关于java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.的问题
报错如下:
300 [main] DEBUG org.apache.hadoop.util.Shell - Failed to detect a valid hadoop home directory
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set
解决办法一:
根据 http://blog.csdn.net/baidu_19473529/article/details/54693523 配置hadoop_home变量
下载winutils地址https://github.com/srccodes/hadoop-common-2.2.0-bin下载解压

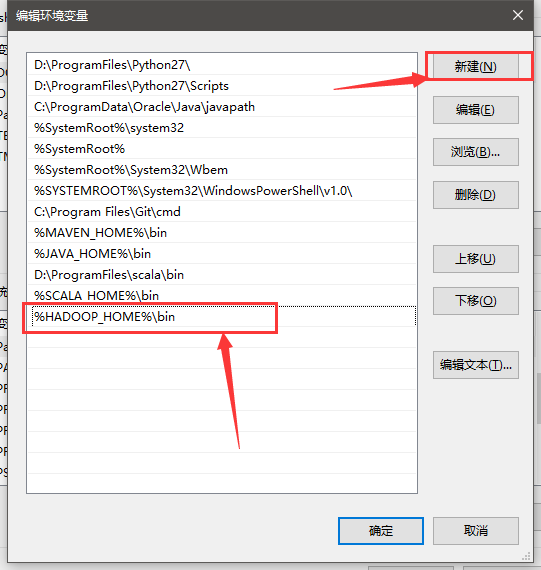
重新打开Eclipse,运行程序,可以解决内网的Hadoop连接问题。(亲测试通过)
解决办法二:
在java程序中加入
System.setProperty("hadoop.home.dir", "/usr/local/hadoop-2.6.0");
依然报错(未亲测试)
解决办法三:(不是同一问题?)
根据该提示:
依然报错
--------------------------------5.19.早晨------------------------------------------
今天早上再次执行该程序,将上传到HDFS部分的代码给注释掉后发现日志报错信息如下:
132 [main] DEBUG org.apache.hadoop.util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
134 [main] DEBUG org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
1)check Hadoop library:
root@Ubuntu-1:/usr/local/hadoop-2.6.0/lib/native# file libhadoop.so.1.0.

It's 64-bite library
2)Try adding the HADOOP_OPTS environment variable:
root@Ubuntu-1:~# vi /etc/profile //environment variable
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native/"
It doesn't work, and reports the same error.
3)Try adding the HADOOP_OPTS and HADOOP_COMMON_LIB_NATIVE_DIR environment variable:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/"
It still doesn't work, and reports the same error.
4)Adding the Hadoop library into LD_LIBRARY_PATH
root@Ubuntu-1:~# vi .bashrc
export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native/:$LD_LIBRARY_PATH
It doesn't work, and reports the same error.
5)append word native to HADOOP_OPTS like this
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
It doesn't work, and reports the same error.
-----------------------------------5.20早晨-------------------------
win下依旧无法使用java代码上传文件到HDFS
----------------------------------5.24------------
copy了一份hadoop-2.6.0文件到本机,更改bin目录和path ,显示无效的path,遂更改回去
---------------------2017.5.26-------------------
今天早上开机 试了一下 发现它已经好了 其实上述的设置已经可以解决大部分遇到这类问题的人群

关于java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.的问题的更多相关文章
- windows 中使用hbase 异常:java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
平时一般是在windows环境下进行开发,在windows 环境下操作hbase可能会出现异常(java.io.IOException: Could not locate executable nul ...
- 排查Hive报错:org.apache.hadoop.hive.serde2.SerDeException: java.io.IOException: Start of Array expected
CREATE TABLE json_nested_test ( count string, usage string, pkg map<string,string>, languages ...
- java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries
在已经搭建好的集群环境Centos6.6+Hadoop2.7+Hbase0.98+Spark1.3.1下,在Win7系统Intellij开发工具中调试Spark读取Hbase.运行直接报错: ? 1 ...
- hive运行query语句时提示错误:org.apache.hadoop.ipc.RemoteException: java.io.IOException: java.io.IOException:
hive> select product_id, track_time from trackinfo limit 5; Total MapReduce jobs = 1 Launching Jo ...
- Spark- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
运行 mport org.apache.log4j.{Level, Logger} import org.apache.spark.rdd.RDD import org.apache.spark.{S ...
- spark开发常见问题之一:java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
最近在学习研究pyspark机器学习算法,执行代码出现以下异常: 19/06/29 10:08:26 ERROR Shell: Failed to locate the winutils binary ...
- idea 提示:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException解决方法
Windows系统中的IDEA链接Linux里面的Hadoop的api时出现的问题 提示:ERROR util.Shell: Failed to locate the winutils binary ...
- org.apache.hadoop.ipc.RemoteException(java.io.IOException)
昨晚突然之间mr跑步起来了 jps查看 进程都在的,但是在reduce任务跑了85%的时候会抛异常 异常情况如下: 2016-09-21 21:32:28,538 INFO [org.apache.h ...
- 运行基准测试hadoop集群中的问题:org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /benchmarks/TestDFSIO/io_data/test_
在master(即:host2)中执行 hadoop jar hadoop-test-1.1.2.jar DFSCIOTest -write -nrFiles 12 -fileSize 10240 - ...
随机推荐
- 吴裕雄 python 机器学习-DMT(1)
import numpy as np import operator as op from math import log def createDataSet(): dataSet = [[1, 1, ...
- you-get
1.打开cmd,输入命令并执行 pip3 install you-get 2.输入命令,检测 You-Get 是否安装成功 you-get 3.开始下载吧 you-get [视频地址]you-get ...
- Canvas 绘画
一.Canvas 应用场景 1.游戏 2.图表 3.动画 4.codepen.io (HTML5 动效) 最早 二.Canvas 发展历史 1.最早在apple的safari 1.3中引入 2.ie ...
- elasticsearch 测试
https://www.yiibai.com/elasticsearch/elasticsearch-getting-start.html # curl -XPUT "http://loca ...
- C++字符串和向量
陷阱:C字符串使用=和== char a_string[10]; a_string="Hello" 非法 strcpy(a_string,"Hello"); ...
- 大型运输行业实战_day13_1_定时任务spring-quartz
1.jar包 拷贝quartz-2.2.3.jar包到项目 2.编写定时任务类TicketQuart.java package com.day02.sation.task; import com.da ...
- 【C++】正则表达式引擎学习心得
最近参照一些资料实现了一个非常简易的正则表达式引擎,支持基本的正则语法 | + * ()等. 实现思路是最基本的:正则式->AST->NFA->DFA. 以下是具体步骤: 一. 正则 ...
- 使用html中的<input>标签上传多个文件(转)
如何使用html上传多个文件呢?我搜索中文怎么也找不到合适的,都是用js动态添加input,然后提交,不能满足我想要的——打开选择文件的窗口后可以一次性选择多个文件. 然后我尝试搜索英文"h ...
- PUDN用户名与密码
Pudn 用户名与密码 boumang8171 que2538 温馨提示:1. 95%的用户第一次登录不成功,都是因为在复制粘贴帐号和密码时,把空格也复制粘贴上了.2. 如果连续3次帐号或密 ...
- leetcode 中等题(2)
50. Pow(x, n) (中等) double myPow(double x, int n) { ; unsigned long long p; ) { p = -n; x = / x; } el ...