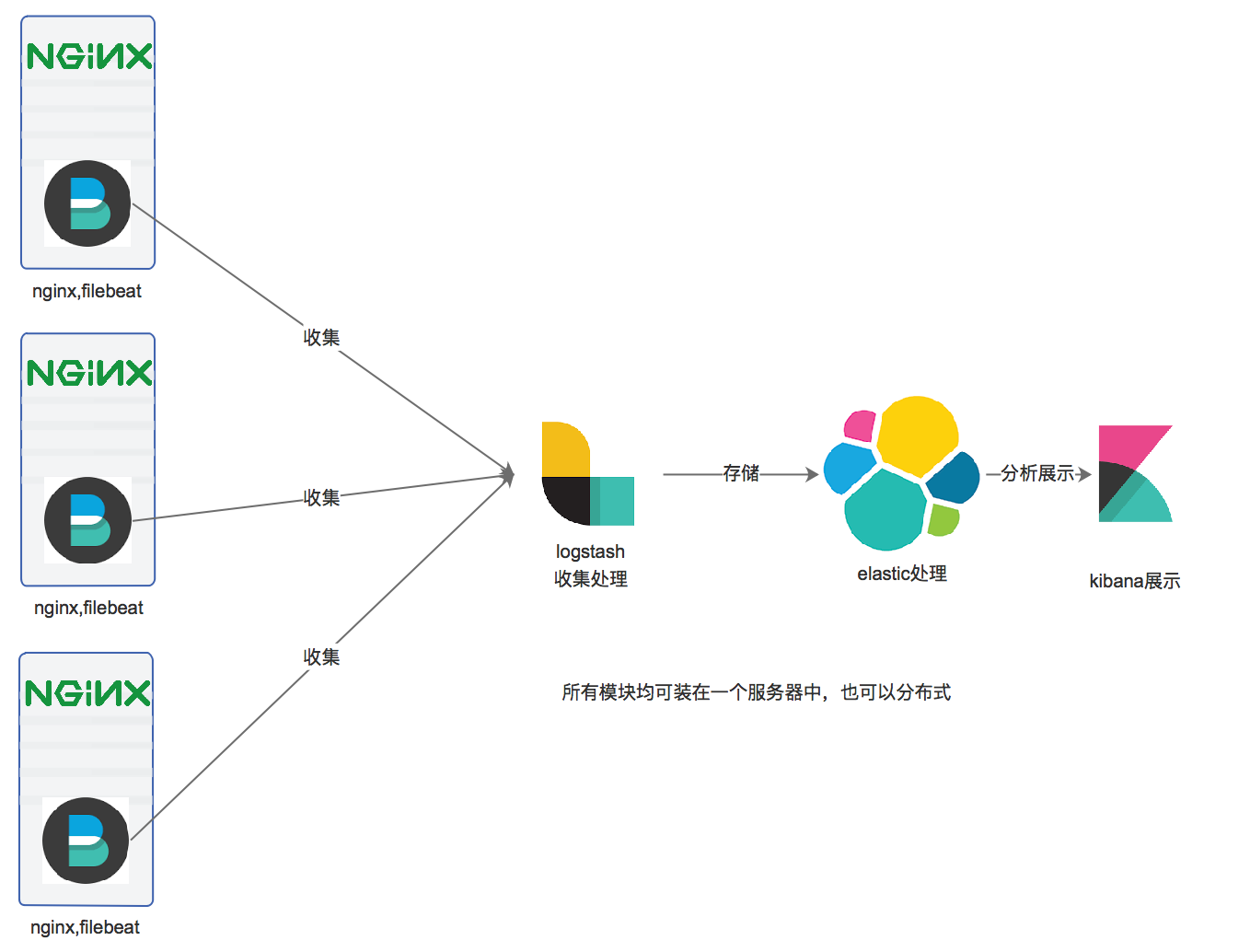
ELASTIC 5.2部署并收集nginx日志

#禁用swap内存交换
##若开启此选项,你需要修改/usr/lib/systemd/system/elasticsearch.service文件,并设置LimitMEMLOCK=infinity,
##修改/etc/sysconfig/elasticsearch文件,设置MAX_LOCKED_MEMORY=unlimited,最后执行systemctl daemon-reloa & systemctl restart elasticsearch
#bootstrap.memory_lock: true
谢土豪
如果有帮到你的话,请赞赏我吧!

ELASTIC 5.2部署并收集nginx日志的更多相关文章
- Docker 部署 ELK 收集 Nginx 日志
一.简介 1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部分组件组成: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引 ...
- ELK Stack (2) —— ELK + Redis收集Nginx日志
ELK Stack (2) -- ELK + Redis收集Nginx日志 摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 ...
- ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
常规的日志收集方案中Client端都需要额外安装一个Agent来收集日志,例如logstash.filebeat等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实 ...
- ELK 二进制安装并收集nginx日志
对于日志来说,最常见的需求就是收集.存储.查询.展示,开源社区正好有相对应的开源项目:logstash(收集).elasticsearch(存储+搜索).kibana(展示),我们将这三个组合起来的技 ...
- 使用Docker快速部署ELK分析Nginx日志实践
原文:使用Docker快速部署ELK分析Nginx日志实践 一.背景 笔者所在项目组的项目由多个子项目所组成,每一个子项目都存在一定的日志,有时候想排查一些问题,需要到各个地方去查看,极为不方便,此前 ...
- ELK filter过滤器来收集Nginx日志
前面已经有ELK-Redis的安装,此处只讲在不改变日志格式的情况下收集Nginx日志. 1.Nginx端的日志格式设置如下: log_format access '$remote_addr - $r ...
- 安装logstash5.4.1,并使用grok表达式收集nginx日志
关于收集日志的方式,最简单性能最好的应该是修改nginx的日志存储格式为json,然后直接采集就可以了. 但是实际上会有一个问题,就是如果你之前有很多旧的日志需要全部导入elk上查看,这时就有两个问题 ...
- 使用Docker快速部署ELK分析Nginx日志实践(二)
Kibana汉化使用中文界面实践 一.背景 笔者在上一篇文章使用Docker快速部署ELK分析Nginx日志实践当中有提到如何快速搭建ELK分析Nginx日志,但是这只是第一步,后面还有很多仪表盘需要 ...
- 第七章·Logstash深入-收集NGINX日志
1.NGINX安装配置 源码安装nginx 因为资源问题,我们先将nginx安装在Logstash所在机器 #安装nginx依赖包 [root@elkstack03 ~]# yum install - ...
随机推荐
- bzoj千题计划104:bzoj1013: [JSOI2008]球形空间产生器sphere
http://www.lydsy.com/JudgeOnline/problem.php?id=1013 设球心(x1,x2,x3……) 已知点的坐标为t[i][j] 那么 对于每个i满足 Σ (t[ ...
- elementUI 通用确认框
Util.vue <script> import VueResource from 'vue-resource' function confirm(_this, operate, fun) ...
- centos 7 两台机器搭建三主三从 redis 集群
参考自:https://linux.cn/article-6719-1.htmlhttp://blog.csdn.net/xu470438000/article/details/42971091 ## ...
- 基础知识点 关于 prototype __proto__
基础知识点 关于 prototype __proto__ 供js新手参考 JavaScript 的一些基础知识点: 在 JavaScript 中,所有对象 o 都拥有一个隐藏的原型对象(在 Fire ...
- [转]CMake cache
CMakeCache.txt 可以将其想象成一个配置文件(在Unix环境下,我们可以认为它等价于传递给configure的参数). CMakeLists.txt 中通过 set(... CACHE . ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- Python实现 -- 冒泡排序、选择排序、插入排序
冒泡排序 冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法. 冒泡排序的原理: 比较两个相邻的元素,如果第一个比第二个大,就交换他们 对每一对相邻的元素做同样的工作,从开始第 ...
- C# 特性(Attribute)详细介绍
1.什么是Atrribute 首先,我们肯定Attribute是一个类,下面是msdn文档对它的描述:公共语言运行时允许你添加类似关键字的描述声明,叫做attributes, 它对程序中的元素进行标注 ...
- SUSE Enterprise Server 12 SP3 64 设置防火墙开放8080端口,出现Unsafe permissions for file /etc/sysconfig/SuSEfirewall2 to be sourced
SUSE Enterprise Server 12 SP3 64 设置防火墙开放8080端口时出现 Unsafe permissions for file /etc/sysconfig/SuSEf ...
- spring各个版本源码
各版本源码下载地址 http://maven.springframework.org/release/org/springframework/spring/