scala通过尾递归解析提取字段信息
一、背景
获取数据中以“|”作为字段间的分隔符,但个别字段中数据也是以“|”作为分隔符。因此,在字段提取时需要保护数据完整性。
二、实现
1.数据以“|”分隔,可以采用递归方式迭代解析。通过尾递归方式降低运行风险;
2.尾递归中使用模式匹配;
3.解析时,根据separator做遍历,“‘”和“’”(一对引号之间的数据作为一个整体cell),引号前数据位head(即使为空,也可以),cell后的数据由下一次迭代解析,则整个结构为:result+head+cell(引号间的数据)+(head+cell+(head+cell+(...)))
4.默认数据中引号成对出现;
5.具体实现如下:
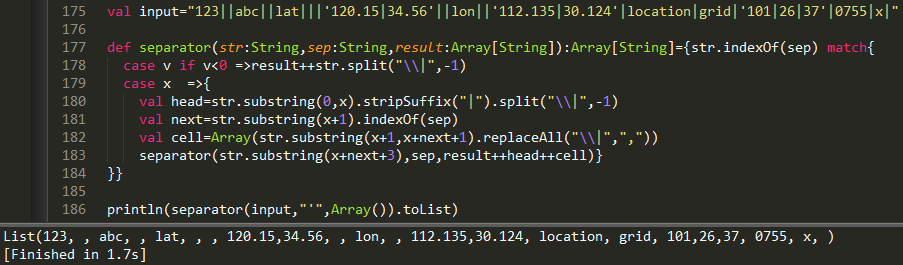
val input="123||abc||lat|||'120.15|34.56'||lon||'112.135|30.124'|location|grid|'101|26|37'|0755|x|"
def separator(str:String,sep:String,result:Array[String]):Array[String]={str.indexOf(sep) match{
case v if v<0 =>result++str.split("\\|",-1)
case x =>{
val head=str.substring(0,x).stripSuffix("|").split("\\|",-1)
val next=str.substring(x+1).indexOf(sep)
val cell=Array(str.substring(x+1,x+next+1).replaceAll("\\|",","))
separator(str.substring(x+next+3),sep,result++head++cell)}
}}
println(separator(input,"'",Array()).toList)
三、总结
1.使用尾递归时,要保证每次迭代要有结果作为下次迭代的输入;
2.substring提取子字符串时为前闭后开;
3.字符串做split时尽量使用index=-1,保证||之间为一个空的数据,但不能丢弃;
4.replaceAll替换字符时,注意".$|()[{^?*+\\"需要做转译;
5.保证|‘不会产生多余空元素,需要对head的字符串做stripSuffix去除动作。
scala通过尾递归解析提取字段信息的更多相关文章
- extract_by_one 根据二维数组中某字段来提取数组信息,查看有无重复信息
public function tt(){ $param = array( array ( 'hykno' => '2222222-CB', 'tcdk_fid' => '458B6D70 ...
- Scala词法文法解析器 (二)分析C++类的声明
最近一直在学习Scala语言,偶然发现其Parser模块功能强大,乃为BNF而设计.啥是BNF,读大学的时候在课本上见过,那时候只觉得这个东西太深奥.没想到所有的计算机语言都是基于BNF而定义的一套规 ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
- python调用mediainfo工具批量提取视频信息
写了2个脚本,分别是v1版本和v2版本 都是python调用mediainfo工具提取视频元数据信息 v1版本是使用pycharm中测试运行的,指定了视频路径 v2版本是最终交付给运营运行的,会把v2 ...
- java 解析http user-agent 信息
解析http user-agent信息,使用uasparser-0.6.1.jar和jregex-1.2_01.jar两个包 import cz.mallat.uasparser.OnlineUpda ...
- 从APNIC提取IP信息
从APNIC提取IP信息 https://blog.csdn.net/nullzeng/article/details/17538009 Apnic介绍简而言之,Apnic是全球5个地区级的Inter ...
- Scala词法文法解析器 (一)解析SparkSQL的BNF文法
平台公式及翻译后的SparkSQL 平台公式的样子如下所示: if (XX1_m001[D003]="邢おb7肮α䵵薇" || XX1_m001[H003]<"2& ...
- tika提取pdf信息异常
org.apache.tika.sax.WriteOutContentHandler$WriteLimitReachedException: Your document contained more ...
- c# 借助cmd命令解析apk文件信息
借助aapt.exe文件 aapt.exe 解析apk包信息cmd命令: aapt dump badging *.apkaapt d badging *.apk >1.txt(保存成1.txt文 ...
随机推荐
- 【pwnable.kr】 [simple login]
Download : http://pwnable.kr/bin/login Running at : nc pwnable.kr 9003 先看看ida里面的逻辑. 比较重要的信息时input变量再 ...
- SQL语句利用日志写shell拿权限
outfile被禁止,或者写入文件被拦截: 在数据库中操作如下:(必须是root权限) show variables like '%general%'; #查看配置 set global genera ...
- (一)微信小程序环境搭建
1 注册 首先 打开(https://mp.weixin.qq.com/)微信公众平台官网 选着 小程序 之后 在新的页面选择 选着前往注册 按照提示注册 注意:个人版和企业版有一定的区别 2 开发者 ...
- CentOS7安装Jenkins与配置
安装 将Jenkins存储库添加到yum repos,并从此安装Jenkins. sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenki ...
- 内存寻址能力与CPU的位宽有关系吗?
答案是:没有关系.CPU的寻址能力与它的地址总线位宽有关,而我们通常说的CPU位宽指的是数据总线位宽,它和地址总线位宽半毛钱关系也没有,自然也与寻址能力无关. 简单的说,CPU位宽指的是一个时钟周期内 ...
- 【pwnable.kr】input
这道题是一道一遍一遍满足程序需求的题. 网上其他的题解都是用了C语言或者python语言的本地调用,我想联系一下pwntools的远程调用就写了下面的脚本, 执行效果可以通过1~4的检测,到最后soc ...
- Python中的numpy函数的使用ones,zeros,eye
在看别人写的代码时,看到的不知道的函数,就在这里记下来. 原文是这样用的: weights = ones((numfeatures,1)) 在python中help(): import numpy a ...
- Springboot Bean循环依赖问题
参考博客原文地址: https://www.jb51.net/article/168398.htm https://www.cnblogs.com/mianteno/p/10692633.html h ...
- Spark 2.x Troubleshooting Guide
IBM在spark summit上分享的内容,包括编译spark源码,运行spark时候常见问题(缺包.OOM.GC问题.hdfs数据分布不均匀等),spark任务堆/thread dump 目录 编 ...
- 二、环境安装:yarn
依赖管理工具安装yarn 可参考前几篇文章 1.必须安装nodejs 注意:安装nodejs稳定版本 2.安装cnpm用cnpm替代npm 地址:http://npm.taobao.org/安装cnp ...