机器学习5- 对数几率回归+Python实现
1. 对数几率回归
考虑二分类任务,其输出标记 \(y \in \{0, 1\}\),记线性回归模型产生的预测值 \(z=\boldsymbol{w}^T\boldsymbol{x} + b\) 是实值,于是我们需要一个将实值 \(z\) 转换为 \(0/1\) 的 \(g^{-}(\cdot)\)。
最理想的单位阶跃函数(unit-step function)
0, & z < 0 \\
0.5, & z = 0 \\
1, & z > 0 \\
\end{cases}
\tag{1.1}
\]
并不是连续函数,因此不能作为 \(g^-(\cdot)\) 。于是我们选用对数几率函数(logistics function)作为单位阶跃函数的替代函数(surrogate function):
\]
如下图所示:

对数几率函数是 Sigmoid 函数(即形似 S 的函数)的一种。
将对数几率函数作为 \(g^-(\cdot)\) 得到
\]
\]
若将 \(y\) 视为样本 \(\boldsymbol{x}\) 为正例的可能性,则 \(1-y\) 是其为反例的可能性,两者的比值为
\]
称为几率(odds),反映了 \(\boldsymbol{x}\) 作为正例的相对可能性。对几率取对数得到对数几率(log odds,或 logit):
\]
所以,式 (1.3) 实际上是用线性回归模型的预测结果取逼近真实标记的对数几率,因此其对应的模型又称为对数几率回归(logistic regression, 或 logit regression)。
这种分类学习方法直接对分类可能性进行建模,无需事先假设数据分布,避免了假设分布不准确带来的问题;
它能得到近似概率预测,这对需要利用概率辅助决策的任务很有用;
对率函数是任意阶可导的凸函数,有很好的数学性质,许多数值优化算法都可直接用于求解最优解。
1.1 求解 ω 和 b
将式 (1.3) 中的 \(y\) 视为类后验概率估计 \(p(y = 1 | \boldsymbol{x})\),则式 (1.4) 可重写为
\]
有
\]
\]
通过极大似然法(maximum likelihood method)来估计 \(\boldsymbol{w}\) 和 \(b\) 。
给定数据集 \(\{(\boldsymbol{x}_i, y_i)\}^m_{i=1}\),对率回归模型最大化对数似然(log-likelihood):
\]
即令每个样本属于其真实标记的概率越大越好。
令 \(\boldsymbol{\beta} = (\boldsymbol{w};b)\),\(\hat{\boldsymbol{x}} = (\boldsymbol{x};1)\),则 \(\boldsymbol{w}^T\boldsymbol{x} + b\) 可简写为 \(\boldsymbol{\beta}^T\hat{\boldsymbol{x}}\)。再令 \(p_1(\hat{\boldsymbol{x}};\boldsymbol{\beta}) = p(y=1|\hat{\boldsymbol{x}};\boldsymbol{\beta})\),\(p_0(\hat{\boldsymbol{x}};\boldsymbol{\beta}) = p(y=0|\hat{\boldsymbol{x}};\boldsymbol{\beta}) = 1-p_1(\hat{\boldsymbol{x}};\boldsymbol{\beta})\) 。则式 (1.10) 可简写为:
\]
将式 (1.11) 带入 (1.10),并根据式 (1.8) 和 (1.9) 可知,最大化式 (1.10) 等价于最小化
\]
式 (1.12) 是关于 \(\boldsymbol{\beta}\) 的高阶可导凸函数,根据凸优化理论,经典的数值优化算法如梯度下降法(gradient descent method)、牛顿法(Newton method)等都可求得其最优解,于是得到:
\]
以牛顿法为例, 其第 \(t+1\) 轮迭代解的更新公式为:
\]
其中关于 \(\boldsymbol{\beta}\) 的一阶、二阶导数分别为:
\]
\]
2. 对数几率回归进行垃圾邮件分类
2.1 垃圾邮件分类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.feature_extraction.text import TfidfVectorizer
from matplotlib.font_manager import FontProperties
df = pd.read_csv("SMSSpamCollection", delimiter='\t', header=None)
df.head()

print("spam 数量: ", df[df[0] == 'spam'][0].count())
print("ham 数量: ", df[df[0] == 'ham'][0].count())
spam 数量: 747
ham 数量: 4825
X_train_raw, X_test_raw, y_train, y_test = train_test_split(df[1], df[0])
# 计算TF-IDF权重
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
# 建立模型
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
y_preds = classifier.predict(X_test)
for i, y_pred in enumerate(y_preds[-10:]):
print("预测类型: %s -- 信息: %s" % (y_pred, X_test_raw.iloc[i]))
预测类型: ham -- 信息: Aight no rush, I'll ask jay
预测类型: ham -- 信息: Sos! Any amount i can get pls.
预测类型: ham -- 信息: You unbelievable faglord
预测类型: ham -- 信息: Carlos'll be here in a minute if you still need to buy
预测类型: spam -- 信息: Meet after lunch la...
预测类型: ham -- 信息: Hey tmr maybe can meet you at yck
预测类型: ham -- 信息: I'm on da bus going home...
预测类型: ham -- 信息: O was not into fps then.
预测类型: ham -- 信息: Yes..he is really great..bhaji told kallis best cricketer after sachin in world:).very tough to get out.
预测类型: ham -- 信息: Did you show him and wot did he say or could u not c him 4 dust?
2.2 模型评估
混淆举证
test = y_test
test[test == "ham"] = 0
test[test == "spam"] = 1
pred = y_preds
pred[pred == "ham"] = 0
pred[pred == "spam"] = 1
from sklearn.metrics import confusion_matrix
test = test.astype('int')
pred = pred.astype('int')
confusion_matrix = confusion_matrix(test.values, pred)
print(confusion_matrix)
plt.matshow(confusion_matrix)
font = FontProperties(fname=r"/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc")
plt.title(' 混淆矩阵',fontproperties=font)
plt.colorbar()
plt.ylabel(' 实际类型',fontproperties=font)
plt.xlabel(' 预测类型',fontproperties=font)
plt.show()
[[1191 1]
[ 50 151]]

精度
from sklearn.metrics import accuracy_score
print(accuracy_score(test.values, pred))
0.9633883704235463
交叉验证精度
df = pd.read_csv("sms.csv")
df.head()

X_train_raw, X_test_raw, y_train, y_test = train_test_split(df['message'], df['label'])
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
scores = cross_val_score(classifier, X_train, y_train, cv=5)
print(' 精度:',np.mean(scores), scores)
精度: 0.9562200956937799 [0.94736842 0.95933014 0.95574163 0.95574163 0.96291866]
准确率召回率
precisions = cross_val_score(classifier, X_train, y_train, cv=5, scoring='precision')
print('准确率:', np.mean(precisions), precisions)
recalls = cross_val_score(classifier, X_train, y_train, cv=5, scoring='recall')
print('召回率:', np.mean(recalls), recalls)
准确率: 0.9920944081237428 [0.98550725 1. 1. 0.98701299 0.98795181]
召回率: 0.6778796653796653 [0.61261261 0.69642857 0.66964286 0.67857143 0.73214286]
F1 度量
f1s = cross_val_score(classifier, X_train, y_train, cv=5, scoring='f1')
print(' 综合评价指标:', np.mean(f1s), f1s)
综合评价指标: 0.8048011339652206 [0.75555556 0.82105263 0.80213904 0.8042328 0.84102564]
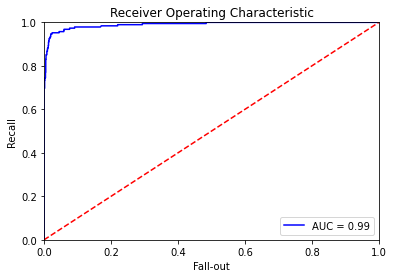
ROC AUC
from sklearn.metrics import roc_curve, auc
predictions = classifier.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test, predictions[:, 1])
roc_auc = auc(false_positive_rate, recall)
plt.title('Receiver Operating Characteristic')
plt.plot(false_positive_rate, recall, 'b', label='AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
机器学习5- 对数几率回归+Python实现的更多相关文章
- 对数几率回归(逻辑回归)原理与Python实现
目录 一.对数几率和对数几率回归 二.Sigmoid函数 三.极大似然法 四.梯度下降法 四.Python实现 一.对数几率和对数几率回归 在对数几率回归中,我们将样本的模型输出\(y^*\)定义 ...
- 机器学习总结-LR(对数几率回归)
LR(对数几率回归) 函数为\(y=f(x)=\frac{1}{1+e^{-(w^{T}x+b)}}\). 由于输出的是概率值\(p(y=1|x)=\frac{e^{w^{T}x+b}}{1+e^{w ...
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 学习笔记TF009:对数几率回归
logistic函数,也称sigmoid函数,概率分布函数.给定特定输入,计算输出"success"的概率,对回题回答"Yes"的概率.接受单个输入.多维数据或 ...
- 机器学习-对数logistics回归
今天 学习了对数几率回归,学的不是很明白x1*theat1+x2*theat2...=y 对于最终的求解参数编程还是不太会,但是也大致搞明白了,对数几率回归是由于线性回归函数的结果并不是我们想要的,我 ...
- 机器学习总结之逻辑回归Logistic Regression
机器学习总结之逻辑回归Logistic Regression 逻辑回归logistic regression,虽然名字是回归,但是实际上它是处理分类问题的算法.简单的说回归问题和分类问题如下: 回归问 ...
- 机器学习实战之Logistic回归
Logistic回归一.概述 1. Logistic Regression 1.1 线性回归 1.2 Sigmoid函数 1.3 逻辑回归 1.4 LR 与线性回归的区别 2. LR的损失函数 3. ...
- 机器学习(4)之Logistic回归
机器学习(4)之Logistic回归 1. 算法推导 与之前学过的梯度下降等不同,Logistic回归是一类分类问题,而前者是回归问题.回归问题中,尝试预测的变量y是连续的变量,而在分类问题中,y是一 ...
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
原文链接:https://developers.google.com/machine-learning/crash-course/logistic-regression/ 逻辑回归会生成一个介于 0 ...
随机推荐
- (note)从小白到产品经理之路
学习了云课堂的产品课程,整理出部分笔记,以作备用参考,方便实际运用过程中查看巩固. 1.产品工具:Axure.mindmanager.viso.办公软件wps 2.产品人需要具备的品格 富有同理心,习 ...
- SpringCloud配置中心config
1,配置中心可以用zookeeper来实现,也可以用apllo 来实现,springcloud 也自带了配置中心config Apollo 实现分布式配置中心 zookeeper:实现分布式配置中心, ...
- Spring中应用的那些设计模式
设计模式作为工作学习中的枕边书,却时常处于勤说不用的尴尬境地,也不是我们时常忘记,只是一直没有记忆. 今天,我们就设计模式的内在价值做一番探讨,并以spring为例进行讲解,只有领略了其设计的思想理念 ...
- Oracle, Mysql及Sql Server的区别
从事技术工作以来,算是把关系型数据库SQL Server,Oracle, MySQL均用了一遍,本文参考网友的梳理,做一下知识总结. 源头说起 Oracle:中文译作甲骨文,这是一家传奇的公司,有一个 ...
- Java递归练习201908091049
package org.jimmy.autofactory.test; public class TestRecursive20190809 { public static void main(Str ...
- 《Three.js 入门指南》2.4.1- 照相机 - 透视投影demo
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Win32程序:与"LPCWSTR"类型的形参不兼容
出现该问题的原因是通常手动输入的字符串都是LPCSTR类型的, 解决办法如下: 在工程处右键,属性-常规-字符集,将Unicode字符集改为为多字节字符集,应用并确认即可. 字符串常量报错: 在常 ...
- day 1 硬件组成概念及介绍笔记
一.服务器的种类: 硬件服务器: 1.机架式服务器 2.刀片式服务器 3.塔式服务器 虚拟服务器: 阿里云 aws 腾讯云 二.详细硬件组成: 1.电源 ----心脏(供电) 冗余特性 ups ...
- 1058 A+B in Hogwarts (20分)(水)
If you are a fan of Harry Potter, you would know the world of magic has its own currency system -- a ...
- 1031 Hello World for U (20分)
Given any string of N (≥) characters, you are asked to form the characters into the shape of U. For ...