torch_12_BigGAN全文解读
1.摘要:
尽管近来生成图片模型取得了进步,成功生成了高分辨率的图片,但是在复杂的数据集中,样本的多样性仍然是难以捉摸的目标。本文尝试在大规模上训练生成对抗网络,并研究这种规模下的不稳定性。我们发现将正交正则化应用于生成器使其能够适应简单的‘截断处理,允许通过减少生成器输入的方差来精细的控制样本保真度和变化之间的权衡。
2.三个贡献:
1.增大GAN的规模能显著提升建模的效果,模型的参数比之前增大2-4倍,训练的batch尺寸增加了8倍。文章提出了两种简单而又具有一般性的框架改进,可以提高模型的收缩性,并且改进了一种正则化策略来提升条件作用,证明了这些方法能够提升性能。
2.作为这些策略的副产品,本文提出的模型变得更服从截断技巧。截断技巧是一种简单的采样方法,能够在样本的逼真性,多样性之间做显式的,细粒度的控制。
3.发现了使大规模GAN不稳定的原因,对它们进行了经验性的分析,更进一步的,作者发现将已有的和新的技巧的组合使用能够降低这种不稳定性,但是完全的训练只有在巨大的性能代价下才能获得
3.背景
生成对抗网络由一个生成器和一个判别器组成,前者的作用是根据随机噪声数据生成逼真的随机样本,后者的作用是鉴别样本是真实的还是生成器生成的。在最早的版本中,GAN训练时的优化目标为达到极大值-极小值问题的纳什平衡。当用于图像分类任务时,G和D一般都是卷积神经网络。如果不使用一些辅助性的增加稳定性技巧,训练过程非常脆弱,收敛效果差,需要精细设计的超参数和网络结构的选择以保证效果。
近期的研究工作集中修改初始的GAN算法,使它更稳定。其中一种思路是修改训练的目标函数以确保收敛。另外一种思路是通过梯度惩罚或归一化技术对D进行限定,这两种方法都是在抵抗无界的目标函数的使用,确保任意的G,D都能提供梯度。
与我们工作很相关的是谱归一化,它强制D的lipschitz连续性,这通过对他们的最大奇异值进行运行时动态估计,以此对D的参数进行归一化而实现。另外,还包括逆向动力学,对主奇异值方向进行自适应正则化。文献[1]分析了G的的雅克比矩阵的条件数,发现GAN的表现依赖于此条件数。文献[2]发现将谱归一化作用于G能够提高稳定性,使得训练算法每次迭代时能够减少D的迭代次数。本文对这些方法进行了进一步分析,以弄清GAN训练的机理。
另外一些工作聚焦在网络结构的选择上。SA-GAN增加了一种称为self-attention的模块来增强G,D的能力。ProGAN通过使用逐步增加的分辨率的图像训练单个模型。
条件GAN为gan增加了类信息,作为生成器和判别器的输入,类信息可以采用one hot编码,和随机噪声拼接起来,作为G的输入。另外,可以在批量归一化层中加入。在类中也加入了类别信息。
4.评价指标:
生成图片的质量
生成图片的多样性
IS:
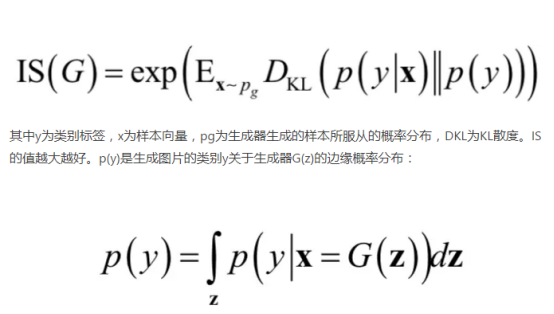
如果生成图片只有一种,那么生成图像的IS依然会很高,这是IS的缺点。而FID相较于IS更适合用于图片生成质量的评价,与IS不同,越小的值意味着更好的生成图片的质量以及更丰富的图片的多样性。在所有生成的图像仅为一种类别时,其取值将会很高。

5.增大GAN的规模
本文重点探讨增大模型的规模,增大batch的尺寸来获得性能上的提升。作为基础模型,选用了SA-GAN,使用hing loss目标函数。通过类条件归一化为G提供类信息,通过Projection为D提供类信息。优化器的设置与文献[4]相同,对G使用了谱归一化。G每迭代一次,D迭代两次。为了进行评估,利用了G的权重移动平均值,利用正交初始化,在所有设备上以G为单位计算bathNorm统计信息,而不是按设备计算。
一开始通过对基线模型增加batch大小,发现这样做有很大的好处。作者推断这是因为batch size增大之后,每个batch中的数据覆盖到的模式更多,能为生成器和判别器提供更好的梯度。但是,单纯的增加batch size带来了非常明显的副作用,迭代次数较少的情况下,效果反而更好,如果继续训练,训练过程不再稳定,并出现梯度塌陷的现象。
接下来,我们每一层增加50%的宽度(通道数),模型的参数大约增加了一倍,导致了IS%21的提升,增加深度,并没有得到改善,解决这一问题采用的是一个不同的残差块结构。
将类嵌入c应用到G的conditional batchnorm层包含大量的权重,本文选择共享的类嵌入,线性投影到各个层的weights和biases,在减少了计算需求和内存需求的情况下,训练速度提升了37%,另外,还使用了层次隐变量空间,具体做法是将噪声向量送入到G的多个层中,而不只是输入层。使用这种方法可以使得不同分辨率不同层级的特征被噪声向量直接影响。

Batch:batch size
Ch:channel
Param:参数量
shared:使用共享嵌入,在生成器的BN层中加入类别信息嵌入,将会大大参加参数量,因此选择共享嵌入,也就是对每层的weights和bias做投影,这样减少了计算和内存的开销,将训练速度提升37%
Hier:使用分层的潜在空间,也就是在生成器网络的每一层都会被喂入噪声向量。分层空间增加了计算量和内存消耗,但是精度提升4%,训练速度加快18%
Ortho:使用正交正则化
itr:迭代次数
FID:表示生成图像的多样性,越小越好
IS:表示生成图像的质量,越大越好
6.使用截断技巧在真实性和多样性之间做折中
(在输入噪声上改进)
生成器的输入一般使用正态分布或者均匀分布的随机数,本文采用了截断技术,对正太分布的随机数进行了截断处理,实验发现这种方法的结果最好。对此直观的解释是,如果网络的随机噪声输入的随机数变动范围越大,生成的样本在标准模板上变动就越大,因此样本的多样性就越强,但真实性可能会降低。首先用截断的正太分布N(0,1)随机数产生噪声向量z,具体做法是如果随机数超出已定义范围,则重新采样,使得其落在这个区间里。这种做法称为截断技巧,将向量z进行截断,模超过某一指定阈值的随机数进行重采样,这样可以提高单个样本的质量,但代价是降低了样本的多样性。一些较大的模型不适合截断,当输入截断噪声时会产生饱和。为了解决这个问题,试图调节G的光滑性来增强对截断的适应性,从而使z的整个空间映射到良好的输出样本。

7.总结
实验结果发现,现有的GAN技巧已经足以训练大规模的,分布式的,大批量的模型。尽管这样,训练时还是容易坍塌,实现时,需要提前终止。
8.分析
8.1生成器的不稳定性
本文着重对小规模时稳定,大规模时不稳定的问题进行分析。在训练的过程中监测一系列权重,梯度和损失,寻找一种可能预示训练崩溃开始的指标,我们发现每个权重矩阵的前三个奇异值信息量是最大的,可以使用Alrnoldi迭代法有效的计算它们,该方法扩展Miyato等人的使用的幂迭代法到附加奇异向量和值的估计。但是在有些层表现不好,其谱规范在训练过程中不断增长,并且在崩溃时爆炸。为了确定这种病理是否是崩溃的原因或仅仅是一种症状,我们研究了对G施加额外条件作用以明确对抗光谱爆炸的效果。首先,我们直接将每一个权重的第一个值奇异值正则化,其次,用部分奇异值分解对最大特征值进行阶段处理,给定权重矩阵w,它的第一个奇异向量u0,v0,σclamp为σ0截断后的值。权重的更新公式:
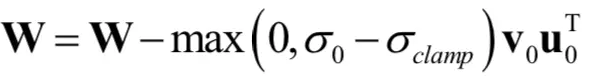
最终结果:不管有无谱归一化,这样的改进都可以提升训练的平稳性,但是不能解决爆炸的问题,因此对判别器进行改进。
8.2判别器的不稳定性
与G不同,D的频谱是有噪声的,σ0,σ1表现良好,奇异值在整个训练过程中增长,但只在崩溃时跳跃,而不是爆炸。
论文假设频谱噪声是导致训练不平稳的因素,因此很自然的想法是进行梯度惩罚,通过对R1进行0均值的正则化惩罚来进行改善。
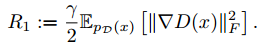 其中γ是常数
其中γ是常数
论文实验表明,惩罚越大,训练越平稳,但是精度也越来越低
9.网络结构
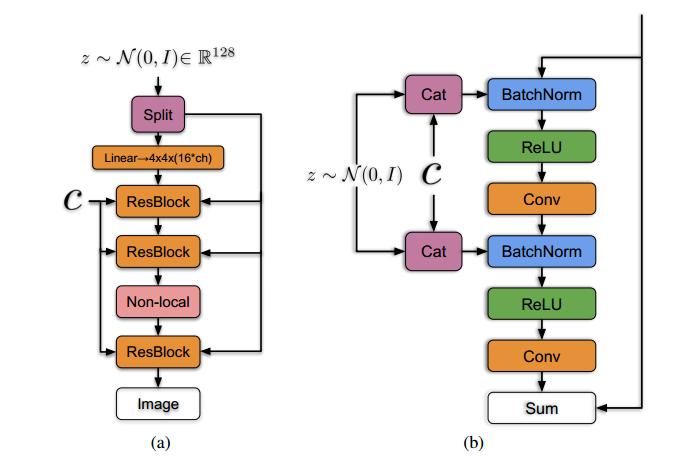
网络基于ResNet进行了修改,每一个block的输入和输出都相等。
网络输入为N(0,1)的正太分布
左侧实心线C表示共享嵌入,右侧实心线表示分层的潜在空间。
(a)表示整体网络结构 (b)表示每个block结构
torch_12_BigGAN全文解读的更多相关文章
- 标签一致项(LC-KSVD)-全文解读
Learning A Discriminative Dictionary for Sparse Coding via Label Consistent K-SVD 1,同步学习判决字典和线性分类器 2 ...
- 联合CRF和字典学习的自顶向下的视觉显著性-全文解读
top-down visual saliency via joint CRF anddictionary learning 自顶向下的视觉显著性是使用目标对象的可判别表示和一个降低搜索空间的概率图来进 ...
- 2019微信公开课 同行With Us 听课笔记及演讲全文
[2019WeChat 微信公开课] 产品理念: 微信启动页 一个小人站在地球前面,每个人都有自己的理解和解读 所谓异类,表示与别人与众不同,即优秀的代名词. 微信的与众不同体现在尊重用户对产品的感受 ...
- (转)mblog解读(二)
(二期)12.开源博客项目mblog解读(二) [课程12]freema...模板.xmind77.9KB [课程12]hibernat...arch.xmind0.1MB freemarker模板技 ...
- 解读ARM成功秘诀:薄利多销推广产品
解读ARM成功秘诀:薄利多销推广产品 2013年07月04日 15:04 新浪科技 微博 我有话说(2人参与) 导语:美国电子杂志Slate周一发表署名 法哈德·曼约奥(Farhad M ...
- 百度大脑UNIT3.0解读之对话式文档问答——上传文档获取对话能力
在日常生活中,用户会经常碰到很多复杂的规章制度.规则条款.比如:乘坐飞机时,能不能带宠物上飞机,3岁小朋友是否需要买票等.在工作中,也会面对公司多样的规定制度和报销政策.比如:商业保险理赔需要什么材料 ...
- 【转载】深度解读 java 线程池设计思想及源码实现
总览 开篇来一些废话.下图是 java 线程池几个相关类的继承结构: 先简单说说这个继承结构,Executor 位于最顶层,也是最简单的,就一个 execute(Runnable runnable) ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- MongoDB 4.2 新特性解读 (转载)
MongoDB World 2019 上发布新版本 MongoDB 4.2 Beta,包含多项数据库新特性,本文尝试从技术角度解读. Full Text Search MongoDB 4.2 之前,全 ...
随机推荐
- linux服务器上配置进行kaggle比赛的深度学习tensorflow keras环境详细教程
本文首发于个人博客https://kezunlin.me/post/6b505d27/,欢迎阅读最新内容! full guide tutorial to install and configure d ...
- shell 命令 tar -zxvf 解压 tar -zcvf 压缩
tar -zxvf 解压 tar -zcvf 压缩
- Netty — 心跳检测和断线重连
一.前言 由于在通信层的网络连接的不可靠性,比如:网络闪断,网络抖动等,经常会出现连接断开.这样对于使用长连接的应用而言,当突然高流量冲击势必会造成进行网络连接,从而产生网络堵塞,应用响应速度下降,延 ...
- SpringBoot开发案例之mail中文附件名字乱码
最近在开发一个邮件发送多附件的微服务,使用的是org.springframework.mail.javamail.JavaMailSender;包下面的JavaMailSender 但是发送出来的附件 ...
- 前端之html5和css3
圆角,透明度,rgba CSS3圆角 设置某一个角的圆角,比如设置左上角的圆角:border-top-left-radius:30px 60px;同时分别设置四个角: border-radius:30 ...
- python web框架Flask——csrf攻击
CSRF是什么? (Cross Site Request Forgery, 跨站域请求伪造)是一种网络的攻击方式,它在 2007 年曾被列为互联网 20 大安全隐患之一,也被称为“One Click ...
- jQuery之概念以及基本使用
1. jQuery的概述 1.1 jQuery的概念 jQuery是一个快速.简洁的JavaScript库,其设计的宗旨是“Write Less,Do More” jQuery主要是封装了JavaSc ...
- 使用原生Ajax进行用户名重复的检验
title: 使用原生Ajax进行用户名重复的检验(一) date: 2019-01-21 17:35:15 tags: [JavaScript,Ajax] --- Ajax的复习 距离刚开始学aja ...
- Kali 无线网络
WiFi——必备的一个东西: AP:这是无线用户接入到互联网的设备 ESSID:可以用于无限局域网中的多个AP中 BSSID:每个AP的唯一标识符 SSID:网络名称 Channels Wi-Fi可以 ...
- PHP代码篇(七)--PHP及MySQL已经使用过的函数
一.PHP常用函数 //数组转字符串 $str = implode(',',$device_string); //字符串转数组 $arr = explode(',',$device_string); ...