TensorFlow从0到1之TensorFlow逻辑回归处理MNIST数据集(17)
本节基于回归学习对 MNIST 数据集进行处理,但将添加一些 TensorBoard 总结以便更好地理解 MNIST 数据集。
MNIST由https://www.tensorflow.org/get_started/mnist/beginners提供。
大部分人已经对 MNIST 数据集很熟悉了,它是机器学习的基础,包含手写数字的图像及其标签来说明它是哪个数字。
对于逻辑回归,对输出 y 使用独热(one-hot)编码。因此,有 10 位表示输出,每位的值为 1 或 0,独热意味着对于每个图片的标签 y,10 位中仅有一位的值为 1,其余的为 0。
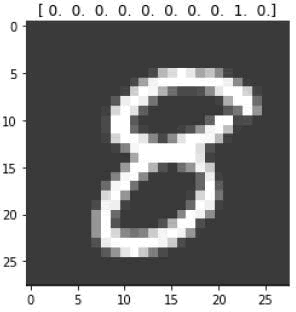
因此,对于手写数字 8 的图像,其编码值为 [0000000010]:
具体做法
- 导入所需的模块:
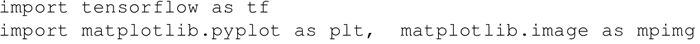
- 可以从模块 input_data 给出的 TensorFlow 示例中获取 MNIST 的输入数据。该 one_hot 标志设置为真,以使用标签的 one_hot 编码。这产生了两个张量,大小为 [55000,784] 的 mnist.train.images 和大小为 [55000,10] 的 mnist.train.labels。mnist.train.images 的每项都是一个范围介于 0 到 1 的像素强度:

- 在 TensorFlow 图中为训练数据集的输入 x 和标签 y 创建占位符:

- 创建学习变量、权重和偏置:
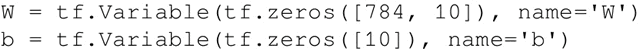
- 创建逻辑回归模型。TensorFlow OP 给出了 name_scope("wx_b"):
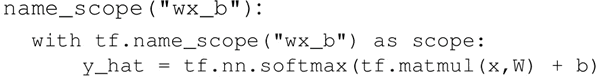
- 训练时添加 summary 操作来收集数据。使用直方图以便看到权重和偏置随时间相对于彼此值的变化关系。可以通过 TensorBoard Histogtam 选项卡看到:
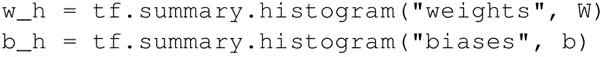
- 定义交叉熵(cross-entropy)和损失(loss)函数,并添加 name scope 和 summary 以实现更好的可视化。使用 scalar summary 来获得随时间变化的损失函数。scalar summary 在 Events 选项卡下可见:

- 采用 TensorFlow GradientDescentOptimizer,学习率为 0.01。为了更好地可视化,定义一个 name_scope:

- 为变量进行初始化:

- 组合所有的 summary 操作:
- 现在,可以定义会话并将所有的 summary 存储在定义的文件夹中:

- 经过 30 个周期,准确率达到了 86.5%;经过 50 个周期,准确率达到了 89.36%;经过 100 个周期,准确率提高到了 90.91 %。
解读分析
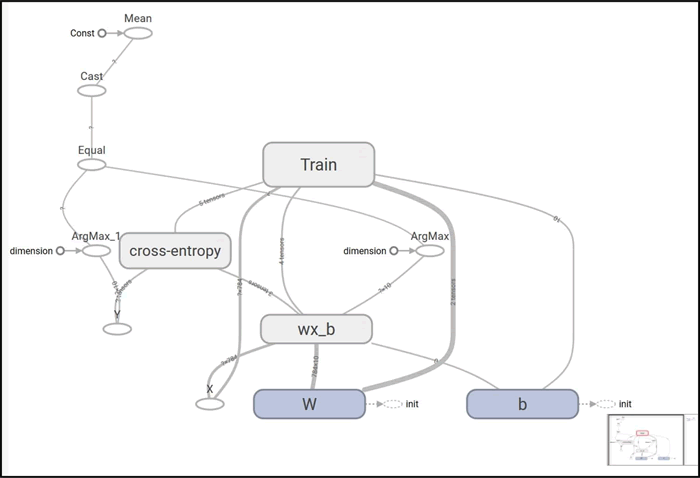
这里使用张量 tensorboard--logdir=garphs 运行 TensorBoard。在浏览器中,导航到网址 localhost:6006 查看 TensorBoard。该模型图如下:
在 Histogram 选项卡下,可以看到权重(weights)和偏置(biases)的直方图:
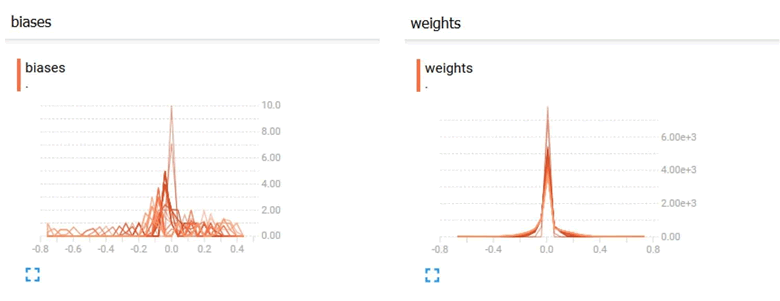
权重和偏置的分布如下:
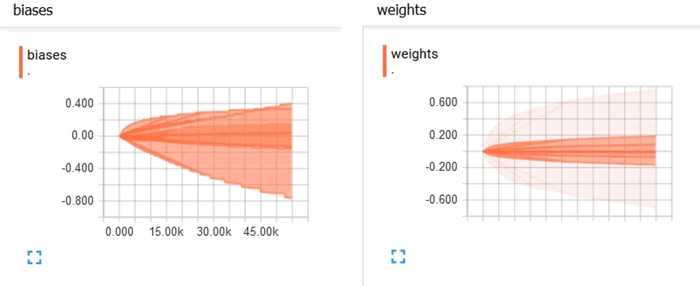
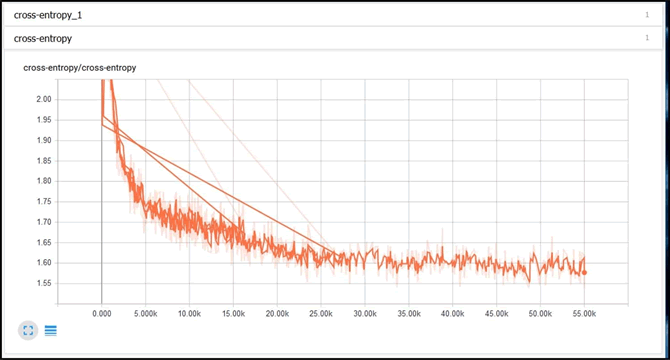
可以看到,随着时间的推移,偏置和权重都发生了变化。在该示例中,根据 TensorBoard 中的分布可知偏置变化的范围更大。在 Events 选项卡下,可以看到 scalar summary,即本示例中的交叉熵。下图显示交叉熵损失随时间不断减少:
TensorFlow从0到1之TensorFlow逻辑回归处理MNIST数据集(17)的更多相关文章
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值.梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降. 在回归中,使用梯度下降来优化损失函数并获得系数.本节将介绍如何使 ...
- TensorFlow从0到1之TensorFlow损失函数(12)
正如前面所讨论的,在回归中定义了损失函数或目标函数,其目的是找到使损失最小化的系数.本节将介绍如何在 TensorFlow 中定义损失函数,并根据问题选择合适的损失函数. 声明一个损失函数需要将系数定 ...
- TensorFlow从0到1之TensorFlow Keras及其用法(25)
Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,你可以编译和拟合模型.之后,它可以用于预测.变量声明.占位 ...
- TensorFlow从0到1之TensorFlow多层感知机函数逼近过程(23)
Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/notes/Sonia_Hornik.pdf)证明 ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
- TensorFlow从0到1之TensorFlow csv文件读取数据(14)
大多数人了解 Pandas 及其在处理大数据文件方面的实用性.TensorFlow 提供了读取这种文件的方法. 前面章节中,介绍了如何在 TensorFlow 中读取文件,本节将重点介绍如何从 CSV ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
随机推荐
- codeforce E. Fire背包
E. Fire time limit per test 2 seconds memory limit per test 256 megabytes input standard input outpu ...
- Python3高级核心技术97讲
可以毫不夸张的说:这门课程是初中级Python开发人员向高级进阶的必学课程 许多Pythoner喜欢追求新的框架,但却不重视Python本身基础知识的学习, 他们不知道的是,语言本身的进阶优先于框架, ...
- DQN(Deep Q-learning)入门教程(一)之强化学习介绍
什么是强化学习? 强化学习(Reinforcement learning,简称RL)是和监督学习,非监督学习并列的第三种机器学习方法,如下图示: 首先让我们举一个小时候的例子: 你现在在家,有两个动作 ...
- 11_ArrayList集合的方法
class Program { static void Main(string[] args) { //数组:长度不可变,类型单一 //ArrayList集合:长度可以任意改变,类型可以不单一 //创 ...
- C# 使用Word模板导出数据
使用NPOI控件导出数据到Word模板中方式: 效果如下: Word模板: 运行结果: 实现如下: Student.cs using System; using System.Collections. ...
- NOI2006 最大获利 洛谷P4174
洛谷题目传送门! 题目描述 新的技术正冲击着手机通讯市场,对于各大运营商来说,这既是机遇,更是挑战.THU 集团旗下的 CS&T 通讯公司在新一代通讯技术血战的前夜,需要做太多的准备工作,仅就 ...
- [JavaWeb基础] 022.线程安全(一)
在我们做客户端程序的时候我们经常会碰到线程安全的问题,比较经典的例子就是模拟局域网聊天.那么线程的安全到底是怎么回事呢,我们经常会听到StringBuffer是线程安全的,StringBuilder不 ...
- 小谢第2问:后端返回为数组list时候,怎么实现转为tree
要求后端返回给我的list时候,在数组中定义有id , parentid, 可以用双重循环的方法,得到tree需要的数据结构,这样得到的数据就可以直接复制给树组件的data啦const oldData ...
- Vue3.0+ElementUI打包之后,为什么部分页面按钮图标找不到
有的页面可以显示这个按钮,有的页面不可以,找了好久,看这都webpack路径问题,到但是我这个没有webpack,没有build文件夹,最后发现是因为没有绑定点击事件 加上这个之后就好了
- Rocket - util - Counters
https://mp.weixin.qq.com/s/q7R2Dn9p9cch_ABN4raReQ 介绍几种计数器的实现,以及其中的一点小细节. 1. ZCounter ...