python开发_pickle
pickle模块使用的数据格式是python专用的,并且不同版本不向后兼容,同时也不能被其他语言说识别。要和其他语言交互,可以使用内置的json包使用pickle模块你可以把Python对象直接保存到文件,而不需要把他们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里。 pickle模块会创建一个python语言专用的二进制格式,你基本上不用考虑任何文件细节,它会帮你干净利落地完成读写独享操作,唯一需要的只是一个合法的文件句柄。
pickle模块中的两个主要函数是dump()和load()。dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
cPickle是pickle得一个更快得C语言编译版本。
pickle和cPickle相当于java的序列化和反序列化操作
以上来源:http://www.2cto.com/kf/201009/74973.html
下面是python的API中的Example:
# Simple example presenting how persistent ID can be used to pickle
# external objects by reference. import pickle
import sqlite3
from collections import namedtuple # Simple class representing a record in our database.
MemoRecord = namedtuple("MemoRecord", "key, task") class DBPickler(pickle.Pickler): def persistent_id(self, obj):
# Instead of pickling MemoRecord as a regular class instance, we emit a
# persistent ID.
if isinstance(obj, MemoRecord):
# Here, our persistent ID is simply a tuple, containing a tag and a
# key, which refers to a specific record in the database.
return ("MemoRecord", obj.key)
else:
# If obj does not have a persistent ID, return None. This means obj
# needs to be pickled as usual.
return None class DBUnpickler(pickle.Unpickler): def __init__(self, file, connection):
super().__init__(file)
self.connection = connection def persistent_load(self, pid):
# This method is invoked whenever a persistent ID is encountered.
# Here, pid is the tuple returned by DBPickler.
cursor = self.connection.cursor()
type_tag, key_id = pid
if type_tag == "MemoRecord":
# Fetch the referenced record from the database and return it.
cursor.execute("SELECT * FROM memos WHERE key=?", (str(key_id),))
key, task = cursor.fetchone()
return MemoRecord(key, task)
else:
# Always raises an error if you cannot return the correct object.
# Otherwise, the unpickler will think None is the object referenced
# by the persistent ID.
raise pickle.UnpicklingError("unsupported persistent object") def main():
import io
import pprint # Initialize and populate our database.
conn = sqlite3.connect(":memory:")
cursor = conn.cursor()
cursor.execute("CREATE TABLE memos(key INTEGER PRIMARY KEY, task TEXT)")
tasks = (
'give food to fish',
'prepare group meeting',
'fight with a zebra',
)
for task in tasks:
cursor.execute("INSERT INTO memos VALUES(NULL, ?)", (task,)) # Fetch the records to be pickled.
cursor.execute("SELECT * FROM memos")
memos = [MemoRecord(key, task) for key, task in cursor]
# Save the records using our custom DBPickler.
file = io.BytesIO()
DBPickler(file).dump(memos) print("Pickled records:")
pprint.pprint(memos) # Update a record, just for good measure.
cursor.execute("UPDATE memos SET task='learn italian' WHERE key=1") # Load the records from the pickle data stream.
file.seek(0)
memos = DBUnpickler(file, conn).load() print("Unpickled records:")
pprint.pprint(memos) if __name__ == '__main__':
main()
运行效果:
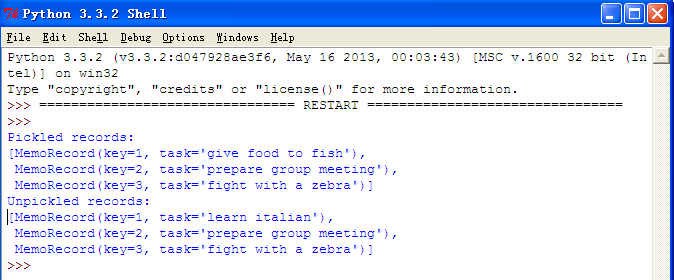
python开发_pickle的更多相关文章
- python开发环境搭建
虽然网上有很多python开发环境搭建的文章,不过重复造轮子还是要的,记录一下过程,方便自己以后配置,也方便正在学习中的同事配置他们的环境. 1.准备好安装包 1)上python官网下载python运 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- Python开发工具PyCharm个性化设置(图解)
Python开发工具PyCharm个性化设置,包括设置默认PyCharm解析器.设置缩进符为制表符.设置IDE皮肤主题等,大家参考使用吧. JetBrains PyCharm Pro 4.5.3 中文 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- Eclipse中Python开发环境搭建
Eclipse中Python开发环境搭建 目 录 1.背景介绍 2.Python安装 3.插件PyDev安装 4.测试Demo演示 一.背景介绍 Eclipse是一款基于Java的可扩展开发平台. ...
- Python开发:环境搭建(python3、PyCharm)
Python开发:环境搭建(python3.PyCharm) python3版本安装 PyCharm使用(完全图解(最新经典))
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
随机推荐
- WordPress的SEO插件——WordPress SEO by yoast安装及使用
插件:WordPress SEO by yoast 使用方法: 做好网站SEO一直是站长们的愿望,说简单也简单,但是说难也难,因为需要注意的地方太多,一个不小心被百度K了你都不知道怎么回事.这里和大家 ...
- Python3 多进程
多进程(multiprocessing)的用法和多线程(threading)类似,里面的函数也一样,start()为启动函数,join() 等待该进程运行结束,每一个进程也是由它的父进程产生 1.简单 ...
- springMVC中ajax的实现
function addDebtResult(){ var repayIds=$("#repayIds").val(); var lateFeeDay=$("#repay ...
- centos7安装lamp
一.准备工作 1. 下载并安装CentOS7.2,配置好网络环境,确保centos能上网,可以获取到yum源. centos7.2的网络配置: vim /etc/sysconfig/network ...
- Django自定义UserModel并实现认证和登录
自定义UserModel 环境:django 1.9.11+python 2.7 from django.contrib.auth.models import AbstractUser class U ...
- Codeforces 822D My pretty girl Noora(最小素因子的性质)
题目大意:一场选美比赛有N个人,可以分成N/x,每组x人.每组的比较次数为x(x-1)/2,f[N]为最后决出冠军所需的比较次数,可以通过改变x的值使f[N]改变.题目给出t,l,r(1 ≤ t &l ...
- 数据分析python应用到的ggplot(二)
还是优达学院的第七课 数据:https://s3.amazonaws.com/content.udacity-data.com/courses/ud359/hr_by_team_year_sf_la. ...
- js中的for循环
预定义: var arr=[22,33,12,34];//数组(特殊的对象) var obj={ //对象 name:"Jack", age:"99", sex ...
- Mybatis基础及入门案例
这几天正在对SSM框架的知识进行一个回顾加深,有很多东西学的囫囵吞枣,所以利用一些时间进一步的学习.首先大概了解一下mybatis的使用,再通过一个案例来学习它. 什么是MyBatis Mybatis ...
- kubeadm高可用master节点部署文档
kubeadm的标准部署里,etcd和master都是单节点的. 但上生产,至少得高可用. etcd的高可用,用kubeadm微微扩散一下就可以. 但master却官方没有提及. 于是搜索了几篇文档, ...