centos7单机安装kafka,进行生产者消费者测试
原文出处:http://www.yund.tech/zdetail.html?type=1&id=3028469704c7976aef5b824811dd3bf5
作者:jstarseven
一、kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展
二、kafka架构图
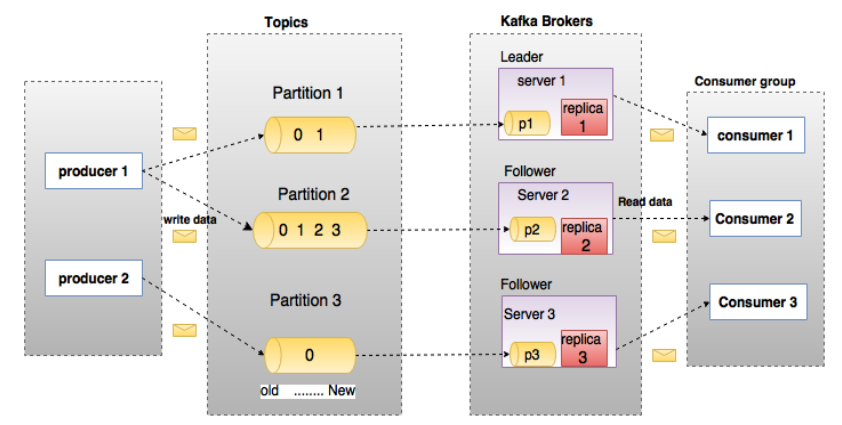

三、kafka安装与测试
1、配置JDK环境
Kafka 使用Zookeeper 来保存相关配置信息,Kafka及Zookeeper 依赖Java 运行环境,从oracle网站下载JDK 安装包,解压安装
tar zxvf jdk-8u171-linux-x64.tar.gz
mv jdk1..0_171 /usr/local/java/
设置Java 环境变量:
#java
export JAVA_HOME=/usr/local/java/jdk1..0_171
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
2、安装kafka
下载地址:http://kafka.apache.org/downloads
cd /opt
wget http://mirror.bit.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
tar zxvf kafka_2.-2.3..tgz
mv kafka_2.-2.3. /usr/local/apps/
cd /usr/local/apps/
ln -s kafka_2.-2.3. kafka
3、启动测试
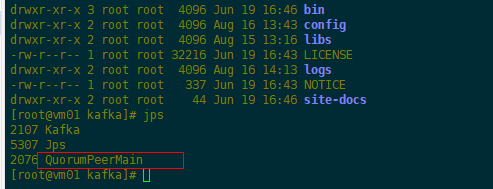
(1)启动Zookeeper服务
cd /usr/local/apps/kafka
#执行脚本
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#查看进程
jps
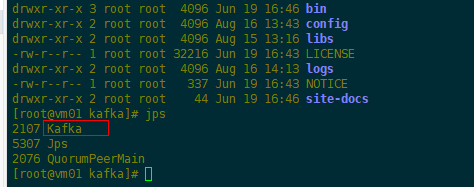
(2)启动单机Kafka服务
#执行脚本
bin/kafka-server-start.sh config/server.properties
#查看进程
jps
(3)创建topic进行测试
#执行脚本
bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test
(4)查看topic列表
#执行脚本
bin/kafka-topics.sh --list --zookeeper localhost:
输出:test

(5)生产者消息测试
#执行脚本(使用kafka-console-producer.sh 发送消息)
bin/kafka-console-producer.sh --broker-list localhost: --topic test

(6)消费者消息测试
#执行脚本(使用kafka-console-consumer.sh 接收消息并在终端打印)
bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning

4、单机多broker集群配置
单机部署多个broker,不同的broker,设置不同的id、监听端口、日志目录
cp config/server.properties config/server-.properties
vim server-.properties
#修改:
broker.id=
port=
log.dir=/tmp/kafka-logs-
#启动Kafka服务
bin/kafka-server-start.sh config/server-.properties &
5、java代码实现生产者消费者
(1)maven项目添加kafka依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.</version>
</dependency>
(2)java代码实现
package com.server.kafka; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer; import java.util.Collections;
import java.util.Properties;
import java.util.Random; public class KafakaExecutor { public static String topic = "test"; public static void main(String[] args) {
new Thread(()-> new Producer().execute()).start();
new Thread(()-> new Consumer().execute()).start();
} public static class Consumer { private void execute() {
Properties p = new Properties();
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.21.181:9092");
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.GROUP_ID_CONFIG, topic); KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(p);
// 订阅消息
kafkaConsumer.subscribe(Collections.singletonList(topic)); while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("topic:%s,offset:%d,消息:%s", //
record.topic(), record.offset(), record.value()));
}
}
}
} public static class Producer { private void execute() {
Properties p = new Properties();
//kafka地址,多个地址用逗号分割
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.21.181:9092");
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p); try {
while (true) {
String msg = "Hello," + new Random().nextInt(100);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg);
kafkaProducer.send(record);
System.out.println("消息发送成功:" + msg);
Thread.sleep(500);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
kafkaProducer.close();
}
} }
}
(3)测试结果(上面使用脚本命令执行消费者的终端也会同步输出消息数据)

参考:https://www.cnblogs.com/frankdeng/p/9310684.html
-END-

centos7单机安装kafka,进行生产者消费者测试的更多相关文章
- centos7单机安装kafka
基础要求操作系统:CentOS 7x 64位 kafka版本:kafka_2.11-0.8.2.1 #安装使用的jdk以及kafka的包我放到百度云了,需要自取. # 链接:https://pan.b ...
- Centos7.5安装kafka集群
Tags: kafka Centos7.5安装kafka集群 Centos7.5安装kafka集群 主机环境 软件环境 主机规划 主机安装前准备 安装jdk1.8 安装zookeeper 安装kafk ...
- helm安装kafka集群并测试其高可用性
介绍 Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 这种动作( ...
- Kafka入门之生产者消费者测试
目录: kafka启动脚本以及关闭脚本 1. 同一个生产者同一个Topic,两个相同的消费者相同的Group 2. 同一个生产者同一个Topic,两个消费者不同Group 3. 两个生产者同一个Top ...
- 基于Kafka的生产者消费者消息处理本地调试
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/68174111冷血之心的博客) Kafka下载地址:http://d ...
- 【kafka】生产者速度测试
非常有用的参考博客:http://blog.csdn.net/qq_33160722/article/details/52903380 pykafka文档:http://pykafka.readthe ...
- Centos7单机安装Tableau2018.2
cd先将服务器防火墙80级8850端口打开 临时关闭SELinux/防火墙 setenforce 0 iptables -F 重点 重点 不能用root用户安装 不能用root用户安装 第一步先创建一 ...
- kafka配置监控和消费者测试
概念 运维 配置 监控 生产者与消费者 流处理 分区partition 一定条件下,分区数越多,吞吐量越高.分区也是保证消息被顺序消费的基础,kafka只能保证一个分区内消息的有序性 副本 每个分区有 ...
- Windows环境安装kafka
前言 注意事项: 需要有jdk,jdk8以上.配置好环境变量. 参看链接:https://blog.csdn.net/weixin_38004638/article/details/91893910 ...
随机推荐
- centos7 + Nginx+ HTTPS + uwsgi + python3.6 + Docker + Django1.11 + mysql 5.6 + virtualenv 环境搭建
环境搭建: 系统: centos7.2 x64 开发环境: python3.6 Django 1.11 虚拟环境: [Docker](https://www.runoob.com/dock ...
- web项目超时方案
1. 场景描述 平台使用的Greenplum(内核是postgresql8.2)集群存储大数据量数据(每天一个表大概3亿),因为数据量比较大,所以在使用上有些限制,一是操作限制:二是不限制,但是到一定 ...
- (转)android自定义控件
原帖地址:http://my.oschina.net/wangjunhe/blog/99764 创建新的控件: 作为一个有创意的开发者,你经常会遇到安卓原生控件无法满足你的需求. 为了优化你的界面和工 ...
- 机器学习-利用pickle加载cifar文件
首先这里有百度云的数据集供大家下载:(官网太慢了) 链接:https://pan.baidu.com/s/1G0MxZIGSK_DyZTcuNbxraQ 提取码:ui51 复制这段内容后打开百度网盘手 ...
- [leetcode] 51. N-Queens (递归)
递归,经典的八皇后问题. 利用一位数组存储棋盘状态,索引表示行,值为-1表示空,否则表示列数. 对行进行搜索,对每一行的不同列数进行判断,如果可以摆放符合规则,则摆放,同时遍历下一行. 遍历过程中,若 ...
- 【原创】用事实说话,Firefox 的性能是 Chrome 的 2 倍,Edge 的 4 倍,IE11 的 6 倍!
前言 每个浏览器新版本发布,都号称性能有显著提升,并且市面有各种测试工具,测试结果也是大相径庭,比如下面这篇文章: https://www.oschina.net/news/97924/browser ...
- c语言的strcpy函数
strcpy是用于复制字符串的函数 上面这个程序输出的结果为 为什么输出字符串%s时s是abABC,而输出字符%c时s是abABCg呢 因为strcpy函数本身的性质:复制字符串直到’\0’结束符为止 ...
- python中的*args和** kwargs区别
写了几个月的oython了总感觉除了if else for while什么都不太会,看了架构师的代码参数传递总是使用*args,**kwargs,一直搞不太明白,只是模仿着用,最近有时间想系统的学习一 ...
- <表格>
一.列表 信息资源的一种展示形式 二.列表的分类 1.有序列表 <ol> <li>列表项1</li> <li>列表项2</li> </ ...
- RocketMQ中Producer的启动源码分析
RocketMQ中通过DefaultMQProducer创建Producer DefaultMQProducer定义如下: public class DefaultMQProducer extends ...