Mask R-CNN论文理解
摘要:
- Mask RCNN可以看做是一个通用实例分割架构。
- Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务。
- Mask RCNN比Faster RCNN速度慢一些,达到了5fps。
- 可用于人的姿态估计等其他任务;
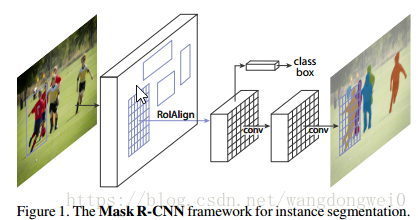
1、Introduction
- 实例分割不仅要正确的找到图像中的objects,还要对其精确的分割。所以Instance Segmentation可以看做object dection和semantic segmentation的结合。
- Mask RCNN是Faster RCNN的扩展,对于Faster RCNN的每个Proposal Box都要使用FCN进行语义分割,分割任务与定位、分类任务是同时进行的。
- 引入了RoI Align代替Faster RCNN中的RoI Pooling。因为RoI Pooling并不是按照像素一一对齐的(pixel-to-pixel alignment),也许这对bbox的影响不是很大,但对于mask的精度却有很大影响。使用RoI Align后mask的精度从10%显著提高到50%,第3节将会仔细说明。
- 引入语义分割分支,实现了mask和class预测的关系的解耦,mask分支只做语义分割,类型预测的任务交给另一个分支。这与原本的FCN网络是不同的,原始的FCN在预测mask时还用同时预测mask所属的种类。
- 没有使用什么花哨的方法,Mask RCNN就超过了当时所有的state-of-the-art模型。
- 使用8-GPU的服务器训练了两天。
2、Related Work
相比于FCIS,FCIS使用全卷机网络,同时预测物体classes、boxes、masks,速度更快,但是对于重叠物体的分割效果不好。
3、Mask R-CNN
MaskRCNN网络结构泛化图:
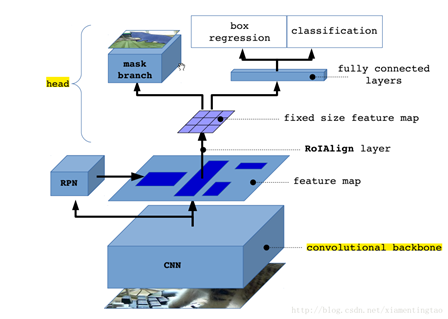
从上面可以知道,mask rcnn主要的贡献在于如下:
1. 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
2. ROIAlign解决Misalignment 的问题
3. Loss Function
细节描述
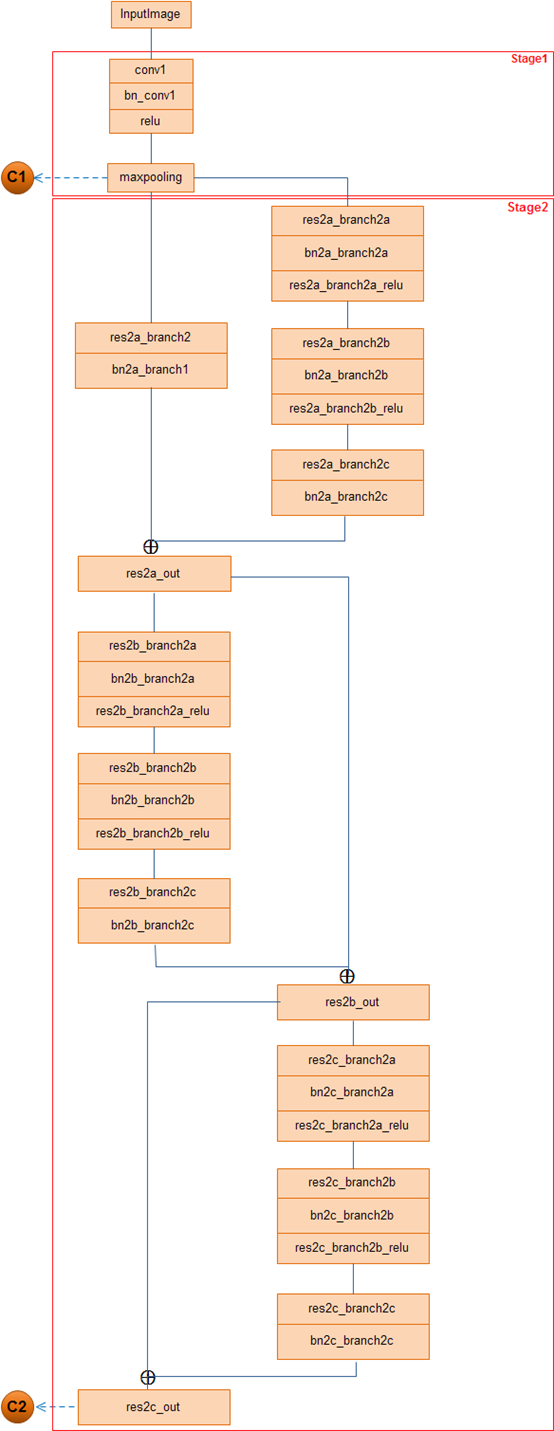
1. resnet +FPN
作者替换了在faster rcnn中使用的vgg网络,转而使用特征表达能力更强的残差网络。
另外为了挖掘多尺度信息,作者还使用了FPN网络。
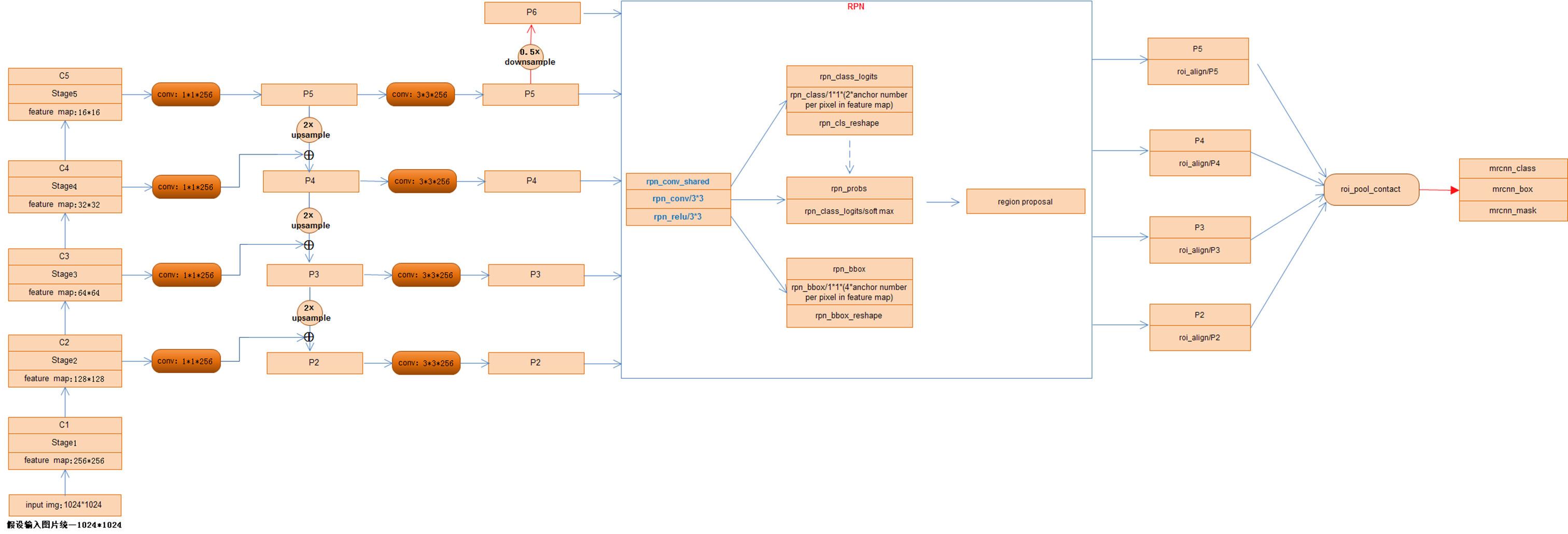
stage1和stage2层次结构图:

结合MaskRCNN网络结构图,注重点出以下几点:
1) 虽然事先将ResNet网络分为5个stage,但是,并没有利用其中的Stage1即P1的特征,官方的说法是因为P1对应的feature map比较大计算耗时所以弃用;相反,在Stage5即P5的基础上进行了下采样得到P6,故,利用了[P2 P3 P4 P5 P6]五个不同尺度的特征图输入到RPN网络,分别生成RoI.
2)[P2 P3 P4 P5 P6]五个不同尺度的特征图由RPN网络生成若干个anchor box,经过NMS非最大值抑制操作后保留将近共2000个RoI(2000为可更改参数),由于步长stride的不同,分开分别对[P2 P3 P4 P5]四个不同尺度的feature map对应的stride进行RoIAlign操作,将经过此操作产生的RoI进行Concat连接,随即网络分为三部分:全连接预测类别class、全连接预测矩形框box、全卷积预测像素分割mask
2. ROIAlign
对于roi pooling,经历了两个量化的过程:
第一个:从roi proposal到feature map的映射过程。方法是[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
第二个:从feature map划分成7*7的bin,每个bin使用max pooling。
这两种情况都会导致证输入和输出之间像素级别上不能一一对应(pixel-to-pixel alignment between network input and output)。
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
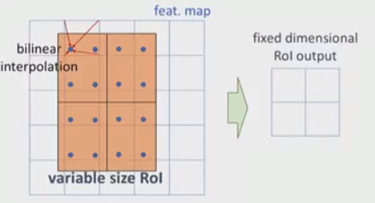
如上,roi映射到feature map后,不再进行四舍五入。然后将候选区域分割成k x k个单元, 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
3、损失函数:分类误差+检测误差+分割误差,即L=Lcls+Lbox+Lmask
Lcls、Lbox:利用全连接预测出每个RoI的所属类别及其矩形框坐标值,可以参看FasterRCNN网络中的介绍。
Lmask:
① mask分支采用FCN对每个RoI的分割输出维数为K*m*m(其中:m表示RoI Align特征图的大小),即K个类别的m*m的二值mask;保持m*m的空间布局,pixel-to-pixel操作需要保证RoI特征 映射到原图的对齐性,这也是使用RoIAlign解决对齐问题原因,减少像素级别对齐的误差。
K*m*m二值mask结构解释:最终的FCN输出一个K层的mask,每一层为一类,Log输出,用0.5作为阈值进行二值化,产生背景和前景的分割Mask
这样,Lmask 使得网络能够输出每一类的 mask,且不会有不同类别 mask 间的竞争. 分类网络分支预测 object 类别标签,以选择输出 mask,对每一个ROI,如果检测得到ROI属于哪一个分 类,就只使用哪一个分支的相对熵误差作为误差值进行计算。(举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask,即,每个class类别对应一个mask可以有效避免类间竞争(其他class不贡献Loss)
② 对每一个像素应用sigmoid,然后取RoI上所有像素的交叉熵的平均值作为Lmask。
每个 ROI 区域会生成一个 m*m*numclass 的特征层,特征层中的每个值为二进制掩码,为 0 或者为 1。根据当前 ROI 区域预测的分类,假设为 k,选择对应的第 k 个 m*m 的特征层,对每个像素点应用 sigmoid 函数,然后计算平均二值交叉损失熵,如下图所示:

上图中首先得到预测分类为 k 的 mask 特征,然后把原图中 bounding box 包围的 mask 区域映射成 m*m大小的 mask 区域特征,最后计算该 m*m 区域的平均二值交叉损失熵。
训练和预测细节:

参考:
https://blog.csdn.net/wangdongwei0/article/details/83110305
https://blog.csdn.net/jiongnima/article/details/79094159
https://blog.csdn.net/xiamentingtao/article/details/78598511
http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
https://www.cnblogs.com/wangyong/p/9305347.html
https://cloud.tencent.com/developer/news/189753
Mask R-CNN论文理解的更多相关文章
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- [论文理解] CornerNet: Detecting Objects as Paired Keypoints
[论文理解] CornerNet: Detecting Objects as Paired Keypoints 简介 首先这是一篇anchor free的文章,看了之后觉得方法挺好的,预测左上角和右下 ...
- R-FCN论文理解
一.R-FCN初探 1. R-FCN贡献 提出Position-sensitive score maps来解决目标检测的位置敏感性问题: 区域为基础的,全卷积网络的二阶段目标检测框架: 比Faster ...
- YOLO V2论文理解
概述 YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码, ...
- Fast R-CNN论文理解
论文地址:https://arxiv.org/pdf/1504.08083.pdf 翻译请移步:https://blog.csdn.net/ghw15221836342/article/details ...
- R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf 翻译请移步: https://www.cnblogs.com/xiaotongtt/p/6691103.html ht ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
随机推荐
- ATG精准科技-前端面试题
1.请写出以下结果 for(var i=0; i<10; i++){ setTimeout(function () { console.log(i) },10) } 结果:打印10次190解析: ...
- SV中的线程
SV中线程之间的通信可以让验证组件之间更好的传递transaction. SV对verilog建模方式的扩展:1) fork.....join 必须等到块内的所有线程都执行结束后,才能继续执行块后的语 ...
- innob and myisam存储引擎分析
首次啊对比一下两者的区别: MyISAM InnoDB 构成上的区别: 每个MyISAM在磁盘上存储成三个文件.第一个文件的名字以表的名字开始,扩展名指出文件类型. .frm文件存储表定义 ...
- 线段树(I tree)
Codeforces Round #254 (Div. 2)E题这题说的是给了一个一段连续的区间每个区间有一种颜色然后一个彩笔从L画到R每个区间的颜色都发生了 改变然后 在L和R这部分区间里所用的颜色 ...
- CAReplicatorLayer
CAReplicatorLayer CAReplicatorLayer的目的是为了高效生成许多相似的图层.它会绘制一个或多个图层的子图层,并在每个复制体上应用不同的变换.看上去演示能够更加解释这些,我 ...
- 新项目新工作空间新仓库新setting文件
maven项目涉及到仓库,本地jar包存放在本地仓库中,新项目新工作空间新仓库新setting文件,可以避免很多问题,不同项目工程的版本可能不一样,所涉及的jar包版本可能也不一样,不分开会有一些冲 ...
- kafka生产者和消费者
在使用kafka时,有时候为验证应用程序,需要手动读取消息或者手动生成消息.这个时候可以借助kafka-console-consumer.sh和kafka-console-producer.sh 这两 ...
- SNMP学习笔记之SNMP报文协议详解
0x00 简介 简单网络管理协议(SNMP)是TCP/IP协议簇的一个应用层协议.在1988年被制定,并被Internet体系结构委员会(IAB)采纳作为一个短期的网络管理解决方案:由于SNMP的简单 ...
- Python Web学习笔记之TCP/IP协议原理与介绍
HTTP.FTP.SMTP.Telnet等等协议,哦!那个HTTP协议啊就是访问网页用的那个协议啊然后那个······其实······你懂得,我们应该从实际来了解他,理解网络协议的作用与功能,然后再从 ...
- Java的各种加密算法
Java的各种加密算法 JAVA中为我们提供了丰富的加密技术,可以基本的分为单向加密和非对称加密 1.单向加密算法 单向加密算法主要用来验证数据传输的过程中,是否被篡改过. BASE64 严格地说,属 ...