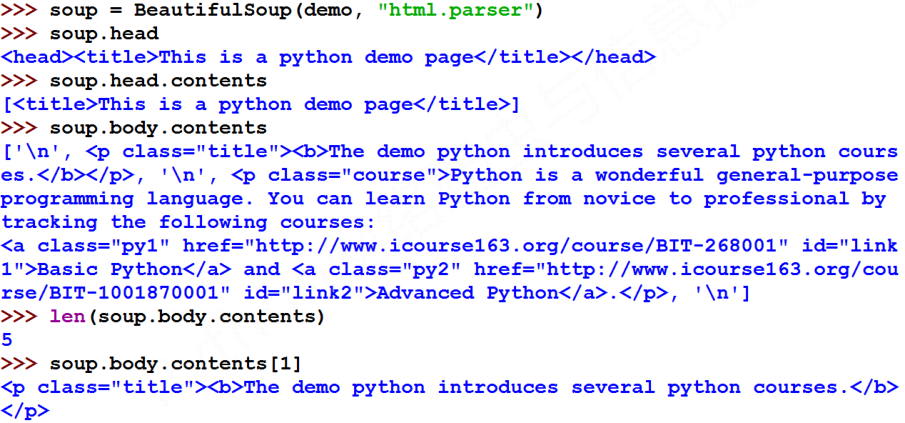
#遍历儿子节点
for child in soup.body.children:
print(child) #遍历子孙节点
for child in soup.body.descendants:
print(child)
值得注意的是子孙节点不仅包含标签,还包含标签之间的字符串类型,这点需要注意与排除。
(2)上行遍历的属性


soup.parent为空,需要进行区分,可以使用for循环对parents进行遍历:

(3)平行遍历的属性
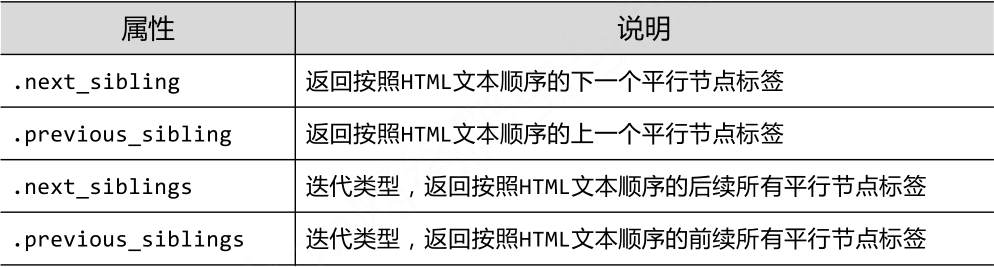
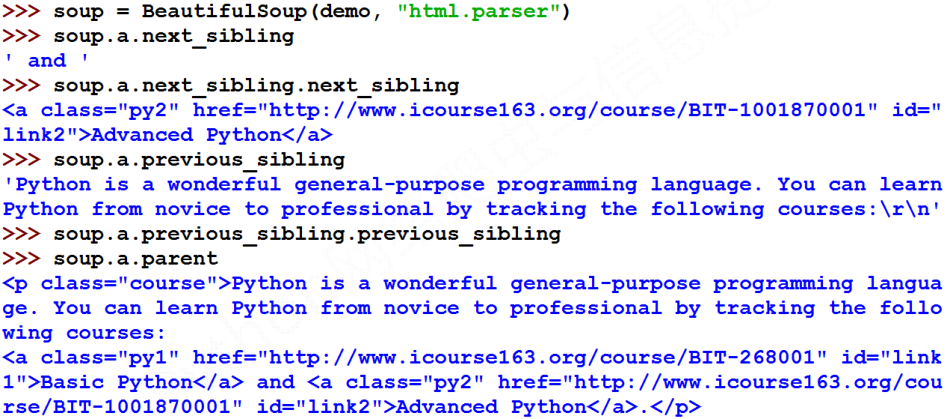
#遍历后续节点
for sibling in soup.a.next_sibling:
print(sibling) #遍历前续节点
for sibling in soup.a.previous_sibling:
print(sibling)
四、信息提取

- name : 对标签名称的检索字符串,返回标签name的所有内容,并生成列表,也以使用列表一次查找多个标签;如果标签名称为TRUE,将返回所有的标签信息;也可以使用正则对返回的标签信息做筛选



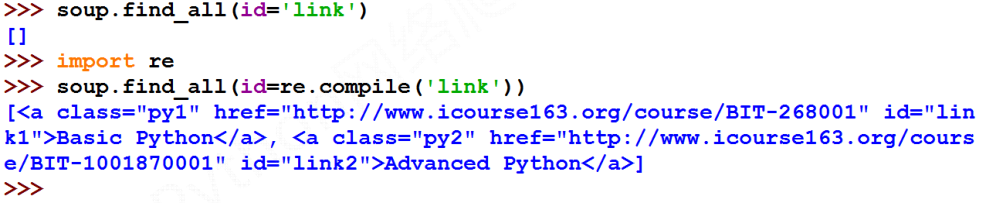
- attrs: 对标签属性值的检索字符串,可标注属性检索,返回列表,属性值必须精确,如果不提供精确的值得话,会返回空列表,可以使用正则表达式进行非精确的匹配
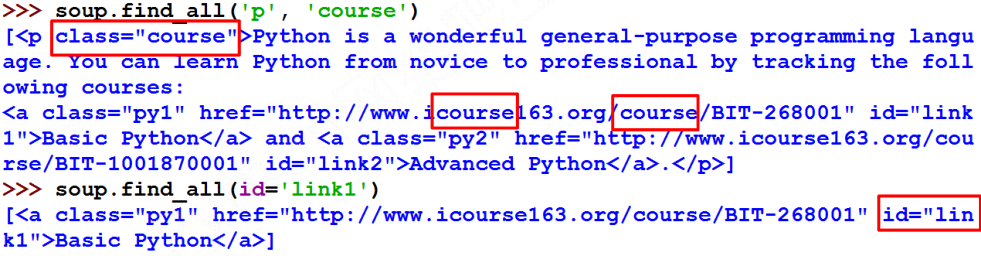
- recursive: 是否对子孙全部检索,默认True

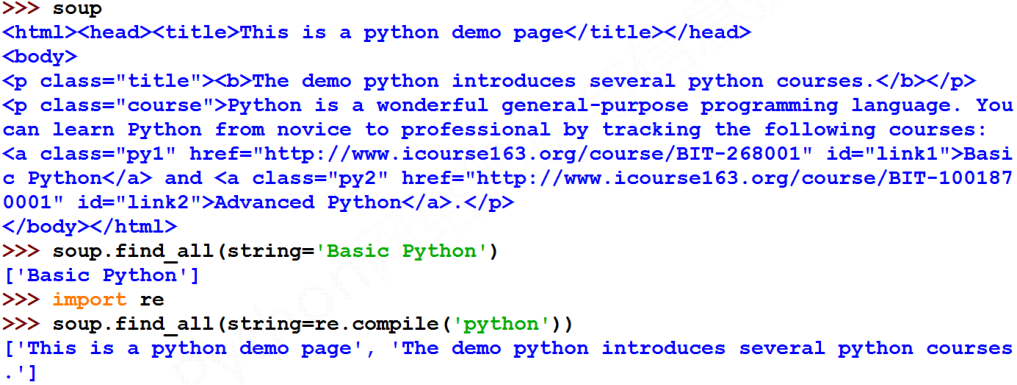
- string: <>…</>中字符串区域的检索字符串,需要加上string=‘’进行检索
简写方式:

扩展方法:

Python 爬虫-BeautifulSoup的更多相关文章
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- python爬虫---BeautifulSoup的用法
BeautifulSoup是一个灵活的网页解析库,不需要编写正则表达式即可提取有效信息. 推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前 ...
- Python爬虫--beautifulsoup 4 用法
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构, 每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSo ...
- python爬虫BeautifulSoup库class_
因为class是python的关键字,所以在写过滤的时候,应该是这样写: r = requests.get(web_url, headers=headers) # 向目标url地址发送get请求,返回 ...
- python爬虫 BeautifulSoup
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. Bea ...
- Python爬虫 | Beautifulsoup解析html页面
引入 大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据.因此,在聚焦爬虫中使用数据解析.所以,我们的数据爬取的流程为: 指定url 基于reque ...
- Python 爬虫 —— BeautifulSoup
from bs4 import BeautifulSoup % 首字母大写,显然这是一个类 1. BeautifulSoup 类 HTML 解析类(parser) r = requests.get(. ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
随机推荐
- Perl的debug小技巧
进入Perl的调试环境的命令: Perl -d perl_file 设置断点:b + perl代码中的行号. 执行到断点:c 表示continue until breakpoint. 执行下一条 ...
- C/S模型之命名管道
说明:利用管道实现服务端与客户端之间的交互.效果等同于利用socket. 命名管道(NamedPipe)是一种简单的进程间通信(IPC)机制,是服务器进程和一个或多个客户进程之间通信的单向或双向管道. ...
- Linux服务器配置---安装telnet
安装telnet telnet是标准的远程登录协议,历史悠久.但是telnet的对话数据没有加密,甚至用户名和密码都是明文显示,这样的服务风险极大.目前大多数系统多已经不会再安装这个服务了, ...
- Maven(一)如何用Eclipse创建一个Maven项目
1.什么是Maven Apache Maven 是一个项目管理和整合工具.基于工程对象模型(POM)的概念,通过一个中央信息管理模块,Maven 能够管理项目的构建.报告和文档. Maven工程结构和 ...
- P2880 [USACO07JAN]平衡的阵容Balanced Lineup
P2880 [USACO07JAN]平衡的阵容Balanced Lineup RMQ RMQ模板题 静态求区间最大/最小值 (开了O2还能卡到rank9) #include<iostream&g ...
- 微信小程序编写新闻阅读列表
微信小程序编写新闻阅读列表 不忘初心,方得始终:初心易得,始终难守. 本篇学习主要内容 Swiper 组件(轮播图) App.json 里的关于导航栏.标题的配置. Page 页面与应用程序的生命周期 ...
- JAVA学习调查问卷——20145101
1.你对自己的未来有什么规划?做了哪些准备? 我希望在未来不管自己是否从事机要工作,都要做一个有能力,对社会能有所贡献的人.所以在现阶段我应该努力学习基础知识,夯实基本功,具备成为合格机要人的素质. ...
- Cortex-M3基础
(一)寄存器 1 寄存器组 R0-R12: 通用寄存器 ------------------------------------------------------------------- ...
- 把json的字符串变为json对象
如{"tag":"sendcode","data":{"phone":"18880488738"}} ...
- Python3基础 函数 无参数无返回值 调用会输出hello world的函数
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...