Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目
1、创建项目
创建一个Scrapy项目,并将其命名为“demo”
scrapy startproject demo
cd demo
稍等片刻后,Scrapy为我们生成了一个目录结构:

其中,我们目前需要重点关注三个文件:
- items.py:设置数据存储模板,用于结构化数据,如:Django的Model。
- pipelines.py: 定义数据处理行为,如:一般结构化的数据持久化
- settings.py:配置文件,如:递归的层数、并发数,延迟下载等
1.1、明确爬虫开发的四个步骤
项目已经创建完成了,为了指导接下来的开发,我们必须明确Scrapy爬虫的四个步骤:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
所以,接下来我们需要明确目标。
2、明确目标
以我的博客网站为例,爬取文章的关键信息(标题、摘要、上传时间、阅读数量)

2.1、编写items.py文件
打开 demo 目录下的 items.py。
Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护来减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。
正如下面这样:
import scrapy class DemoItem(scrapy.Item):
# define the fields for your item here like:
postTitle = scrapy.Field()
postDate = scrapy.Field()
postDesc = scrapy.Field()
postNumber = scrapy.Field()
3、制作爬虫
3.1、快速生成爬虫
Scrapy提供了相关命令来帮助我们快速生成爬虫结构,执行下面语句,来生成名为basic的爬虫:
scrapy genspider basic web
它的结构如下:
import scrapy class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
start_urls = ['website'] def parse(self, response):
pass
它确定了三个强制属性和方法:
- name = "basic" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
- allow_domains = [] :是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
- start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
3.2、取数据
我们在前面已经讲解了XPath的基本使用,此处不在赘述。
这一过程,我们需要观察网页源代码。首先每一页的博客是根据日期可以分为几大块,然后每一块内依次排列这每一篇文章的各项信息。
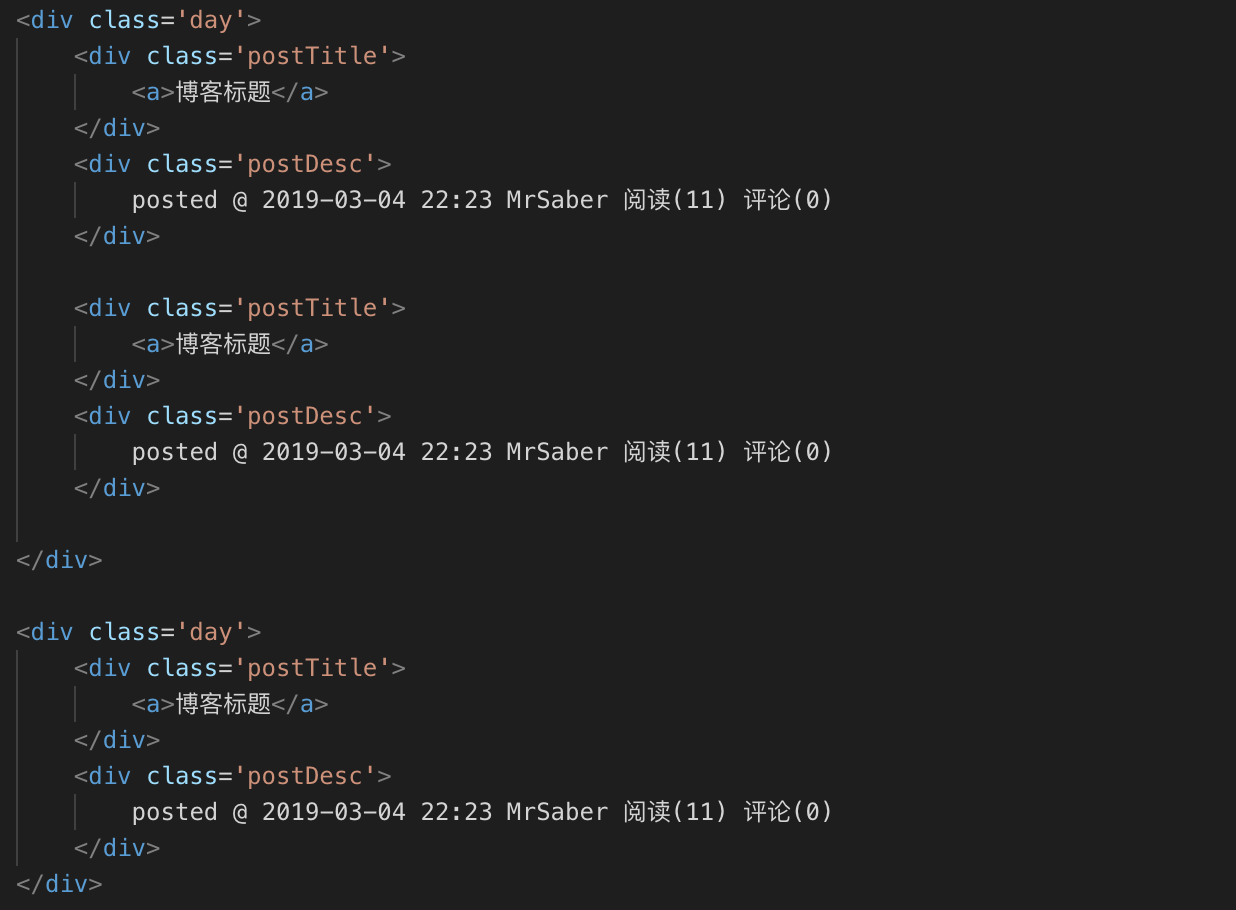
根据抽象出的结构,我们取出数据要爬出的数据:
# -*- coding: utf-8 -*-
import scrapy
import re
from demo.items import DemoItem class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['www.cnblogs.com']
start_urls = ['https://www.cnblogs.com/MrSaver/default.html?page=2'] def parse(self, response):
posts = response.xpath('//div[@class="day"]')
# result = []
for each_day_post in posts:
day_postTitles = each_day_post.xpath('./div[@class="postTitle"]/a[@class="postTitle2"]/text()').extract();
day_postDesc = each_day_post.xpath('./div[@class="postDesc"]/text()').extract();
if (len(day_postTitles) == 1):
tmp = DemoItem()
tmp['postTitle'] = ''.join(day_postTitles)
tmp['postDesc'] = ''.join(day_postDesc)
tmp['postNumber'] = getNumber(tmp['postDesc'])
yield tmp
else:
for i in range(len(day_postTitles)):
tmp = DemoItem()
tmp['postTitle'] = day_postTitles[i]
tmp['postDesc'] = day_postDesc[i]
tmp['postNumber'] = getNumber(tmp['postDesc'])
yield tmp #提取出分页器中所涉及的所有连接喂给爬虫
next_url2 = response.xpath('//div[@id="homepage_top_pager"]/div/a/@href').extract()
if next_url2 is not None:
for n_url in next_url2:
yield response.follow(n_url,callback=self.parse)#scrapy.Request(next_url2, callback=self.parse) def getNumber(txt):
pattern = re.compile(r'阅读\((\d+)\)');
m = pattern.search(txt)
return m.group(1)
4、保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl basic -o items.json
json lines格式,默认为Unicode编码
scrapy crawl basic -o items.jsonl
csv 逗号表达式,可用Excel打开
scrapy crawl basic -o items.csv
xml格式
scrapy crawl basic -o items.xml
4.1、关于中文数据的保存
修改输出编码,在settings.py文件中,添加行
FEED_EXPORT_ENCODING = 'gbk'
5、找到下一页
一个典型的爬虫会向两个方向移动
- 横向:从一个索引页到另一个索引页。我们称之为水平爬取。
- 纵向:从一个索引页到其二级页面并抽取Item。我们称之为垂直爬取。
在水平爬取过程中,我们需要取到下一页的地址,一个简单的Demo如下:
next_url = response.xpath('//div[@id="nav_next_page"]/a/@href').extract_first()
if next_url is not None:
print(next_url)
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
在提取数据之后,parse()方法查找到下一页的链接,使用urljoin()方法构建完整的绝对URL(因为链接可以是相对的)并向下一页生成新请求,将自身注册为回调以处理下一页的数据提取并保持爬网遍历所有页面。
它创建了一种循环,跟随到下一页的所有链接,直到它找不到 ,可用于爬行博客,论坛和其他具有分页的网站。
5.1、创建请求的快捷方式
作为创建Request对象的快捷方式,您可以使用response.follow:
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
与scrapy.Request不同,response.follow直接支持相对URL - 无需调用urljoin。请注意,response.follow只返回一个Request实例,你仍然需要yield这个实例。
Scrapy:学习笔记(2)——Scrapy项目的更多相关文章
- Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath 1.快速开始 XPath是一种可以快速在HTML文档中选择并抽取元素.属性和文本的方法. 在Chrome,打开开发者工具,可以使用$x工具函数来使用XPat ...
- golang学习笔记6 beego项目路由设置
golang学习笔记5 beego项目路由设置 前面我们已经创建了 beego 项目,而且我们也看到它已经运行起来了,那么是如何运行起来的呢?让我们从入口文件先分析起来吧: package main ...
- Docker技术入门与实战 第二版-学习笔记-10-Docker Machine 项目-2-driver
1>使用的driver 1〉generic 使用带有SSH的现有VM/主机创建机器. 如果你使用的是机器不直接支持的provider,或者希望导入现有主机以允许Docker Machine进行管 ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- scrapy学习笔记之hello world
1. 创建项目文档 在目标路径下,打开命令行,使用如下命令创建项目,例如项目名称为 "tutorial": scrapy startproject tutorial - 创建项目时 ...
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- scrapy学习笔记(一)
环境:Windows 7 x64 Python3.7.1 pycharm 一.安装scrapy 1.1linux系统使用:pip install scrapy 1.2Windows系统: pi ...
- Scrapy 学习笔记爬豆瓣 250
Scrapy 是比较上层的库,基于中间层开发,它基于高层,所以它依赖许多其它库.事件驱动的异步技术. Scrapy 爬取网页,以豆瓣电影 Top 250 为例子. 首先打开命令提示符,输入.scrap ...
- 学习笔记:flutter项目搭建(mac版)
什么是flutter Flutter是谷歌的移动UI框架,可以快速在iOS和Android上构建高质量的原生用户界面. Flutter可以与现有的代码一起工作.在全世界,Flutter正在被越来越多的 ...
随机推荐
- Jmeter content-type:multipart/form-data温故
本文讲三种content-type以及在Jmeter中对应的参数输入方式 第一部分:目前工作中涉及到的content-type 有三种: content-type:在Request Headers里, ...
- SpringBoot(零)-- 工程创建
一.约定优于配置 二.快速创建SoringBoot项目 地址:http://start.spring.io/ 三.在步骤二中,创建好了SpringBootDemo 项目,导入Eclipse 自定义ba ...
- docker pull 详解
docker pull 用于从镜像仓库中拉取或更新指定镜像,用法如:docker pull centos ,默认是从 Docker Hub 中拉取镜像 在拉取镜像前,我们可以先配置 docker 加速 ...
- RegisterHotKey注册快捷键
RegisterHotKey的具体使用方使用方法如下: BOOL RegisterHotKey( HWND hWnd, //响应该热键的窗口句柄 Int id, ...
- Android 实现动态匹配输入的内容 AutoCompleteTextView和MultiAutoCompleteTextView
AutoCompleteTextView1.功能:动态匹配输入的内容,如百度搜索引擎当输入文本时可以根据内容显示匹配的热门信息.2.独特属性:android:completionThreshold 设 ...
- iOS-利用插件实时刷新模拟器(提高效率)
解决办法: 1.需要给Xcode安装一个Alcatraz插件 安装完成后:点击window 下面的 package manager 安装我们今天的主角 2. ‘Injection Plugin for ...
- AndroidWear开发之开发环境[前奏]
上篇教程教的是如何下载最新的SDK http://www.cnblogs.com/bvin/p/3811751.html 一.Eclipse下的尝试 之前以为在Eclipse下把SDK,ADT更新一下 ...
- CSS写表格
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content_Type" content ...
- Docker源码分析(六):Docker Daemon网络
1. 前言 Docker作为一个开源的轻量级虚拟化容器引擎技术,已然给云计算领域带来了新的发展模式.Docker借助容器技术彻底释放了轻量级虚拟化技术的威力,让容器的伸缩.应用的运行都变得前所未有的方 ...
- log4j和commons- logging(好文整理转载)
一 :为什么同时使用commons-logging和Log4j?为什么不仅使用其中之一? Commons-loggin的目的是为 “所有的Java日志实现”提供一个统一的接口,它自身的日志功能平常弱( ...