spark深入:配置文件与日志
一、第一部分
1、spark2.1与hadoop2.7.3集成,spark on yarn模式下,需要对hadoop的配置文件yarn-site.xml增加内容,如下:
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2、spark的conf/spark-defaults.conf配置
spark.yarn.historyServer.address=node2:18080
spark.history.ui.port=18080
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///tmp/spark/events
spark.history.fs.logDirectory=hdfs:///tmp/spark/events
如果你是运行在yarn之上的话,就要告诉yarn,你spark的地址,当我在yarn上点击一个任务,进去看history的时候,他会链接到18080里面,如果你配的是node1:18080,那么你就要在node1上启动spark的history server(见后面注①)
最下面两个配置是运行spark程序的时候配置的,一旦你运行spark,就会将日志等发送到那两个目录,有了这两个目录,spark的historyserver就可以读取spark的运行状态信息日志等读取并展示
18080是spark的history server,会显示出你最近spark跑过的一些程序,点击execution后,点击最右边的日志(如果有的话),会重定向到19888(见后面注②),这个是mr的jobserver的地址(启动命令:mr-jobhistory-daemon.sh start historyserver)
spark.yarn.historyServer.address和spark.history.ui.port如果缺少其中一个,日志就看不到
综上,1和2两个配置齐全,才可以查看spark的stdout和stderr日志
二、第二部分

实际上,在spark程序运行的时候,会起一个driver程序和多个executor程序,他们都是跑在nodemanager之上的,在启动程序的时候,如果我们在默认的配置项里面,配置了参数spark.eventLog.enabled=true,spark.eventLog.dir=地址,那么driver上就会把所有的事件全部给记录下来,事件包括,executor的启动,executor执行的task等发送给driver
每当写日志的时候,都有一个写日志的组件将日志写进那个目录里面,这个目录下面每一个应用程序都会存在一个文件,然后将会由spark的history server(也就是配置在spark-default.conf里面),这个server会在18080启动一个进程,去扫描日志目录,并解析每一个文件,进行还原,就得到了整个应用的状态
在hadoop-2.7.3/etc/hadoop/mapred-site.xml配置文件中
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/user/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/user/history/done_intermediate</value>
</property>
stdlog和err是每一个nodemanager上的每一个executor都会产生的,如果当程序完成后,在这个节点上,跟这个应用相关的所有信息全部会被清除掉,包括这些日志,这样的话如果我们不把这个日志收集起来,那么后面在历史信息(18080 executord模块的stderr和out)里面就看不到这些日志
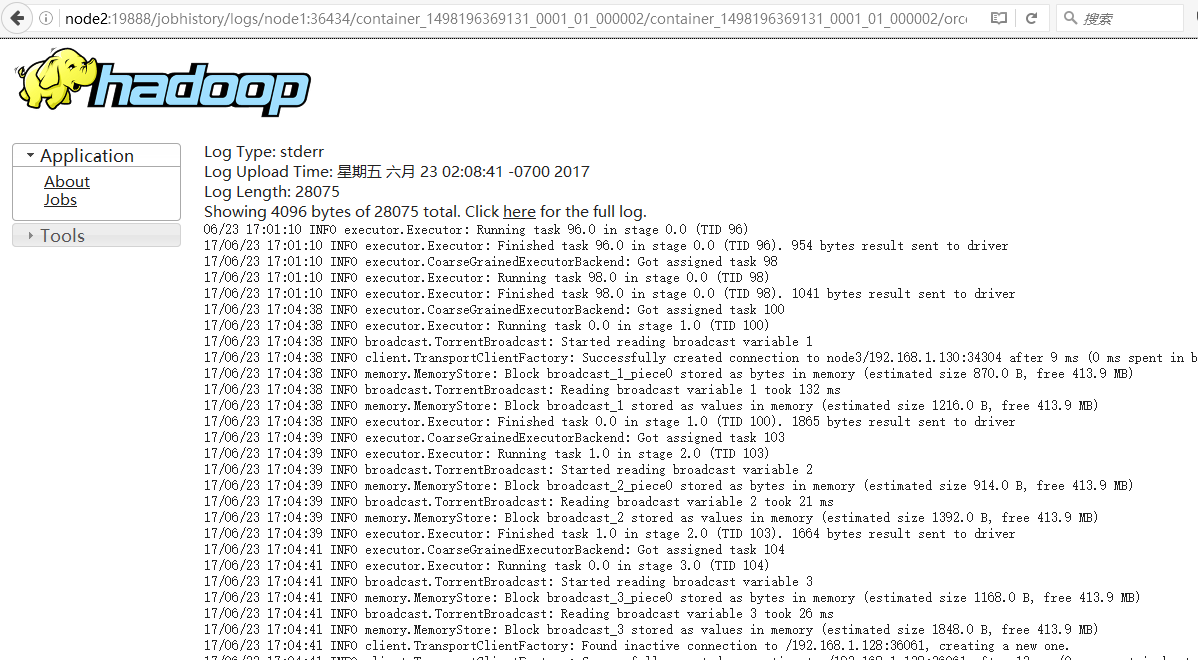
为了能够看到这些日志,我们要做的事情是,让nodemanager开启一个日志聚合的功能,这个功能的作用是,当应用程序终止的时候,需要将这个应用程序产生的所有日志全部聚集到远程hdfs上的一个目录,聚集之后,还需要通过一个http的接口去查看这些日志,查看日志的这个角色就叫做mr的history server,通过她的web ui接口,当我们点击std日志的时候,就会跳转到mr job history server这个地址上19888上,然后去把这个日志展示出来
三、总结
总的来说,yarn-site.xml和conf/spark-defaults.conf这两个配置文件中的地址比较关键
http://node2:19888/jobhistory/logs : 对应的是点击strout的时候跳转的地址
spark.yarn.historyServer.address=node2:18080 :对应的是在yarn里点击history,跳转的地址
注①:
1、进入yarn的web ui页面,点击左侧FINISHED,可查看运行完的作业,点击一个app id

2、进入下图页面,点击History
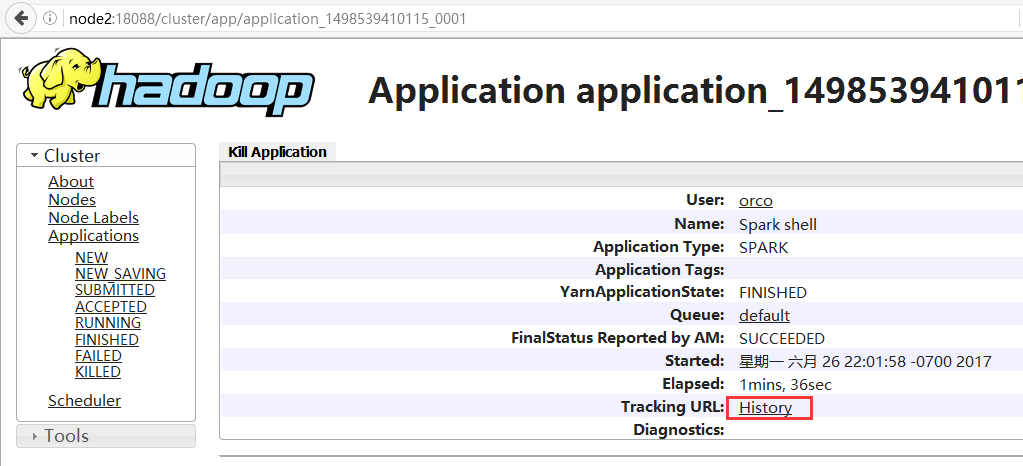
3、重定向到conf/spark-defaults.conf配置的地址

注②:
具体步骤如下:
1、我先运行一个spark程序
bin/spark-shell --master local
2、登录Spark History server的web ui
http://node1:18080/
3、如下图,找到我刚才运行的程序
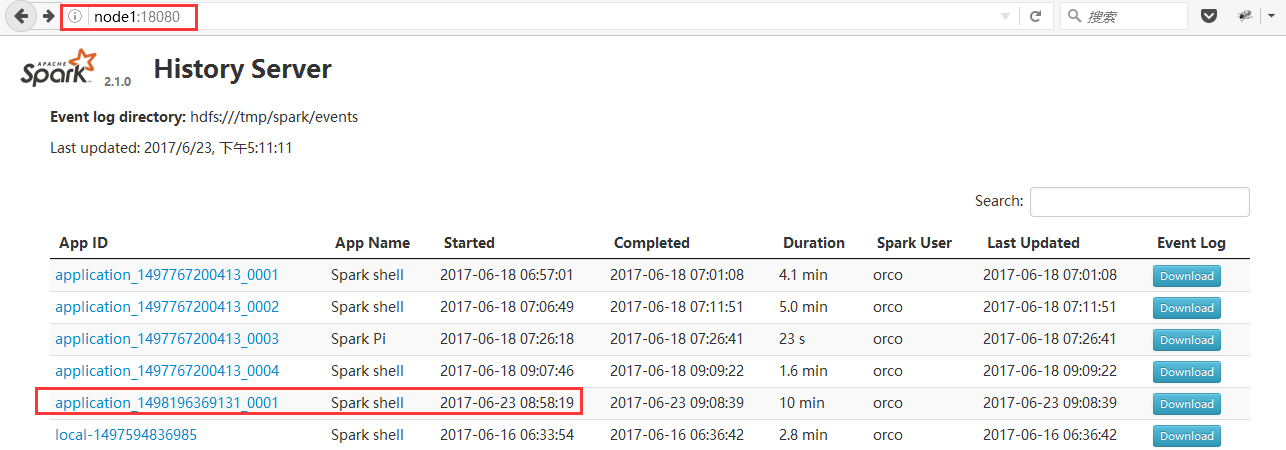 4、点击红框位置App ID,进入如下图页面
4、点击红框位置App ID,进入如下图页面
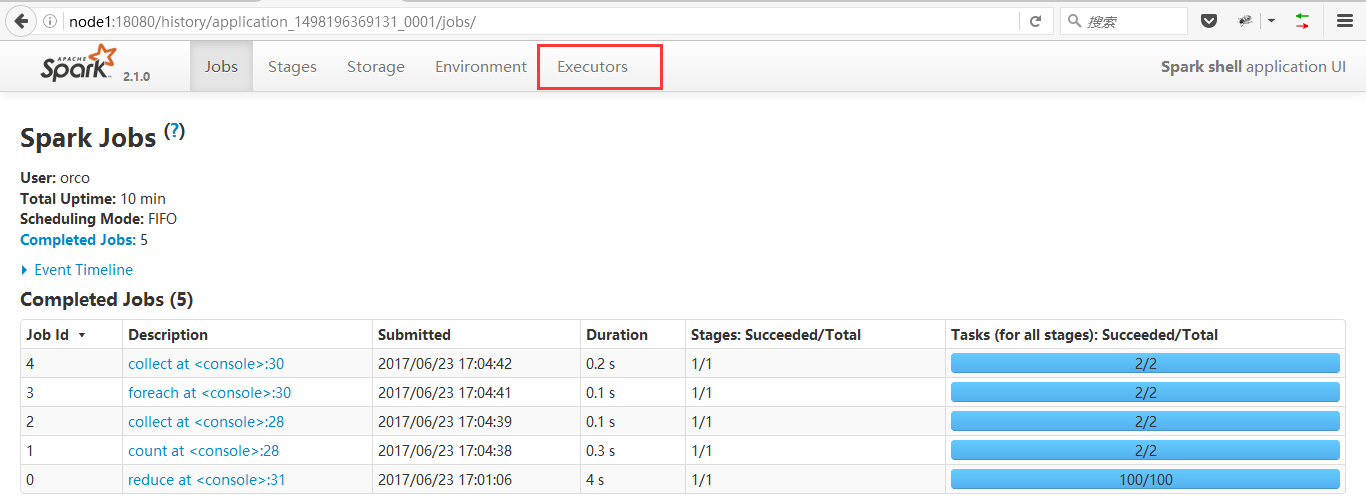
5、点击红框位置Executor,进入下图页面
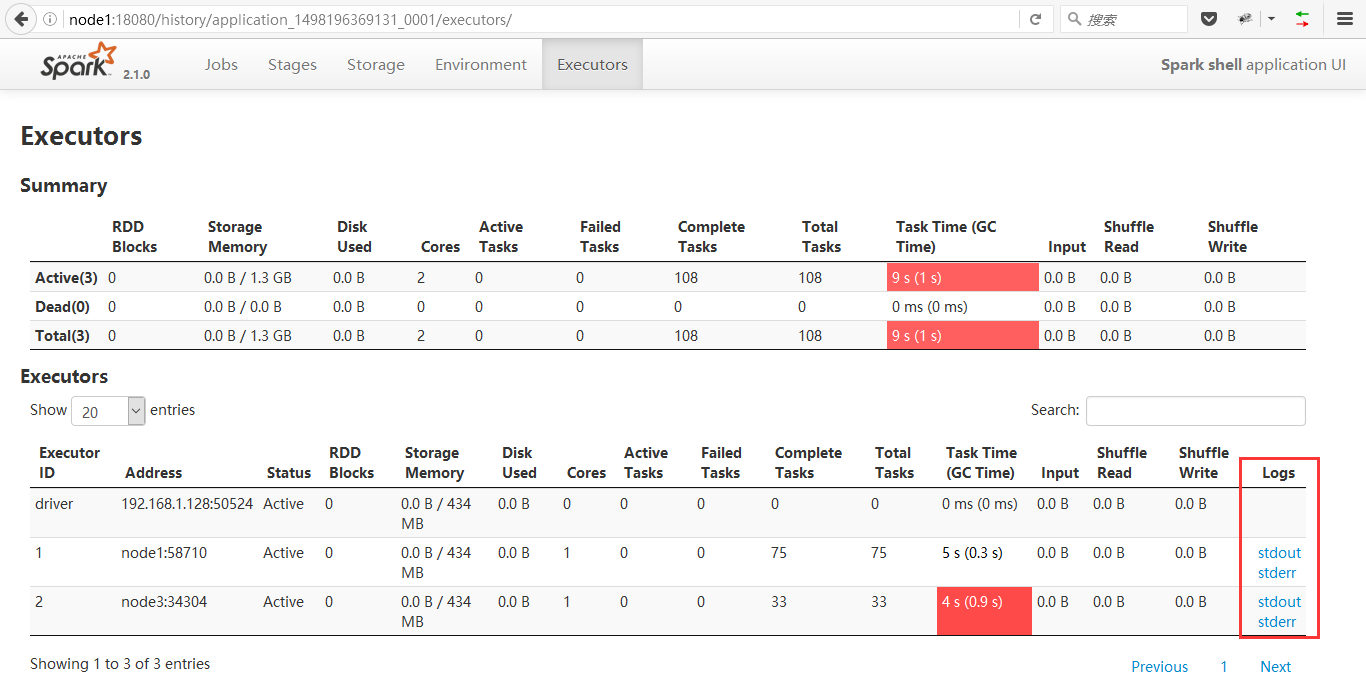
6、右下角的stderr和stdout就是我们此行的目标了
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
当你点击stderr或stdout,就会重定向到node2:19888,所以如果这里你配错了,那这两个日志你是看不了的
node2:19888是你的MapReduce job history server的启动节点地址
进入页面如下图
spark深入:配置文件与日志的更多相关文章
- Spark进阶之路-日志服务器的配置
Spark进阶之路-日志服务器的配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果你还在纠结如果配置Spark独立模式(Standalone)集群,可以参考我之前分享的笔记: ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- php源码建博客5--建库建表-配置文件-错误日志
主要: 整理框架 建库建表 配置文件类 错误日志记录 --------------本篇后文件结构:-------------------------------------- blog ├─App │ ...
- [spark案例学习] WEB日志分析
数据准备 数据下载:美国宇航局肯尼迪航天中心WEB日志 我们先来看看数据:首先将日志加载到RDD,并显示出前20行(默认). import sys import os log_file_path =' ...
- 【夯实Mysql基础】MySQL在Linux系统下配置文件及日志详解
本文地址 分享提纲: 1. 概述 2. 详解配置文件 3. 详解日志 1.概述 MySQL配置文件在Windows下叫my.ini,在MySQL的安装根目录下:在Linux下叫my.cnf,该文件位于 ...
- 写一个简单的配置文件和日志管理(shell)
最近在做一个Linux系统方案的设计,写了一个之前升级服务程序的配置和日志管理. 共4个文件,服务端一个UpdateServer.conf配置文件和一个UpdateServer脚本,客户端一个Upda ...
- 010 Spark中的监控----日志聚合的配置,以及REST Api
一:History日志聚合的配置 1.介绍 Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况 默认情况下历史日志是保存到tmp文件夹中的 2.参考官网的知识点 ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
随机推荐
- Home Assistant + 树莓派:强大的智能家居系统 · 安装篇
Home Assistant + 树莓派:强大的智能家居系统 · 安装篇 转载:Home Assistant + 树莓派:强大的智能家居系统 · 安装篇 目录 1. 初始安装 3. Homebridg ...
- github安装k8s
转:https://mritd.me/2016/10/29/set-up-kubernetes-cluster-by-kubeadm/#23镜像版本怎么整 一.环境准备 首先环境还是三台虚拟机,虚拟机 ...
- python 并集union, 交集intersection, 差集difference, 对称差集symmetric_difference
python的集合set和其他语言类似,是一个无序不重复元素集, 可用于消除重复元素. 支持union(联合), intersection(交), difference(差)和sysmmetric d ...
- Linux嵌入式文件系统(网络文件系统)
<文件系统定义> 怎么将文件和文件目录加载到linux内核中,这一种加载的方式就叫做文件系统 <建立根文件系统目录和文件> <创建目录> 1)在linux系统中使用 ...
- Spring的优点
Spring的优点 1.低侵入式设计,代码污染极低: 2.独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺: 3.Spring的DI机 ...
- 拆分Cocos2dx 渲染项目 总结
因为只拆分了渲染的内容,所以代码只针对渲染部分进行分析. 代码涉及到这些类: CCImage,对图片的数据进行操作 CCNode,CCSprite,结点类 CCProgram,CCRenderer,C ...
- Codeforces Round #358 (Div. 2) E. Alyona and Triangles 随机化
E. Alyona and Triangles 题目连接: http://codeforces.com/contest/682/problem/E Description You are given ...
- ZOJ 2970 Faster, Higher, Stronger
F - Faster, Higher, Stronger Time Limit:2000MS Memory Limit:65536KB 64bit IO Format:%lld &am ...
- LR下监控windows系统资源方法
1. 通过客户端与服务器进行网络测试,保证通信畅通.(测试主机本身) 2. 在运行中输入,service.msc打开系统的服务设置,开启服务器端Windows中的如 ...
- Lucene——索引的创建、删除、修改
package cn.tz.lucene; import java.io.File; import java.util.ArrayList; import java.util.List; import ...