Flume 学习笔记之 Flume NG+Kafka整合
Flume NG集群+Kafka集群整合:
修改Flume配置文件(flume-kafka-server.conf),让Sink连上Kafka
hadoop1:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
hadoop2:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop2
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop2:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
集群测试:
- 启动zookeeper(hadoop1,hadoop2,hadoop3)
- 启动kafka server和consumer(hadoop1,hadoop2)
- 启动Flume server(hadoop1,hadoop2):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-kafka-server.conf --name a1 -Dflume.root.logger=INFO,console
- 启动Flume client(hadoop3):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
- 在hadoop3上追加一条日志记录
- kafka consumer收到记录,从则测试完毕。
hadoop3:

hadoop1:
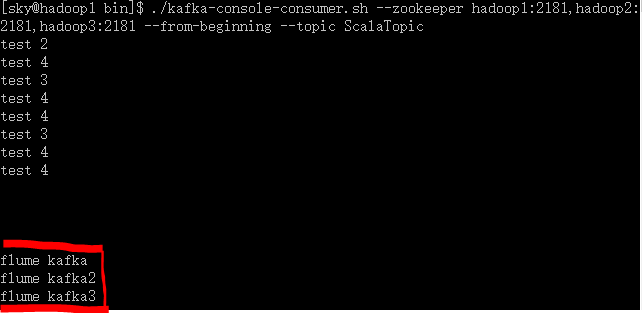
测试完毕,这样Flume+kafka就整合起来了,即Flume+Kafka+Spark Streaming的实时日志分析系统就孕育而生了。
Flume 学习笔记之 Flume NG+Kafka整合的更多相关文章
- Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建: 架构总图: 架构分配: 角色 Host 端口 agent1 hadoop3 52020 collector1 hadoop1 52020 collector2 had ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- flume学习笔记——安装和使用
Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. Flume是一 ...
- Spring学习笔记(六)—— SSH整合
一.整合原理 二.整合步骤 2.1 导包 [hibernate] hibernate/lib/required hibernate/lib/jpa 数据库驱动 [struts2] struts-bla ...
- Flink学习笔记:Connectors之kafka
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 【Flume学习之一】Flume简介
环境 apache-flume-1.6.0 Flume是分布式日志收集系统.可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase:同类工具:Facebook Scribe,Apache ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Apache Flume 学习笔记
# 从http://flume.apache.org/download.html 下载flume ############################################# # 概述: ...
- flume学习笔记
#################################################################################################### ...
随机推荐
- hihocoder #1609 : 数组分拆II(思维)
题目链接:http://hihocoder.com/problemset/problem/1609 题解:就先拿一个数组最多分成两部分来说吧 8 1 2 3 4 5 1 2 3 显然 输出时2 3 可 ...
- 牛客第五场多校 J plan 思维
链接:https://www.nowcoder.com/acm/contest/143/J来源:牛客网 There are n students going to travel. And hotel ...
- The Suspects POJ1611
The Suspects Time Limit: 1000MS Memory Limit: 20000K Total Submissions: 36417 Accepted: 17681 De ...
- box-sizing(CSS3)
CSS3新增了盒模型box-sizing,属性值有下面三个: content-box 默认值,让元素维持W3C的标准盒模型.元素的宽度/高度(width/height)= 元素内容框宽度/高度(con ...
- Erlang模块gen_tcp翻译
概述 TCP/IP套接字接口 描述 gen_tcp模块提供了使用TCP / IP协议与套接字进行通信的功能. 以下代码片段提供了一个客户端连接到端口5678的服务器的简单示例,传输一个二进制文件并关闭 ...
- Storm 系列(六)—— Storm 项目三种打包方式对比分析
一.简介 在将 Storm Topology 提交到服务器集群运行时,需要先将项目进行打包.本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明.主要打包方式有以下三种: 第一种:不加任 ...
- FreeSql (三十三)CodeFirst 类型映射
前面有介绍过几篇 CodeFirst 内容文章,有 <(二)自动迁移实体>(https://www.cnblogs.com/FreeSql/p/11531301.html) <(三) ...
- SoloLear_C# Tutorial_Contents
一.Basic Concepts 基本概念 二.Conditionals and Loops 条件语句和循环 三.Methods 方法 四.Classes&Objects 类&对象 五 ...
- windows安装mingw和LuaJIT
1,安装mingw64 先下载mingw64压缩包(不建议下载exe安装包,在线安装太慢),地址如下: https://nchc.dl.sourceforge.net/project/mingw-w6 ...
- 漫谈Java中的OOPS
什么是OOPS? 面向对象编程是一种编程概念,其工作原理是对象是程序中最重要的部分.它允许用户创建他们想要的对象,然后创建处理这些对象的方法.操作这些对象以获得结果是面向对象编程的目标. 面向对象编程 ...