Flume 学习笔记之 Flume NG+Kafka整合
Flume NG集群+Kafka集群整合:
修改Flume配置文件(flume-kafka-server.conf),让Sink连上Kafka
hadoop1:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
hadoop2:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop2
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop2:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
集群测试:
- 启动zookeeper(hadoop1,hadoop2,hadoop3)
- 启动kafka server和consumer(hadoop1,hadoop2)
- 启动Flume server(hadoop1,hadoop2):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-kafka-server.conf --name a1 -Dflume.root.logger=INFO,console
- 启动Flume client(hadoop3):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
- 在hadoop3上追加一条日志记录
- kafka consumer收到记录,从则测试完毕。
hadoop3:

hadoop1:
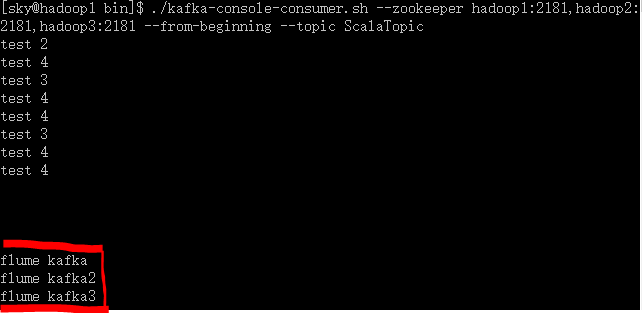
测试完毕,这样Flume+kafka就整合起来了,即Flume+Kafka+Spark Streaming的实时日志分析系统就孕育而生了。
Flume 学习笔记之 Flume NG+Kafka整合的更多相关文章
- Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建: 架构总图: 架构分配: 角色 Host 端口 agent1 hadoop3 52020 collector1 hadoop1 52020 collector2 had ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- flume学习笔记——安装和使用
Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. Flume是一 ...
- Spring学习笔记(六)—— SSH整合
一.整合原理 二.整合步骤 2.1 导包 [hibernate] hibernate/lib/required hibernate/lib/jpa 数据库驱动 [struts2] struts-bla ...
- Flink学习笔记:Connectors之kafka
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 【Flume学习之一】Flume简介
环境 apache-flume-1.6.0 Flume是分布式日志收集系统.可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase:同类工具:Facebook Scribe,Apache ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Apache Flume 学习笔记
# 从http://flume.apache.org/download.html 下载flume ############################################# # 概述: ...
- flume学习笔记
#################################################################################################### ...
随机推荐
- codeforces 816 B. Karen and Coffee(思维)
题目链接:http://codeforces.com/contest/816/problem/B 题意:给出n个范围,q个查询问查询区间出现多少点在给出的n个范围中至少占了k次 题解:很显然的一道题目 ...
- Go语言os标准库常用方法
1. os.Getwd()函数 原型:func Getwd()(pwd string, err error) 作用:获取当前文件路径 返回:当前文件路径的字符串和一个err信息 示例: package ...
- Java代理设计模式(Proxy)的几种具体实现
Proxy是一种结构设计模型,主要解决对象直接访问带来的问题,代理又分为静态代理和动态代理(JDK代理.CGLIB代理. 静态代理:又程序创建的代理类,或者特定的工具类,在平时开发中经常用到这种代理模 ...
- window下载安装maven
Maven官网下载地址:https://maven.apache.org/download.cgi,这里我们下载zip包即可 解压到安装目录下 新建环境变量MAVEN_HOME,复制Maven安装 ...
- 漏洞复现:MS17-010缓冲区溢出漏洞(永恒之蓝)
MS17-010缓冲区溢出漏洞复现 攻击机:Kali Linux 靶机:Windows7和2008 1.打开攻击机Kali Linux,msf更新到最新版本(现有版本5.x),更新命令:apt-get ...
- Java 13 明天发布,最新最全新特性解读
2017年8月,JCP执行委员会提出将Java的发布频率改为每六个月一次,新的发布周期严格遵循时间点,将在每年的3月份和9月份发布. 目前,JDK官网上已经可以看到JDK 13的进展,最新版的JDK ...
- Net基础篇_学习笔记_第十天_方法_方法的调用问题
在Main()函数中,调用Test()函数,我们管Main()函数称之为调用者,管Test()函数称之为被调用者.如果被调用者想要得到调用者的值:1).传递参数.2).使用静态字段来模拟全局变量.如果 ...
- JAVA多线程高并发面试题总结
ReadMe : 括号里的内容为补充或解释说明. 多线程和高并发是毕业后求职大厂面试中必问的知识点,自己之前总是面试前才去找相关的知识点面试题来背背,隔段时间又忘了,没有沉淀下来,于是自己总结了下相关 ...
- Spring Boot 入门之整合 log4jdbc 篇(六)
博客地址:http://www.moonxy.com 一.前言 Spring Data JPA 默认采用 Hibernate 实现.Hibernate 的 showSql 配置只打印 SQL,但并不打 ...
- Linux(Centos7)yum安装最新mysql
环境 CentOS 7.1 (64-bit system) MySQL 5.6.24 CentOS 安装 参考:http://www.waylau.com/centos-7-installation- ...