Python3 Selenium自动化web测试 ==> 第二节 页面元素的定位方法 <上>
前置步骤:
上一篇的Python单元测试框架unittest,我认为相当于功能测试测试用例设计中的用例模板,在自动化用例的设计过程中,可以封装一个模板,在新建用例的时候,把需要测试的步骤添加上去即可;
而现在要做的就是学习如何定位页面元素,告诉系统我要找到什么UI元素,然后才能进一步的采取其他措施;
其实不想写这篇内容,可是又觉得如果去官方文档找信息又效率慢,那么我就将常用的步骤归纳,那样可以快速查阅解决问题。
参考英文官方资料:http://selenium-python.readthedocs.io/locating-elements.html
学习目的:
掌握元素的基础定位方法,常用的八种方法。
正式步骤:
step1: 定位一个或者多个页面元素的方法汇总
①定位单个页面元素的方法
- find_element_by_id(使用id)
- find_element_by_name(使用name属性值)
- find_element_by_xpath(使用XPath)
- find_element_by_link_text(使用显示文本)
- find_element_by_partial_link_text(使用超链接文本)
- find_element_by_tag_name(使用标签名)
- find_element_by_class_name(使用类名)
- find_element_by_css_selector(使用CSS选择器)
② 定位一组页面元素的方法,定位成功过后,会以列表的形式返回所有定位到的页面元素
- find_elements_by_name(使用name属性值)
- find_elements_by_xpath(使用XPath)
- find_elements_by_link_text(使用超链接)
- find_elements_by_partial_link_text(使用部分超链接)
- find_elements_by_tag_name(使用标签名)
- find_elements_by_class_name(使用类名)
- find_elements_by_css_selector(使用CSS选择器)
step2: 以单个页面元素的定位方法示例
以百度首页为测试版本,测试浏览器使用chrome浏览器,相应的驱动放到Python的D:\Python36\Scripts目录下,注意驱动的版本要对应selenium版本
- find_element_by_id
from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(3)
driver.close() - find_element_by_name
from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_name('wd').send_keys('python')
time.sleep(3)
driver.close() - find_element_by_xpath
用chrome浏览器打开百度首页,右键点击搜索框,选择“检查”,或者按F12打开开发者工具,使用chrome浏览器自带的复制xpath工具,来获取xpath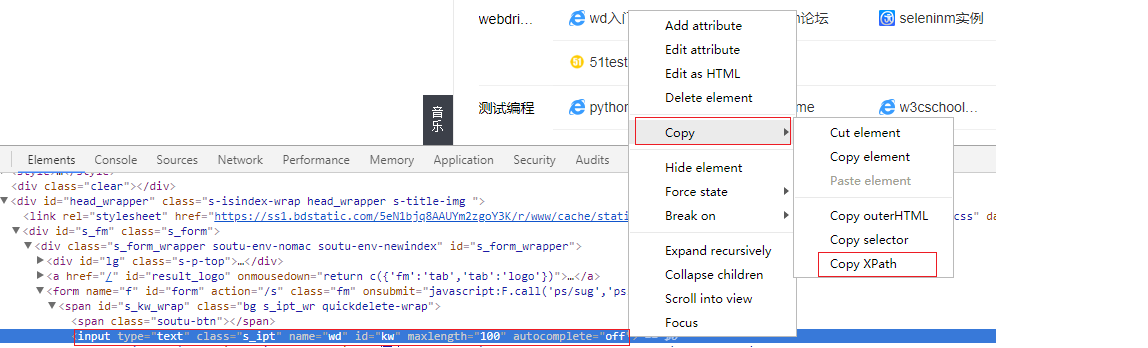
# -*- coding:utf-8 -*- from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python')
time.sleep(3)
driver.close() - find_element_by_css_selector
参考上例,使用开发者工具复制css_selector,需要指出的是,css运行效率比xpath快,但是维护性差,可实际工具中,xpath定位占主导地位,所以优先xpath吧 - find_element_by_link_text
# -*- coding:utf-8 -*- from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_link_text('把百度设为主页').click()
time.sleep(3)
driver.quit() - find_element_by_partial_link_text
# -*- coding:utf-8 -*- from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_partial_link_text('把百度设为').click()
time.sleep(3)
driver.quit() - find_element_by_tag_name
# -*- coding:utf-8 -*- from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
tag = driver.find_element_by_tag_name('title')
if tag:
print('pass')
driver.quit() - find_element_by_class_name
# -*- coding:utf-8 -*- from selenium import webdriver
import time url = 'https://www.baidu.com' driver = webdriver.Chrome()
driver.get(url)
tag = driver.find_element_by_class_name('s_ipt').send_keys('python')
time.sleep(3)
driver.quit()
学习总结:
元素的定位需要自己在实际的工作中总结出常用的定位方法,后续再总结元素的定位方法
Python3 Selenium自动化web测试 ==> 第二节 页面元素的定位方法 <上>的更多相关文章
- Python3 Selenium自动化web测试 ==> 第二节 页面元素的定位方法 -- iframe专题 <下>
学习目的: 掌握iframe矿建的定位,因为前端的iframe框架页面元素信息,大多时候都会带有动态ID,无法重复定位. 场景: 1. iframe切换 查看iframe 切换iframe 多个ifr ...
- Python3 Selenium自动化web测试 ==> 第九节 WebDriver高级应用 -- 操作select 和 alert
学习目的: 掌握页面常规元素的定位方法 场景: 网页正常的select元素下拉框常规方法和select专属方法 正式步骤: step1:常规思路select页面元素定位 处理HTML代码截图 # -* ...
- Python3 Selenium自动化web测试 ==> 第一节 起始点之Python单元测试框架 unittest
前置步骤 Python版本:3.6.4 selenium版本:3.11.0 >>> import selenium >>> help(selenium) IDE:P ...
- Python3 Selenium自动化web测试 ==> 第三节 常用WebDriver API使用示例上(24个API)
前置步骤: 安装selenium,chrome驱动,Python3.6 学习目的: 常见API的使用 涉及的API: step1: 访问一个网址 step2: 网页的前进和后退 step3: 刷新当前 ...
- Python3 Selenium自动化web测试 ==> 第十节 WebDriver高级应用 -- xpath语法
学习目的: xpath定位是针对常规定位方法中,最有效的定位方式. 场景: 页面元素的定位. 正式步骤: step1:常规属性 示例UI 示例UI相关HTML代码 相关代码示例: #通过id定位 dr ...
- Python3 Selenium自动化web测试 ==> 第六节 WebDriver高级应用 -- 操作web页面的滚动条
学习目的: 掌握页面元素定位以外的其他重要知识点. 正式步骤: 测试Python3代码 # -*- coding:utf-8 -*- from selenium import webdriver fr ...
- Python3 Selenium自动化web测试 ==> 第五节 WebDriver高级应用 -- 使用JavaScript操作页面元素
学习目的: 中级水平技术提升 在WebDriver脚本代码中执行JS代码,可以解决某些 .click()方法无法生效等问题 正式步骤: Python3代码如下 # -*- coding:utf-8 - ...
- Python3 Selenium自动化web测试 ==>FAQ:隐式等待和sleep区别
FAQ: 情景1: 设置等待时间 A方法:sleep 线程休眠,但只单次有效,其他操作需要加载等待时间,需要再次添加time.sleep() B方法:implicitly_wait() from se ...
- Python3 Selenium自动化web测试 ==> 第七节 WebDriver高级应用 -- 浮动框中,单击选择某个关键字选项
学习目的: 了解WebDriver的高级应用 正式步骤: 测试Python3代码 # -*- coding:utf-8 -*- from selenium import webdriver from ...
随机推荐
- .NET Core 3来了!如何使用DevExpress WPF创建.NET Core 3应用
DevExpress广泛应用于ECM企业内容管理. 成本管控.进程监督.生产调度,在企业/政务信息化管理中占据一席重要之地.通过DevExpress WPF Controls,您能创建有着强大互动功能 ...
- 2 APIView与序列化组件
1.入门 1.1 参考blog 官方文档:http://www.django-rest-framework.org/tutorial/quickstart/#quickstart yuan的Blog: ...
- mybatis insert into 返回id
<insert id="saveComplaint" useGeneratedKeys="true" parameterType="com.fo ...
- 【Python之路】特别篇--五句话搞定JavaScript作用域
JavaScript的作用域一直以来是前端开发中比较难以理解的知识点,对于JavaScript的作用域主要记住几句话,走遍天下都不怕... 一.“JavaScript中无块级作用域” 在Java或C# ...
- python获取某路径下某扩展名的所有文件名和文件个数
# -*- coding: utf-8 -*- # @Time : 19-1-10 下午10:02 # @Author : Felix Wang import os def get_file_coun ...
- 安装java1.8.0
安装java 1.删除自带jdk rpm -e --nodeps `rpm -qa | grep java` 2.查看yum库中有哪些jdk版本. yum search java | grep jdk ...
- [心得]暑假Day 8
em. 一波爆炸后回到了一个原始位置rank33 最近两场考试没啥状态 总感觉都读不懂题目了 T1 因为有的边要经过两次,不妨把边复制成双倍,那么再去掉2条,如果能一遍把剩下的边过完,也就是成为一笔画 ...
- How to change the button text of <input type=“file” />?
How to change the button text of <input type=“file” />? Simply <label class="btn btn-p ...
- koa 基础(十五)cookie 设置中文
1.app.js // 引入模块 const Koa = require('koa'); const router = require('koa-router')(); /*引入是实例化路由 推荐*/ ...
- 浅析history hack、心血漏洞、CSS欺骗、SQL注入与CSRF攻击
漏洞产生的原因主要有系统机制和编码规范两方面,由于网络协议的开放性,目前以 Web 漏洞居多 关于系统机制漏洞的典型有JavaScript/CSS history hack,而编码规范方面的漏洞典型有 ...