k-近邻算法(KNN)
最近邻算法可以说是最简单的分类算法,其思想是将被预测的项归类为和它最相近的项相同的类。我们通过简单的计算比较即将被预测的项与已有训练集中各项的距离(差距),选择其中差距最小的一项,该项的类别即为我们即将预测的类别。
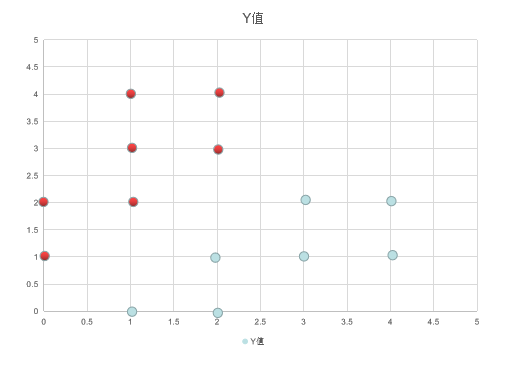
下表为我们即将使用的数据集,所有的点分为红色和蓝色两种,我们随机给出一个坐标位置,然后预测其应该属于的类别。
代码如下:
import math
"""
此python程序用来实现最近邻算法
""" def dot_distance(dot1, dot2):
# 计算两点之间的距离
return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def cal_nearest_neighbor(example, goal):
""" :param example: 已有的样例集合
:param goal: 待预测的目标
:return: 距目标最近样例
""" dis, aim = dot_distance(example[0], goal), example[0]
example_len = len(example)
for i in range(1, example_len):
dis1, aim1 = dot_distance(example[i],goal), example[i]
if dis > dis1:
dis, aim = dis1, aim1
return aim
最近邻算法只依据一个数据点来判断其类别,显然如果是一个噪音与即将预测的项目距离很近的话,这就有很大的可能会预测错误。然后就有了最近邻算法的改进--k-近邻算法。
k-近邻算法的思想与最近邻算法类似,不过,它是选择了k个与即将预测的项目最近的训练项目,然后让k个项目投票,以此判断其应该属于的类别。代码如下:
import math def dot_distance(dot1, dot2):
# 计算两点之间的距离
return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def predict(example, goal, k):
""" :param example: 训练集
:param goal: 待测点
:param k: 投票的个数,一般为奇数
:return: 最近的k个点
"""
example_len = len(example)
if example_len < k:
k = example_len
k_nearest_dots = []
for i in range(k):
k_nearest_dots.append((example[i], dot_distance(example[i], goal)))
k_nearest_dots.sort(key=lambda item: item[1])
for i in range(k, example_len):
dis = dot_distance(example[i], goal)
if dis < k_nearest_dots[k-1][1]:
k_nearest_dots.pop()
k_nearest_dots.append((example[i],dis))
k_nearest_dots.sort(key=lambda item: item[1]) return k_nearest_dots
k-近邻算法存在的问题是,当某一类的数据较大时,会对该类别的预测造成过大的影响。如一个小圆圈内都是一个类别,但是数据很少,然后一个同心圆中数据很多,这时我们预测一个在小圆圈内的数据,我们倾向于它应该是属于小圆圈同一个类别的,但是因为数据不足的原因,其可能会被预测为大圆圈类别。
k-近邻算法的改进是,为不同的距离确定不同的权重。即为更小的距离,确定一个较大的权重。
以上两部分测试代码如下:
import csv
from NN import nearest_neighbor
from NN import k_nearest_neighbor class Data:
def __init__(self):
self.x = 0
self.y = 0
self.type = None with open("test\\NN\\data.csv","r") as csv_file:
reader = csv.reader(csv_file)
rows = [row for row in reader]
example = []
for item in rows:
data = Data()
data.x = int(item[0])
data.y = int(item[1])
data.type = item[2]
example.append(data)
goal = Data()
goal.x = 0
goal.y = 3
result = nearest_neighbor.cal_nearest_neighbor(example,goal)
print(goal.x, " ", goal.y, " :", result.type) goal.x = 3
goal.y = 0
result = nearest_neighbor.cal_nearest_neighbor(example,goal)
print(goal.x, " ", goal.y, " :", result.type) k_num = 3
preset = k_nearest_neighbor.predict(example,goal,k_num)
red = 0
blue = 0
for item in preset:
if item[0].type == "red":
red += 1
elif item[0].type == "blue":
blue += 1
if red > blue:
print("predict ", goal.x, " ", goal.y, " is red")
else:
print("predict ", goal.x, " ", goal.y, " is blue")
训练集数据,保存为data.csv
0,1,red
0,2,red
1,2,red
1,3,red
1,4,red
2,3,red
2,4,red
1,0,blue
2,0,blue
2,1,blue
3,1,blue
3,2,blue
4,1,blue
4,2,blue
k-近邻算法(KNN)的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 07.k近邻算法kNN
1.将数据分为测试数据和预测数据 2.数据分为data和target,data是矩阵,target是向量 3.将每条data(向量)绘制在坐标系中,就得到了一系列的点 4.根据每条data的targe ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
随机推荐
- Android-HttpClient-Get与Post请求登录功能
HttpClient 是org.apache.http.* 包中的: 第一种方式使用httpclient-*.jar (需要在网上去下载httpclient-*.jar包) 把httpclient-4 ...
- 通过JS拦截 pushState 和 replaceState 事件
history.pushState 和 history.replaceState 可以在不刷新当前页面的情况下更改URL,但是这样就无法获取通过AJAX得到的新页面的内容了.虽然各种HTML5文档说 ...
- windform 重绘Treeview "+-"号图标
模仿wind系统界面,重绘Treeview + - 号图标 一,首先需要图片 ,用于替换原有的 +-号 二.新建Tree扩展类 TreeViewEx继承TreeView using System; u ...
- 使用xftp连接到ftp服务器即常见问题的解决
使用xftp连接到ftp服务器 新建连接 配置连接 点击确定,连接到ftp 常见问题 中文乱码问题 解决: 点击连接设置按钮 修改编码方式 最后确定保存!刷新一下,就不在乱码了;
- 预防和避免死锁的方法及银行家算法的java简单实现
预防死锁 (1) 摒弃"请求和保持"条件 基本思想:规定所有进程在开始运行之前,要么获得所需的所有资源,要么一个都不分配给它,直到所需资源全部满足才一次性分配给它. 优点:简单.易 ...
- AjaxResult
package com.sprucetec.tms.utils; /** * AjaxReturn * * @author Yinqiang Du * @date 2016/7/12 */import ...
- XSS钓鱼某网约车后台一探究竟,乘客隐私暴露引发思考
i春秋作家:onls辜釉 最近的某顺风车命案,把网约车平台推上了风口浪尖,也将隐私信息管理.审查的讨论面进一步扩大.这让我不禁联想起自己今年春节的遭遇,当时公司放假准备回家过年,我妈给我推荐了一个在我 ...
- mysql存储过程双重循环示例
BEGIN ); DECLARE done INT DEFAULT FALSE; DECLARE cursor_rule CURSOR FOR SELECT s.id FROM d_menu_type ...
- 一文搞懂Java环境,轻松实现Hello World!
在上篇文章中,我们介绍了Java自学大概的路线.然而纸上得来终觉浅,今天我们教大家写第一个java demo.(ps:什么是demo?Demo的中文含意为“示范",Demo源码可以理解为某种 ...
- 弹出AlertDialog的时候报You need to use a Theme.AppCompat theme (or descendant) with this activity错误
今天遇到一个bug,用百度地图的时候,我对上面的标注设置了点击监听,设置的相应的反应是弹出一个AlertDialog 记录一解决bug的历程 但是Dialog却没有弹出来,一看AS下面,报了这错,起初 ...