Hadoop 基本架构
Hadoop 由两部分组成,分别是分布式文件系统和分布式计算框架 MapReduce。 其中分布式文件系统主要用于大规模数据的分布式存储,而 MapReduce 则构建在分布式文件系统之上,对存储在分布式文件系统中的数据进行分布式计算。本文主要涉及 MapReduce,但考虑到它的一些功能跟底层存储机制相关,因而会首先介绍分布式文件系统。
在 Hadoop 中, MapReduce 底层的分布式文件系统是独立模块, 用户可按照约定的一套接口实现自己的分布式文件系统, 然后经过简单的配置后, 存储在该文件系统上的数据便可以被 MapReduce 处理。 Hadoop 默认使用的分布式文件系统是 HDFS( Hadoop DistributedFile System, Hadoop 分布式文件系统),它与 MapReduce 框架紧密结合。 本节首先介绍分布式存储系统 HDFS 的基础架构, 然后介绍 MapReduce 计算框架。
HDFS 架构
HDFS 是一个具有高度容错性的分布式文件系统, 适合部署在廉价的机器上。 HDFS 能提供高吞吐量的数据访问, 非常适合大规模数据集上的应用。HDFS 的架构如图所示, 总体上采用了 master/slave 架构, 主要由以下几个组件组成 :Client、 NameNode、 Secondary NameNode 和 DataNode。 下面分别对这几个组件进行介绍:
(1) Client
Client(代表用 户) 通过与 NameNode 和 DataNode 交互访问 HDFS 中 的文件。 Client提供了一个类似 POSIX 的文件系统接口供用户调用。
(2) NameNode
整个Hadoop 集群中只有一个 NameNode。 它是整个系统的“ 总管”, 负责管理 HDFS的目录树和相关的文件元数据信息。 这些信息是以“ fsimage”( HDFS 元数据镜像文件)和“ editlog”(HDFS 文件改动日志)两个文件形式存放在本地磁盘,当 HDFS 重启时重新构造出来的。此外, NameNode 还负责监控各个 DataNode 的健康状态, 一旦发现某个DataNode 宕掉,则将该 DataNode 移出 HDFS 并重新备份其上面的数据。
(3) Secondary NameNode
Secondary NameNode 最重要的任务并不是为 NameNode 元数据进行热备份, 而是定期合并 fsimage 和 edits 日志, 并传输给 NameNode。 这里需要注意的是,为了减小 NameNode压力, NameNode 自己并不会合并fsimage 和 edits, 并将文件存储到磁盘上, 而是交由Secondary NameNode 完成。
(4) DataNode
一般而言, 每个 Slave 节点上安装一个 DataNode, 它负责实际的数据存储, 并将数据信息定期汇报给 NameNode。 DataNode 以固定大小的 block 为基本单位组织文件内容, 默认情况下 block 大小为 64MB。 当用户上传一个大的文件到 HDFS 上时, 该文件会被切分成若干个 block, 分别存储到不同的 DataNode ; 同时,为了保证数据可靠, 会将同一个block以流水线方式写到若干个(默认是 3,该参数可配置)不同的 DataNode 上。 这种文件切割后存储的过程是对用户透明的。
MapReduce 架构
同 HDFS 一样,Hadoop MapReduce 也采用了 Master/Slave(M/S)架构,具体如图所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker 和 Task。 下面分别对这几个组件进行介绍。
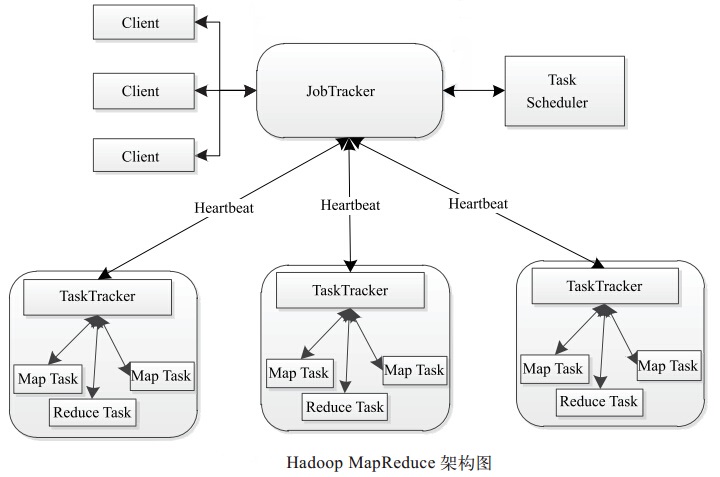
(1) Client
用户编写的 MapReduce 程序通过 Client 提交到 JobTracker 端; 同时, 用户可通过 Client 提供的一些接口查看作业运行状态。 在 Hadoop 内部用“作业”(Job) 表示 MapReduce 程序。 一个MapReduce 程序可对应若干个作业,而每个作业会被分解成若干个 Map/Reduce 任务(Task)。
(2) JobTracker
JobTracker 主要负责资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在 Hadoop 中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
(3) TaskTracker
TaskTracker 会周期性地通过 Heartbeat 将本节点上资源的使用情况和任务的运行进度汇报给 JobTracker, 同时接收 JobTracker 发送过来的命令并执行相应的操作(如启动新任务、 杀死任务等)。TaskTracker 使用“slot” 等量划分本节点上的资源量。“slot” 代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空闲 slot 分配给 Task 使用。 slot 分为 Map slot 和 Reduce slot 两种,分别供 MapTask 和 Reduce Task 使用。 TaskTracker 通过 slot 数目(可配置参数)限定 Task 的并发度。
(4) Task
Task 分为 Map Task 和 Reduce Task 两种, 均由 TaskTracker 启动。 HDFS 以固定大小的 block 为基本单位存储数据, 而对于 MapReduce 而言, 其处理单位是 split。split 与 block 的对应关系如图所示。 split 是一个逻辑概念, 它只包含一些元数据信息, 比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。 但需要注意的是,split 的多少决定了 Map Task 的数目 ,因为每个 split 会交由一个 Map Task 处理。
Map Task 执行过程如图所示。 由该图可知,Map Task 先将对应的 split 迭代解析成一个个 key/value 对,依次调用用户自定义的 map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个 partition,每个 partition 将被一个Reduce Task 处理。
Reduce Task 执行过程如图所示。该过程分为三个阶段①从远程节点上读取MapTask中间结果(称为“Shuffle 阶段”);②按照key对key/value对进行排序(称为“ Sort 阶段”);③依次读取<key, value list>,调用用户自定义的 reduce() 函数处理,并将最终结果存到 HDFS 上(称为“ Reduce 阶段”)。
Hadoop MapReduce 作业的生命周期
假设用户编写了一个 MapReduce 程序,并将其打包成 xxx.jar 文件,然后使用 以下命令提交作业:
$HADOOP_HOME/bin/hadoop jar xxx.jar \
-D mapred.job.name="xxx" \
-D mapred.map.tasks= \
-D mapred.reduce.tasks= \
-D input=/test/input \
-D output=/test/output
则该作业的运行过程如图所示:

这个过程分为以下 5 个步骤:
步骤 1:作业提交与初始化。 用户提交作业后, 首先由 JobClient 实例将作业相关信息, 比如将程序 jar 包、作业配置文件、 分片元信息文件等上传到分布式文件系统( 一般为HDFS)上,其中,分片元信息文件记录了每个输入分片的逻辑位置信息。 然后 JobClient通过 RPC 通知 JobTracker。 JobTracker 收到新作业提交请求后, 由 作业调度模块对作业进行初始化:为作业创建一个 JobInProgress 对象以跟踪作业运行状况, 而 JobInProgress 则会为每个Task 创建一个 TaskInProgress 对象以跟踪每个任务的运行状态, TaskInProgress 可能需要管理多个“ Task 运行尝试”( 称为“ Task Attempt”)。
步骤 2:任务调度与监控。前面提到,任务调度和监控的功能均由 JobTracker 完成。TaskTracker 周期性地通过 Heartbeat 向 JobTracker 汇报本节点的资源使用 情况, 一旦出 现空闲资源, JobTracker 会按照一定的策略选择一个合适的任务使用该空闲资源, 这由任务调度器完成。 任务调度器是一个可插拔的独立模块, 且为双层架构, 即首先选择作业, 然后从该作业中选择任务, 其中,选择任务时需要重点考虑数据本地性。 此外,JobTracker 跟踪作业的整个运行过程,并为作业的成功运行提供全方位的保障。 首先, 当 TaskTracker 或者Task 失败时, 转移计算任务 ; 其次, 当某个 Task 执行进度远落后于同一作业的其他 Task 时,为之启动一个相同 Task, 并选取计算快的 Task 结果作为最终结果。
步骤 3:任务运行环境准备。 运行环境准备包括 JVM 启动和资源隔 离, 均由TaskTracker 实现。 TaskTracker 为每个 Task 启动一个独立的 JVM 以避免不同 Task 在运行过程中相互影响 ; 同时,TaskTracker 使用了操作系统进程实现资源隔离以防止 Task 滥用资源。
步骤 4 :任务执行。 TaskTracker 为 Task 准备好运行环境后, 便会启动 Task。 在运行过程中, 每个 Task 的最新进度首先由 Task 通过 RPC 汇报给 TaskTracker, 再由 TaskTracker汇报给 JobTracker。
步骤 5 作业完成。 待所有 Task 执行完毕后, 整个作业执行成功。
PS:这篇文章出自《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》一书,并非原创,文章的目的为笔记使用,方便个人查看,高手勿喷!
参考资料
《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》
Hadoop 基本架构的更多相关文章
- Hadoop体系架构简介
今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- 【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型 1.x的版本架构模型介绍 架构图 HDFS分布式文件存储系统(典型的主从架构) NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用 ...
- Hadoop HDFS 架构设计
HDFS 简介 Hadoop Distributed File System,简称HDFS,是一个分布式文件系统. HDFS是高容错性的,可以部署在低成本的硬件之上,HDFS提供高吞吐量地对应用程序数 ...
- Hadoop系统架构
一.Hadoop系统架构图 Hadoop1.0与hadoop2.0架构对比图 YARN架构: ResourceManager –处理客户端请求 –启动/监控ApplicationMaster –监控N ...
- Hadoop 核心架构
Hadoop 由许多元素构成.其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件.HDFS(对于本文)的上一层是Ma ...
- Hadoop YARN架构设计要点
YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算框架中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算框 ...
- hadoop分布式系统架构详解
hadoop 简单来说就是用 java写的分布式 ,处理大数据的框架,主要思想是 “分组合并” 思想. 分组:比如 有一个大型数据,那么他就会将这个数据按照算法分成多份,每份存储在 从属主机上,并且在 ...
- hadoop体系架构
1.1 Hadoop 概念:hadoop是一个由Apache基金会所开发的分布式系统基础架构.是根据google发表的GFS(Google File System)论文产生过来的. ...
随机推荐
- mysql 事务回滚
begindeclare t_error integer default 0; //添加变量t_error并赋初始值为0declare continue handler for sqlexcepti ...
- 2017-2018-1 20179202《Linux内核原理与分析》第六周作业
一.系统调用实验(下): 1.编辑 menu 中的 text.c 文件,给MenuOS增加 rename 和 rename_asm 命令: make rootf 打开 menu 镜像,可以看到Menu ...
- Am335x U-boot LCD简易驱动
参考此文档说明,自行添加相关代码: https://pan.baidu.com/s/1i5gLE89 相关代码: https://pan.baidu.com/s/1qXL8Bne 在文档说明第四步1中 ...
- 使用 Eigen 3.3.3 进行矩阵运算
Eigen是一个能够进行线性代数运算的C++开源软件包,包含矩阵和矢量操作,Matlab中对矩阵的大多数操作都可以在Eigen中找到. 最近需要计算厄米特矩阵的逆,基于LLT分解和LDLT分解,自己写 ...
- React Native 系列(二)
前言 本系列是基于React Native版本号0.44.3写的,最初学习React Native的时候,完全没有接触过React和JS,本文的目的是为了给那些JS和React小白提供一个快速入门,让 ...
- codevs 1230【pb_ds】
题目链接[http://codevs.cn/problem/1230/] 题意:给出n个正整数,然后有m个询问,每个询问一个整数,询问该整数是否在n个正整数中出现过. 题解:很简单的一道题,可以选择用 ...
- 苹果无sim卡激活
韩梦飞沙 韩亚飞 313134555@qq.com yue31313 han_meng_fei_sha 苹果无sim卡激活 这是不行的... 必须有SIM 卡. 有可能卡贴坏了,更换卡贴.
- [BZOJ1032][P1840] 祖玛 记忆化搜索 动态规划
描述 Description 某天,小x在玩一个经典小游戏——zumo.zumo游戏的规则是,给你一段长度为n的连续的彩色珠子,珠子的颜色不一定完全相同,但是,如果连续相同颜色的珠子大 ...
- Linux知识(6)----VIM
vi的第一版是由Bill Joy在1978年写成的,当时他是UC Berkeley的学生.后来他共同创建了神奇的Sun公司.vi来源于visual一词,目标是在终端上可视化地模拟文本的编辑,是的更人性 ...
- Colorful Lecture Note
Colorful Lecture Note 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 Little Hi is writing an algorithm lectu ...