Caffe 议事(三):从零开始搭建 ResNet 之 网络的搭建(中)
上面2个函数定义好了,那么剩下的编写网络就比较容易了,我们在ResNet结构介绍中有一个表,再贴出来:
|
Layer_name |
Output_size |
20-layer ResNet |
|
Conv1 |
32 X 32 |
Kernel_size=3 X 3 Num_output = 16 Stride = 1 Pad = 1 |
|
Conv2_x |
32 X 32 |
{3X3,16; 3X3,16} X 3 |
|
Conv3_x |
16 X 16 |
{3X3,16; 3X3,16} X 3 |
|
Conv4_x |
8 X 8 |
{3X3,16; 3X3,16} X 3 |
|
InnerProduct |
1 X 1 |
Average pooling 10-d fc |
在 Conv1 中对图像做一次卷积即可,Conv2_x 到 Conv4_x 每个都有 3 个 block,并且卷积核数目都是翻倍增加 {16, 32, 64},图像块大小翻倍减小 {32, 16, 8},由于我们输入图像经过剪裁是 28 X 28,实际我们应该是 {28, 14, 7},不过我们暂且就当作输入图像是 32 X 32 大小。
网络中大部分卷积核大小都是 3 X 3,为什么有的卷积核的 pad 是 1,因为如果不加 pad 的话输出的 size 就会比原图像小,因此要加上 pad 这样卷积出来的图片就和原图像 size 一致。Conv1 到 Conv2_x 之间由于数据的通道数都是 16,数据的维度一样,因此输入和输出可以直接加在一起。但是 Con2_x 到 Conv3_x 和 Conv3_x 到 Conv4_x 之间数据的通道数都不一样,而且 output_size 都不一样,不能加在一起,在这里我们采用论文中的 B 方法——对输入数据用 1 X 1 的卷积核映射到与输出数据同样的维度。这就是为什么 ResNet_Block() 里面 projection_stride(映射步长) = 1 时认为输入输出的维度一样,可以直接相加,因此 proj = bottom;而当 projection_stride(映射步长) = 2时认为输入与输出维度不一样,需要用 1 X 1 大小,stride = 2 的卷积核来使得卷积核后的 output_size 是原来的一样。那么在 ResNet() 函数中我们这样编写:
def ResNet(split):
if split == 'train':
...
else:
...
# 每个 ConvX_X 都有 3 个Residual Block
repeat = 3
scale, result = conv_BN_scale_relu(split, data, nout = 16, ks = 3,
stride = 1, pad = 1)
# Conv2_X,输入与输出的数据通道数都是 16, 大小都是 32 x 32,可以直接相加,
# 设置映射步长为 1
for ii in range(repeat):
projection_stride = 1
result = ResNet_block(split, result, nout = 16, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
# Conv3_X
for ii in range(repeat):
if ii == 0:
# 只有在刚开始 conv2_X(16 x 16) 到 conv3_X(8 x 8) 的
# 数据维度不一样,需要映射到相同维度,卷积映射的 stride 为 2
projection_stride = 2
else:
projection_stride = 1
result = ResNet_block(split, result, nout = 32, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
# Conv4_X
for ii in range(repeat):
if ii == 0:
projection_stride = 2
else:
projection_stride = 1
result = ResNet_block(split, result, nout = 64, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
这样,我们就写好了中间的卷积部分,这时候我们最后一层的输出是 64 X 8 X 8(64个通道的 8 X 8 大小的 feature map),最后我们要经过一个 global average pooling,就是把每个 8 X 8 的 feature map 映射成 1 X 1 大小,最后输出为 64 X 1 X 1,再经过输出个数为 10 的InnerProduct 全连接层输出 10 类标签的概率,生成概率的话就用 softmaxWithLoss 层即可。那么整个 ResNet() 的可以写成:
def ResNet(split):
# 写入数据的路径
train_file = this_dir + '/caffe-master/examples/cifar10/cifar10_train_lmdb'
test_file = this_dir + '/caffe-master/examples/cifar10/cifar10_test_lmdb'
mean_file = this_dir + '/caffe-master/examples/cifar10/mean.binaryproto'
# source: 导入的训练数据路径;
# backend: 训练数据的格式;
# ntop: 有多少个输出,这里是 2 个,分别是 n.data 和 n.labels,即训练数据和标签数据,
# 对于 caffe 来说 bottom 是输入,top 是输出
# mirror: 定义是否水平翻转,这里选是
# 如果写是训练网络的 prototext 文件
if split == 'train':
data, labels = L.Data(source = train_file, backend = P.Data.LMDB,
batch_size = 128, ntop = 2,
transform_param = dict(mean_file = mean_file,
crop_size = 28,
mirror = True))
# 如果写的是测试网络的 prototext 文件
# 测试数据不需要水平翻转,你仅仅是用来测试
else:
data, labels = L.Data(source = test_file, backend = P.Data.LMDB,
batch_size = 128, ntop = 2,
transform_param = dict(mean_file = mean_file,
crop_size =28))
# 每个 ConvX_X 都有 3 个Residual Block
repeat = 3
scale, result = conv_BN_scale_relu(split, data, nout = 16, ks = 3,
stride = 1, pad = 1)
# Conv2_X,输入与输出的数据通道数都是 16, 大小都是 32 x 32,可以直接相加,
# 设置映射步长为 1
for ii in range(repeat):
projection_stride = 1
result = ResNet_block(split, result, nout = 16, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
# Conv3_X
for ii in range(repeat):
if ii == 0:
# 只有在刚开始 conv2_X(16 x 16) 到 conv3_X(8 x 8) 的
# 数据维度不一样,需要映射到相同维度,卷积映射的 stride 为 2
projection_stride = 2
else:
projection_stride = 1
result = ResNet_block(split, result, nout = 32, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
# Conv4_X
for ii in range(repeat):
if ii == 0:
projection_stride = 2
else:
projection_stride = 1
result = ResNet_block(split, result, nout = 64, ks = 3, stride = 1,
projection_stride = projection_stride, pad = 1)
pool = L.Pooling(result, pool = P.Pooling.AVE, global_pooling = True)
IP = L.InnerProduct(pool, num_output = 10,
weight_filler = dict(type = 'xavier'),
bias_filler = dict(type = 'constant'))
acc = L.Accuracy(IP, labels)
loss = L.SoftmaxWithLoss(IP, labels)
return to_proto(acc, loss)
运行整个文件后,我们就生成了网络的 train.prototxt 和 test.prototxt 文件了,但是我们怎么知道我们生成的 prototxt 是不是正确的呢?我们可以可视化网络的结构。我们在 ResNet 文件夹下打开终端,输入:
$python ./caffe-master/python/draw_net.py ./res_net_model/train.prototxt ./res_net_model/train.png --rankdir=TB

Fig 14 画网络结构
draw_net.py 至少输入 2 个参数,一个是 prototxt 文件的地址,一个是图像保存的地址,后面的 --rankdir=TB 的意思是网络的结构从上到下 (Top→Bottom) 画出来,类似还有 BT,LR(Left→Right),RL。另外,这里需要说明一下,可能有些高版本的 Caffe 用这个命令会报错,原因是 ‘int’ object has no attribute '_values',关于这个问题的解决,请看这里:https://github.com/BVLC/caffe/issues/5324。
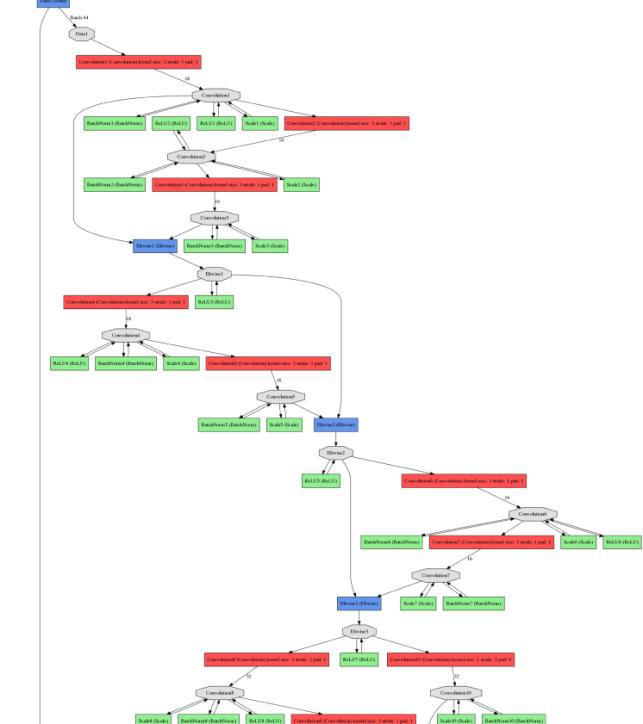
Fig 15 draw_net.py 画出的网络结构图
由于图片太长,我们只显示了网络的部分结构,接下来,我们要生成 solver 的 prototxt。
步骤3:创建 solver 的 prototxt 文件
在 caffe-master/examples/pycaffe 文件夹中有一个 tools.py 文件,这个文件可以生成我们所需要的 solver 的 prototxt 文件,我们在 /ResNet 文件下新建一个 tools 文件夹,再把 tools.py 放入这个文件夹中,由于系统只能找到当前目录下的文件,为了让系统能够找到 tool.py,我们在 init_path.py 中添加下面这句:
tools_path = osp.join(this_dir, 'tools')
add_path(tools_path )
这样我们就把 ResNet/tools 路径添加到系统中,系统就能找到 tools.py 了。那么我们在 mydemo.py 开头,在 import init_path 之后添加 import tools,这样就把 tools.py 导入到了系统中。我们在 mydemo.py 文件最下面的 make_net() 后面添加以下代码:
# 把内容写入 res_net_model 文件夹中的 res_net_solver.prototxt
solver_dir = this_dir + '/res_net_model/res_net_solver.prototxt'
solver_prototxt = tools.CaffeSolver()
solver_prototxt.write(solver_dir)
那么res_net_solver.prototxt里面究竟写了啥?我们先打开ResNet/tools/tools.py。
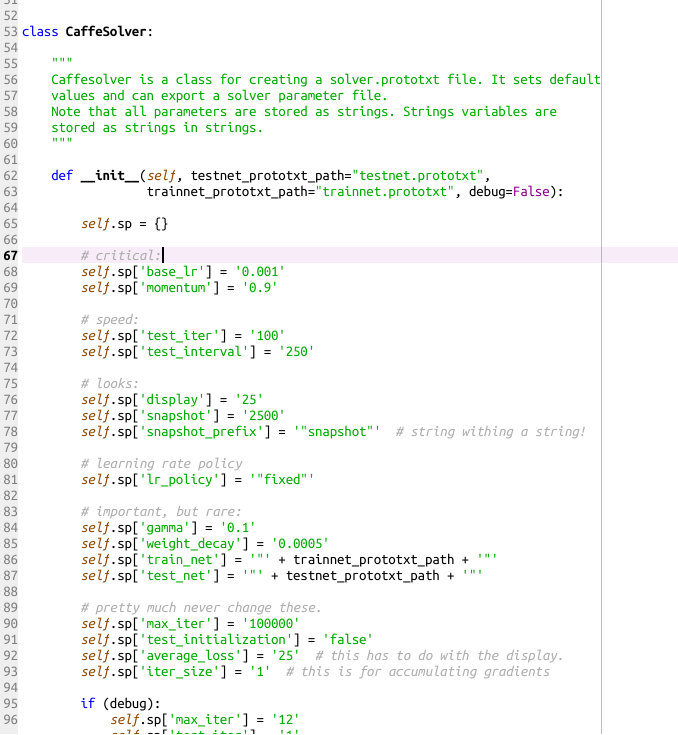
Fig 16 tools.py 截图
里面有各种 solver 参数,论文中的 basb_lr 为 0.1,lr_policy = multistep 等,具体地,我们改成以下的参数:
def __init__(self, testnet_prototxt_path=this_dir+"/../res_net_model/test.prototxt",
trainnet_prototxt_path=this_dir+"/../res_net_model/train.prototxt", debug=False): self.sp = {} # critical:
self.sp['base_lr'] = '0.1'
self.sp['momentum'] = '0.9' # speed:
self.sp['test_iter'] = ''
self.sp['test_interval'] = '' # looks:
self.sp['display'] = ''
self.sp['snapshot'] = ''
self.sp['snapshot_prefix'] = '"/home/your_name/ResNet/res_net_model/snapshot/snapshot"' # string within a string! # learning rate policy
self.sp['lr_policy'] = '"multistep"'
self.sp['step_value'] = ''
self.sp['step_value1'] = '' # important, but rare:
self.sp['gamma'] = '0.1'
self.sp['weight_decay'] = '0.0001'
self.sp['train_net'] = '"' + trainnet_prototxt_path + '"'
self.sp['test_net'] = '"' + testnet_prototxt_path + '"' # pretty much never change these.
self.sp['max_iter'] = ''
self.sp['test_initialization'] = 'false'
self.sp['average_loss'] = '' # this has to do with the display.
self.sp['iter_size'] = '' # this is for accumulating gradients if (debug):
self.sp['max_iter'] = ''
self.sp['test_iter'] = ''
self.sp['test_interval'] = ''
self.sp['display'] = ''
下面解释一下为什么设置这些参数,论文中的学习率为 0.1,对应的我们设置 lr_base = 0.1;在迭代到 32000 次,48000 次的时候学习率依次降低十分之一,那么 lr_policy = multistep (多阶段变化), gamma = 0.1;权重的惩罚系数为 0.0001;batch 的大小是 128,这个我们在 ResNet()函数中已经定义过了,momentum 动量是 0.9。那么其他的就随意了,当然有 GPU 最好用 GPU 跑,CPU 跑得相当慢,其他参数的意思都比较好理解,关于 snapshot 这个的意思是每迭代多少次保存一次模型,因此你可以找到模型迭代过程中各个阶段的参数,训练过程是一个漫长的等待,设置snapshot 这个好处就是你可以继续上次的迭代,万一断电了还是什么的模型也还是都保存了下来。
当然,我们还需要在 tools.py 开头添加:
import os.path as osp
this_dir = osp.dirname(__file__)
这时,在 mydemo.py 文件中,最下行代码应该是这样的:
if __name__ == '__main__':
make_net()
# 定义生成 solver 的路径
solver_dir = this_dir + '/res_net_model/res_net_solver.prototxt'
solver_prototxt = tools.CaffeSolver()
# 把内容写入 res_net_model 文件夹中的 res_net_solver.prototxt
solver_prototxt.write(solver_dir)
这样执行 mydemo.py 后生成 solver 的 prototxt 文件就是按照上面的设置生成的,不过要记得生成后把 prototxt 中 stepvalue1 改成 stepvalue,因为 tool.py 不能存相同名字的参数,不然会覆盖掉。
这样,我们就生成了 solver 的 prototxt 文件。
Caffe 议事(三):从零开始搭建 ResNet 之 网络的搭建(中)的更多相关文章
- Caffe 议事(二):从零开始搭建 ResNet 之 网络的搭建(上)
3.搭建网络: 搭建网络之前,要确保之前编译 caffe 时已经 make pycaffe 了. 步骤1:导入 Caffe 我们首先在 ResNet 文件夹中建立一个 mydemo.py 的文件,本参 ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(三)-使用Travis自动部署Hexo(1)
前言 前面两篇文章介绍了在github上使用hexo搭建博客的基本环境和hexo相关参数设置等. 基于目前,博客基本上是可以完美运行了. 但是,有一点是不太好,就是源码同步问题,如果在不同的电脑上写文 ...
- 第三篇——第二部分——第二文 计划搭建SQL Server镜像
原文:第三篇--第二部分--第二文 计划搭建SQL Server镜像 本文紧跟上一章:SQL Server镜像简介 本文出处:http://blog.csdn.net/dba_huangzj/arti ...
- Retrofit2.0+RxJava+Dragger2实现不一样的Android网络架构搭建
Tamic :csdn http://blog.csdn.net/sk719887916 众所周知,手机APP的核心就在于调用后台接口,展示相关信息,方便我们在手机上就能和外界交互.所以APP中网络框 ...
- 基于Retrofit2.0+RxJava+Dragger2实现不一样的Android网络构架搭建(转载)
转载请注明出处:http://blog.csdn.net/finddreams/article/details/50849385#0-qzone-1-61707-d020d2d2a4e8d1a374a ...
- 跟我学算法-图像识别之图像分类(下)(GoogleNet网络, ResNet残差网络, ResNext网络, CNN设计准则)
1.GoogleNet 网络: Inception V1 - Inception V2 - Inception V3 - Inception V4 1. Inception v1 split - me ...
- 微信小程序从零开始开发步骤(一)搭建开发环境
从零到有写一个小程序系列专题,很早以前就想写来分享,但由于项目一直在进展,没有过多的时间研究技术,现在可以继续分享了. 1:注册 用没有注册过微信公众平台的邮箱注册一个微信公众号, 申请帐号 ,网址: ...
- 使用网络TCP搭建一个简单文件下载器
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 目录 一丶项目介绍 二丶服务器Server 三丶测试TCP server服务器 四丶客户端Client 五丶测试客户端向服务器下载 ...
- 陈云pytorch学习笔记_用50行代码搭建ResNet
import torch as t import torch.nn as nn import torch.nn.functional as F from torchvision import mode ...
随机推荐
- 《DSP using MATLAB》示例Example 9.9
代码: %% ------------------------------------------------------------------------ %% Output Info about ...
- [BZOJ5330][SDOI2018]反回文串
luogu bzoj sol 枚举一个长度为\(n\)为回文串,它的所有循环位移都可以产生贡献. 但是这样算重了.重复的地方在于可能多个回文串循环同构,或者可能有的回文串经过小于\(n\)次循环位移后 ...
- Python threadpool传递参数
threadpool模块是一个很老的实现python线程池的模块,pypi已经建议用multiprocessing代替它了,但是,它使用的便捷性还是征服了一批忠实用户. threadpool模块实现多 ...
- Loararunner录制脚本
LoadRunner录制 1.启动LoadRunner,用管理员方式打开,选择 “Create/Edit Scripts” 2.从这两个方式任意方式打开脚本页面 3.选择协议,这里我们举例子,用“We ...
- Java多线程编程核心技术,第五章
1,Timer timer = new Timer(true)现在是守护进程 2,timer是按照顺的,没有异步 3,timer方法,schedule(TimerTask task, Date fir ...
- linux nginx不区别大小写处理方法
# 把所有的目录及文件名全改成小写,注意之后新增目录及文件只使用小写命名 递归转换目录或文件名方法:python把指定目录下的递归所有目录和文件名转换成小写或大写(http://www.cnblogs ...
- apache-tomcat-7.0.8\bin\tcnative-1.dll: Can't load AMD 64-bit .dll on a IA 32-bit platform
问题: apache-tomcat-7.0.8\bin\tcnative-1.dll: Can't load AMD 64-bit .dll on a IA 32-bit platform 解决:jd ...
- 黄聪:sqlserver 2008修改数据库表的时候错误提示“阻止保存要求重新创建表的更改”
当用户在在SQL Server 2008企业管理器中更改表结构时,必须要先删除原来的表, 然后重新创建新表,才能完成表的更改,如果强行更改会出现以下提示:不允许保存更改 .您所做的更改要求删除并重新创 ...
- bzoj4331: JSOI2012 越狱老虎桥
Description 这里,是美丽的南京:这里,是秀美的进香河:这里是安逸的老虎桥. 如果说进香河的美,美在其秀美的风光,倒不如说是美在了那惬意的南京古典小巷式生活.如果说进香河的迷人,在其淳朴的 ...
- ESN
1.对于一般的硬件设备,ESN是设备序列号,主要用来识别设备,包括未来服务鉴权的需要 2.对于需要license的设备,ESN也是设备序列号的意思,只不过这个序列号可能是根据设备硬件信息算出来的一串字 ...